
電信公司(telcos)正在利用生成人工智能,通過自動化流程、改善客戶體驗和優化網絡運營來提高員工生產力。
Amdocs 是一家領先的通信和媒體提供商軟件和服務提供商,為電信公司構建了 amAIz,這是一個特定領域的生成人工智能平臺,是一個開放、安全、經濟高效且與大型語言模型(LLM)無關的框架。Amdocs 正在利用 NVIDIA DGX Cloud 和 NVIDIA AI Enterprise 軟件,提供基于商用 LLM 的解決方案,以及適用于特定領域的模型,使服務提供商能夠構建和部署企業級生成人工智能應用程序。
Amdocs 也在使用 NVIDIA NIM,一組易于使用的推理微服務,旨在加速生成型人工智能在企業中的大規模部署。該多功能微服務支持來自開放社區模型和 NVIDIA AI Foundation 模型的 NVIDIA API 產品目錄 中的模型,以及自定義的人工智能模型。NIM 旨在以最高吞吐量和最低延遲促進無縫人工智能推理,同時保持預測的高準確性。
客戶計費用例
在電信公司聯絡中心,計費查詢代表了大量的客戶電話。他們尋求解釋,因為各種操作可能會影響他們的賬單,包括客戶的移動計劃、促銷期結束或意外收費。
Amdocs 正在開發一種基于 LLM 的解決方案,該解決方案旨在通過對賬單問題提供即時準確的解釋來幫助客戶。該解決方案旨在減少客戶服務代理的工作量,使他們能夠專注于更復雜的任務。
圖 1 顯示了從數據收集和準備到 LLM 微調,再到參數有效技術再到評估的整個過程。
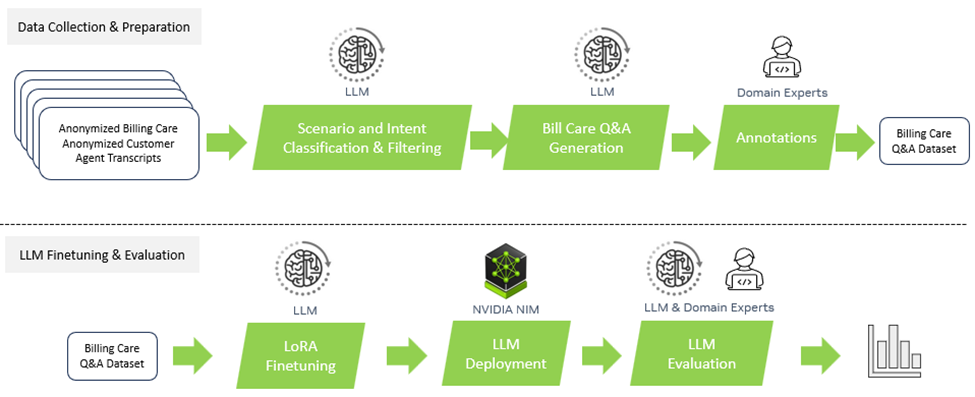
數據收集和準備?
為了解決這個問題,他們從匿名的通話記錄和賬單中創建了一個新的數據集,由電信客戶服務專家標記。該數據集包含數百個注釋問題和答案,這些問題和答案被分類到相關場景中。大部分數據用于微調,性能在一個小測試集(幾十個樣本)上報告。
表 1 顯示了所收集數據的一個示例。該問題與計費更改有關,注釋的答案基于歷史客戶賬單。
| 身份證件 | 相關法案 | 帳戶 ID | 注釋性問題 | 最終答案(“標簽”) | 注釋場景 |
| id_1 | [‘id_12345.2311’,’id_1345.2310’] | id_12345 | 我注意到最近我的賬單增加了。你能解釋一下為什么會發生這種事嗎? | 您的賬單已從 10 月的 100.02 美元增加到 11 月的 115.02 美元,主要是由于您的互聯網服務的促銷積分到期。以下是詳細信息: –您的互聯網信用額度從 10 月的-75.00 美元降至 11 月的-60.00 美元 |
促銷已過期 |
在這個過程中,Amdocs 使用 OpenAI GPT-4 LLM 作為一種工具來過濾轉錄本并將轉錄本分類到場景中。然后,LLM 被用于生成潛在的問答對,這些問答對被領域專家重新訪問和標記。
數據格式和提示工程?
作為基線,Amdocs 使用 Llama2-7b-chat、Llama2-13b-chat 和 Mixtral-8x7b LLM 來增強具有意向分類和賬單問答功能的客戶服務聊天機器人。Amdocs 設計了帶有說明的提示,其中包括目標賬單(原始 XML 格式的連續一到兩個計費月)和問題。
基線 LLM 和零樣本或少熱點推理的初始實驗表現不佳,主要是由于從客戶賬單中提取相關信息的復雜性。此外,原始 XML 格式需要詳細說明 LLM 的計費格式。因此,由于某些 LLM(例如,Llama2 的 4K 代幣)的最大上下文長度的限制,Amdocs 在將賬單和指令納入提示中時面臨挑戰。
為了適應上下文窗口,Amdocs 的第一項工作是減少提示中的計費格式說明。圖 2 顯示了使用 Llama2 代幣化器,重新格式化的紙幣從 3909 個代幣減少到 1153 個代幣的平均代幣減少情況。
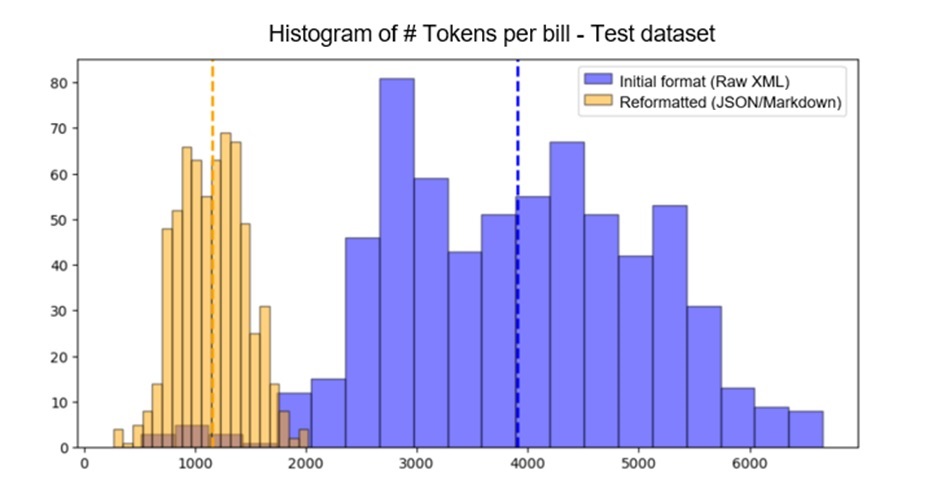
NVIDIA DGX Cloud 上的 LLM 微調?
由于注釋數據量有限,Amdocs 探索了參數有效微調(PEFT)方法,如低秩自適應(LoRA)。他們用兩種基礎 LLM 架構(Llama2 和 Mixtral)進行了幾次微調實驗,探索了一到兩個時期的幾個 LoRA 超參數。
Amdocs 的實驗是在 NVIDIA DGX Cloud 上進行的,這是一個面向開發者的端到端人工智能平臺,提供基于最新 NVIDIA 架構的可擴展容量,并與世界領先的云服務提供商共同設計。Amdocs 使用的 NVIDIA DGX Cloud 實例包含以下組件:
- 8x NVIDIA A100 80GB Tensor Core GPU
- 88 個 CPU 核心
- 1 TB 系統內存
在多 GPU 設置上執行微調周期,導致每個周期不到一個小時。
使用 NVIDIA NIM 部署 LLM
NVIDIA NIM 基于 NVIDIA Triton 推理服務器 和使用 TensorRT-LLM 對 NVIDIA GPU 上的 LLM 推斷進行優化。NIM 通過預先優化的推理容器實現了無縫的人工智能推理,這些容器開箱即用,在加速的基礎設施上提供盡可能好的延遲和吞吐量,同時保持預測的準確性。無論是在本地還是在云中,NIM 都提供了以下優勢:
- 簡化人工智能應用程序開發
- 為最新生成的人工智能模型預先配置的容器
- 通過服務級別協議提供企業支持,并定期更新 CVE 的安全性
- 支持最新的社區最先進的 LLM
- 成本效益和性能
對于該應用程序,Amdocs 使用自托管的 NVIDIA NIM 實例來部署經過微調的 LLM。他們公開了類似 OpenAI 的 API 端點,為他們的客戶端應用程序啟用了統一的解決方案,該解決方案使用 LangChain 的 ChatOpenAI 客戶端。
在微調探索過程中,Amdocs 創建了一個流程,通過 NIM 自動部署 LoRA 微調檢查點。對于微調后的 Mixtral-8x7B 模型,該過程花費了大約 20 分鐘。
結果?
Amdocs 已經看到了這一過程的多重效率。
精度提高:通過與 NVIDIA 的合作,我們顯著提高了人工智能生成響應的準確性,準確性提高了 30%。這種類型的改進對于電信行業的廣泛采用和滿足直接面向消費者的人工智能服務的需求至關重要。
使用 NVIDIA NIM,Amdocs 在成本和延遲方面實現了性能改進。
降低了運營成本:Amdocs 在 NVIDIA 基礎設施上的電信檢索增強生成(RAG)使部署用例所消耗的令牌在數據預處理和推理方面分別降低了 60% 和 40%,從而以顯著更低的成本提供了相同水平的準確性。
延遲增強:該協作成功地將查詢延遲減少了約 80%,從而確保最終用戶體驗到近乎實時的響應速度。此項加速增強將對商業、醫療、運營等領域的用戶體驗產生積極影響。
LLM 精度評估
為了在微調階段評估測試數據集上跨模型和提示的性能,Amdocs 使用了圖 3 中的高級流程。

對于每個實驗,Amdocs 首先在測試數據集上生成 LLM 輸出預測。
然后,使用外部 LLM-as-a-Juage 來評估預測,提供準確性和相關性的指標。對符合預定義標準的實驗進行自動回歸測試,以驗證預測細節的準確性。由此得出的分數是多種指標的混合,包括以下內容:
- F1 成績
- 無幻覺指標
- 準確結論指標
- 回答相關性
- 對話框一致性
- 無回退指示器
- 完整性
- 毒性
最后,手動評估性能最佳的模型,以確認總體準確性。這一過程確保了微調后的 LLM 既有效又可靠。
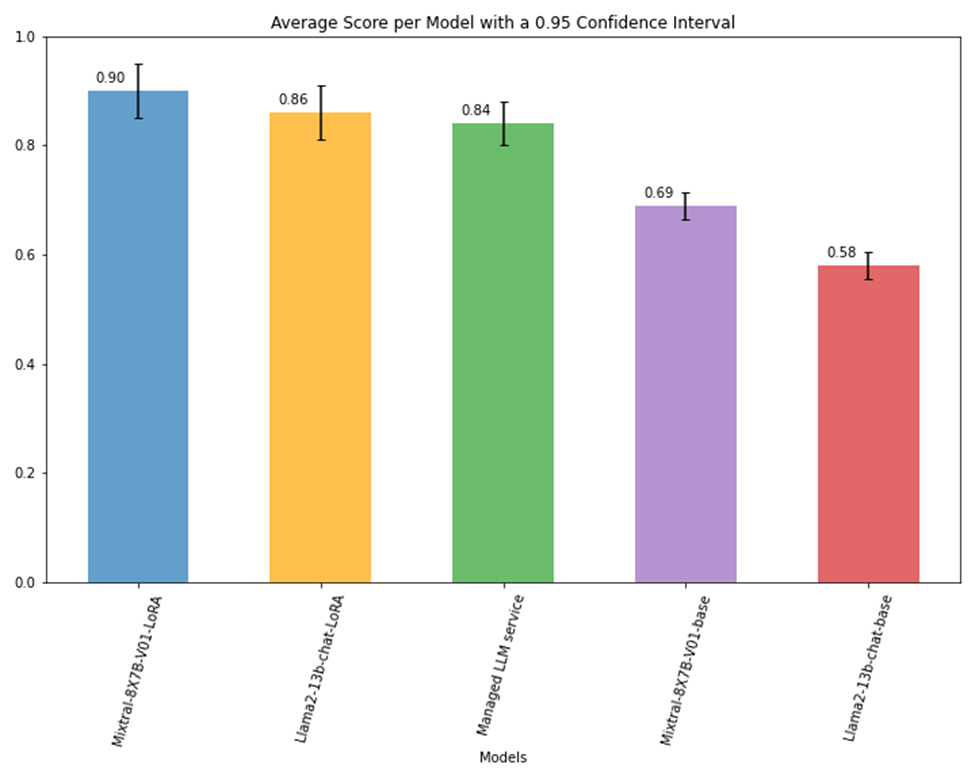
圖 4 顯示了不同 LLM 的總體準確度得分。Amdocs 觀察到,與基礎版本相比,Mixtral-8x7B 和 Llama2-13b-cat 的 LoRA 微調版本的準確度分別提高了 20-30%。與托管 LLM 服務相比,結果還顯示準確率提高了 6%。
代幣消費?
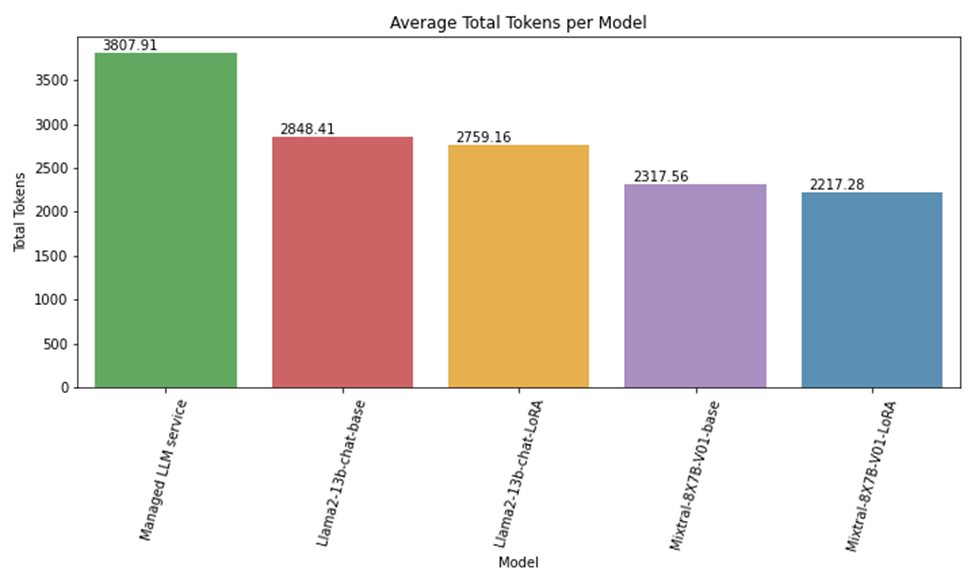
重新格式化計費數據導致輸入令牌減少了 60%。雖然經過微調的 LLM 產生了相當或更好的性能,但這些模型也使輸入代幣額外節省了約 40%。這歸因于最小化提示指令的域自定義。
圖 5 顯示了 Mixtral-8x7B、Llama2-13b 和托管 LLM 服務的令牌消耗之間的比較。輸入令牌數量的差異主要是由于托管 LLM 服務在任務中執行良好所需的詳細指令。對于領域定制的 Llama2 和 Mixtral-8x7B 模型,減少是由于持續的上下文格式改進。
LLM 延遲?
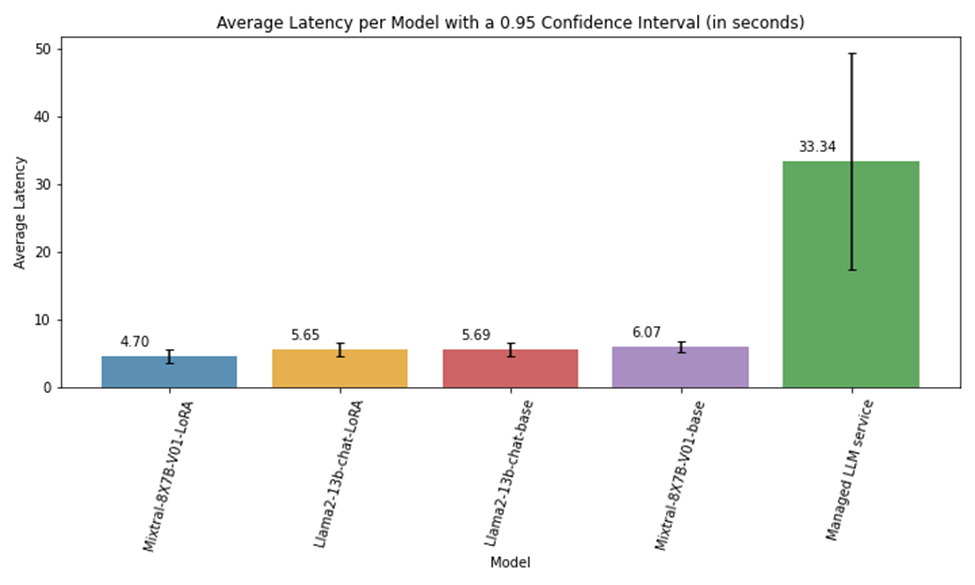
在使用 NVIDIA NIM 對 A100 80GB GPU 上部署的模型進行評估期間,Amdocs 觀察到平均推理速度比領先的最先進的托管 LLM 服務快 4-6 倍,約 80%。
圖 6 顯示了使用單個 LLM 調用執行的延遲實驗,并計算了整個生成周期的平均延遲。所有 NIM 都是在 DGX Cloud A100 供電的實例上遠程部署的。Llama2-13b 型號部署在一個 GPU 上,而 Mixtral-8x7B 部署在兩個 GPU 上。當使用自托管端點時,響應延遲更加一致,如圖 6 所示的 0.95 置信區間線所示。
結論和下一步行動?
NVIDIA NIM 推理微服務改善了延遲,使 Amdocs 應用程序中的處理速度更快。通過優化數據格式和微調 LLM,Amdocs 提高了其計費問答系統的準確性,同時顯著降低了成本。在整個過程中,Amdocs 面臨著不同的挑戰,需要創造性的數據重新格式化、及時的工程設計和特定于模型的定制。定義一個明確的模型評估策略和嚴格的測試是他們成功的關鍵。
Amdocs 正在采取下一步行動,通過使用 Multi-LoRA 為不同的應用程序創建模型自定義,這是一種能夠在推理過程中動態加載多個模型自適應的技術。這種方法優化了內存使用,因為只有基本模型是一致加載的,而模型層自適應是根據需要動態加載的。
通過與 NVIDIA 的合作,Amdocs 啟動了一項戰略,將生成人工智能集成到其核心產品組合中。該戰略從確定應用領域開始,通過重新設計用戶體驗,使生成人工智能功能更加用戶友好,并優先考慮快速工程。為進一步提高準確性并優化生成人工智能訓練和推理的成本,Amdocs 將繼續使用 NVIDIA DGX Cloud 和 NVIDIA AI Enterprise 軟件,以電信公司分類法定制大型語言模型(LLM)。
Amdocs 計劃在多個戰略方向上繼續將生成人工智能集成到 amAIz 平臺中。
- 使用人工智能驅動的語言和情感分析增強客戶查詢路由。
- 增強其人工智能解決方案的推理能力,以提供針對客戶特定需求的建議。
- 解決需要廣泛領域知識、多模式和多步驟解決方案的復雜場景,如網絡診斷和優化。
這些戰略將使運營和創新更加高效和有效。
欲了解更多信息,請觀看點播 “如果?”的力量:利用 Generative AI 實現商業價值 的 GTC 會議錄像。
現在開始使用 NVIDIA NIM,借助 NVIDIA 優化和加速的 API 運行和部署最新的社區構建的生成人工智能模型。
?






