本文將深入分析 DICOM 醫學影像的解碼功能。AWS HealthImaging 利用 NVIDIA 的 nvJPEG2000 庫 來實現此功能。我們將深入探討圖像解碼的復雜性,并介紹 AWS HealthImaging,以及 GPU 加速解碼解決方案帶來的進步。
通過 GPU 加速的 nvJPEG2000 庫,踏上在 AWS HealthImaging 中提高吞吐量和降低醫療影像解密成本的旅程,代表著在云環境中實現運營效率的一大步。這些創新有望節省大量成本,預測表明此類工作負載的潛在成本降低總計數億美元。
JPEG 2000
JPEG 2000 的實施面臨著顯著的複雜性,因為早期遇到的互操作性問題阻礙了跨不同系統的無縫整合。這種複雜性導致廣泛採用的阻礙。然而,高吞吐量 JPEG 2000 (HTJ2K) 編碼系統的出現代表著圖像壓縮技術的重大進展。JPEG 2000 標準的第 15 部分概述的 HTJ2K 利用更有效的 FBCOT (優化截斷的快速塊編碼) 替代原始塊編碼算法 EBCOT (優化截斷的嵌入式塊編碼),以提高吞吐量。
這項新標準解決了解碼速度的限制,并為 JPEG 2000 在醫學影像領域的更廣泛采用打開了大門。HTJ2K 同時支持無損壓縮和無損壓縮,在保留關鍵醫療細節和實現高效存儲之間實現了平衡。具有任意寬度和高度的灰度和彩色圖像,以及每個通道多達 16 位的支持,展示了 HTJ2K 的適應性。新標準對分解級別沒有限制,支持廣泛的選項。
nvJPEG2000 庫?
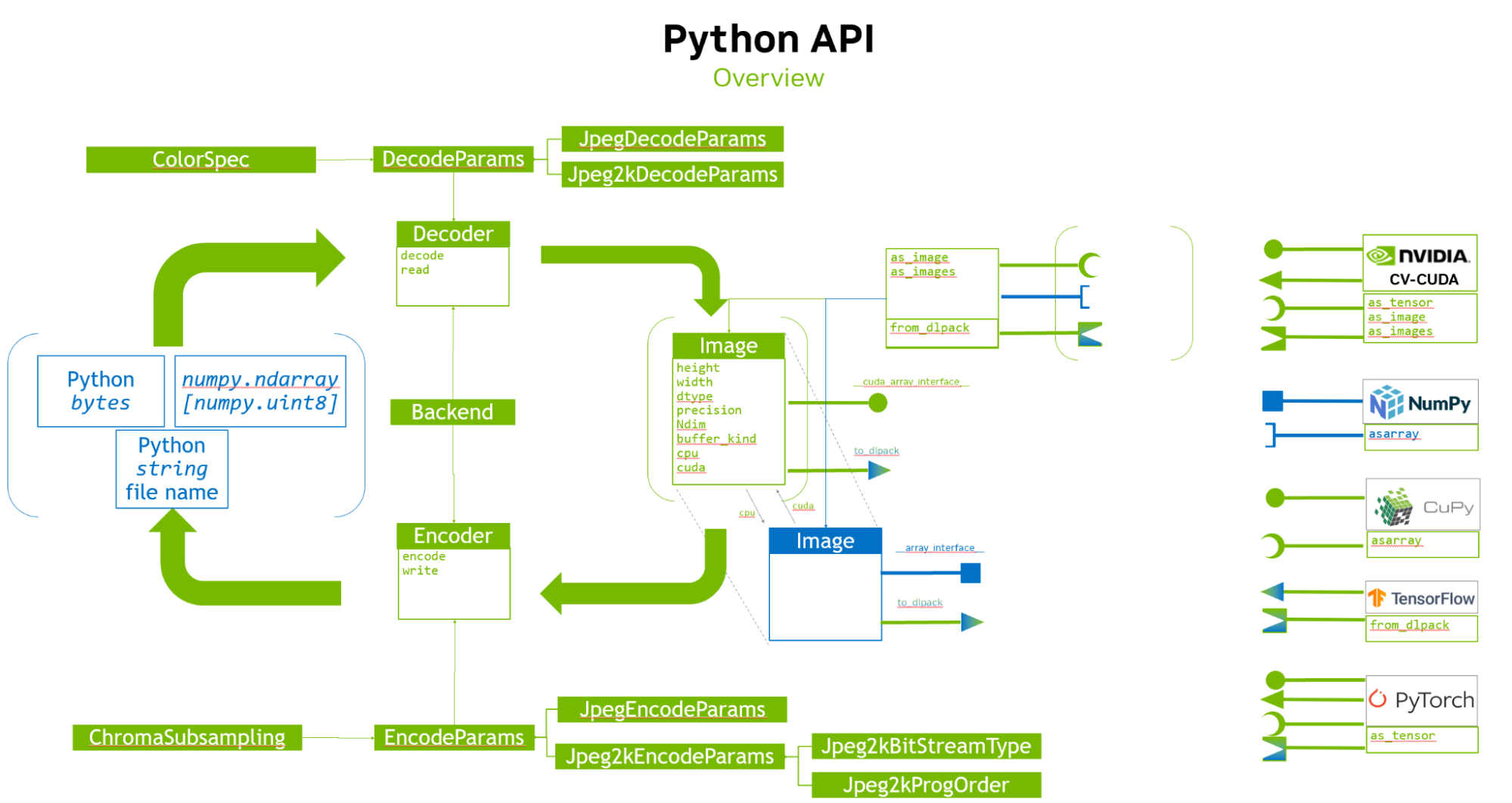
隨著 GPU 加速技術的進步,nvJPEG2000 進一步提高了 HTJ2K 的解碼性能。這種進步釋放了 JPEG 2000 在醫學影像處理中的真正潛力,使其成為醫療健康提供商、研究人員和開發人員可行且高效的解決方案。nvJPEG2000 提供一個 C API 包括用于解碼單個圖像的 nvjpeg2kDecode 和用于解碼圖像中特定圖塊的 nvjpeg2kDecodeTile 等函數。該庫提供了:
- 統一 API 接口 nvImageCodec:**該開源庫與 Python 無縫集成,為開發者提供了便捷的界面。
- 解碼性能分析:HTJ2K 與傳統 JPEG 2000 的解碼性能進行比較分析,深入了解 GPU 加速的機制。
為了確保可用性、高性能以及生產準備,本文將探討如何將 HTJ2K 解碼與 MONAI 框架結合起來。MONAI 是一種專為醫學影像分析設計的框架。MONAI 部署應用 SDK 提供高性能功能,并有助于在醫學影像 AI 應用程序中進行調試。本文還深入探討了使用 AWS HealthImaging、MONAI 和 nvJPEG2000 進行醫學影像處理所帶來的成本效益。
采用 AWS HealthImaging 的企業級醫學影像存儲?
得益于無損 HTJ2K 編碼和 AWS 高性能網絡主干,AWS HealthImaging 提供亞秒級圖像檢索,并可快速訪問云中圖像。它與工作流程無關,可無縫集成到現有的醫學成像工作流程中。它符合 DICOM 標準,確保在醫學影像通信中具有互操作性并符合行業標準。該服務提供本地 API,以實現可擴展和快速的圖像提取,以適應不斷增長的醫學成像數據量。
GPU 加速的圖像解碼?
為進一步增強圖像解碼性能,AWS HealthImaging 專門利用 NVIDIA nvJPEG2000 庫支持 GPU 加速。此 GPU 加速可確保快速高效地對醫學影像進行解碼,使醫療健康提供商能夠以前所未有的速度訪問關鍵信息。HTJ2K 解碼的支持功能包含廣泛的選項,可適應不同的圖像類型、大小、壓縮需求和解碼場景,使其成為各種圖像處理應用程序的通用和適應性選擇。這些功能包括:
- 圖像格式:HTJ2K 支持任意寬度和高度的灰度和彩色圖像,可適應各種圖像格式和尺寸。
- 位深:HTJ2K 支持每通道高達 16 位深度的圖像,確保準確呈現顏色和細節。
- 無損壓縮:HTJ2K 標準支持無損壓縮,確保在不丟失任何數據的情況下保持畫質。
- 統一代碼塊配置:HTJ2K 中所有代碼塊都符合 HT (高吞吐量) 標準,無需進行優化代碼塊,以簡化解碼過程。
- 代碼塊大小:HTJ2K 利用不同的代碼塊大小,例如 64 × 64、32 × 32 和 16 × 16.這種可適應性支持高效地表示細節和復雜性各不相同的圖像。
- 進度順序:HTJ2K 支持多種進度順序,包括: – LRCP (層分辨率 – 組件 – 位置) – RLCP (分辨率層組件位置) – RPCL (分辨率位置組件層) – PCRL (位置 – 組件 – 分辨率層) – CPRL (組件位置分辨率層)
- 變量分解水平:該標準允許不同的分解級別,從 1 到 5 個不等。這種分解靈活性提供了根據特定需求優化圖像壓縮的選項。
- 具有不同塊大小的多塊解碼:HTJ2K 支持解碼分為多個不同大小的圖塊圖像,以增強高效解碼的能力。
AWS HealthImaging 演練?
在此演示中,我們展示了 AWS HealthImaging 的使用情況。我們演示了利用 GPU 加速接口使用 SageMaker 多模型端點進行圖像解碼的過程。
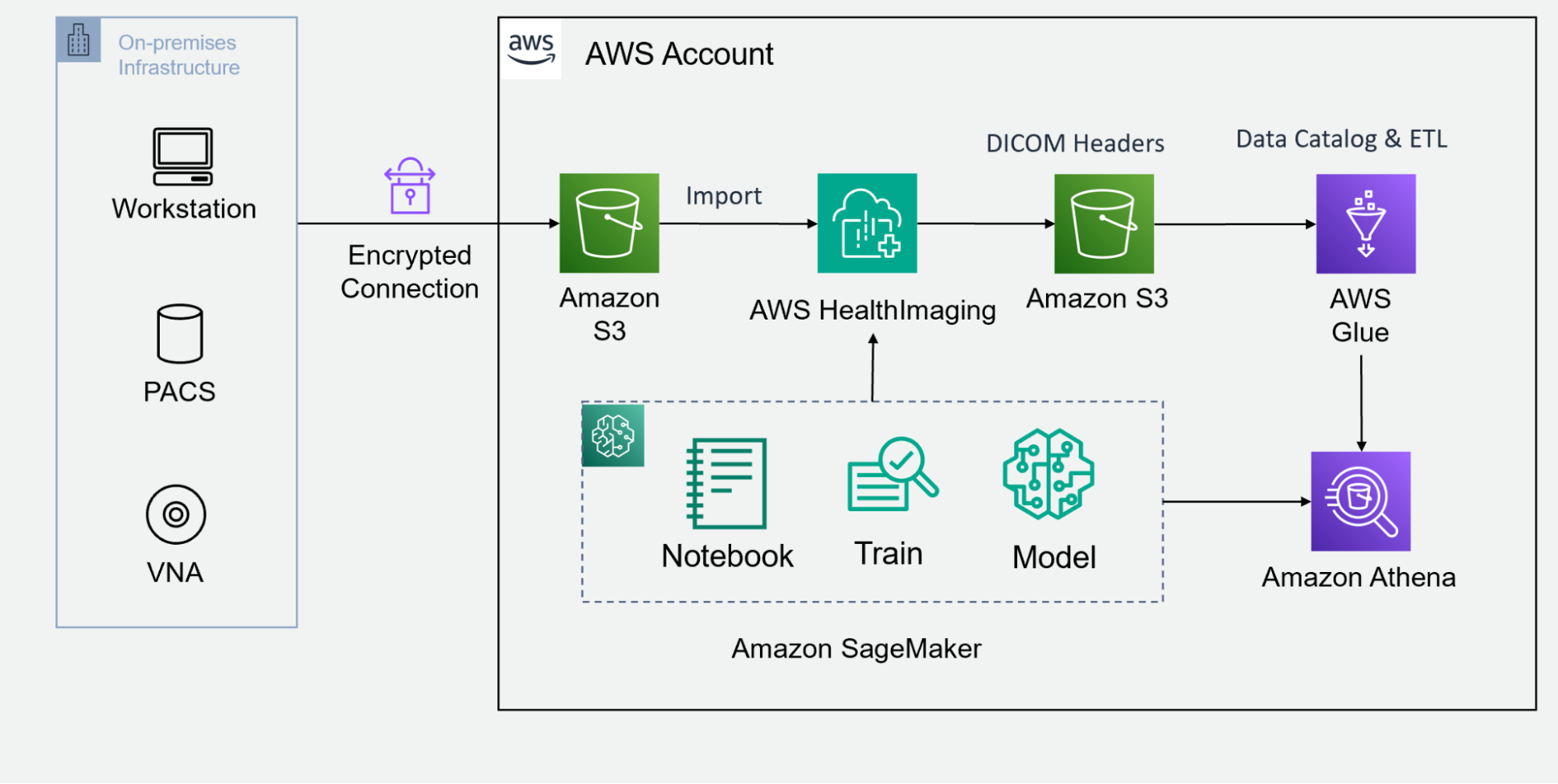
第 1 步:暫存 DICOM 圖像?
首先,將您的 DICOM 圖像暫存到 Amazon S3 存儲桶中。AWS HealthImaging 與合作伙伴產品集成,為您提供各種工具,以在指定的 S3 存儲桶中上傳和整理您的 DICOM 圖像數據。您可以在 AWS 開放數據計劃 公開的 S3 存儲桶中找到包含合成醫學成像數據的開放數據集,例如 合成一致性。
第 2 步:調用 API 以導入 DICOM 數據?
在 S3 存儲桶中暫存 DICOM 影像后,下一步是調用原生 API 將 DICOM 數據導入 AWS HealthImaging.此托管 API 有助于實現流暢的自動化流程,從而確保您的醫學影像數據得到高效傳輸,并為進一步優化做好準備。
第 3 步:在數據湖中索引 DICOM 標頭?
成功導入后,從 AWS HealthImaging 中檢索 DICOM 標頭,解壓縮數據 Blob,并將這些 JSON 對象寫入 數據湖 S3 存儲桶。從這里,您可以利用 AWS 數據湖分析 工具,例如: – 亞馬遜膠 生成數據目錄。 – 亞馬遜 Athena 執行臨時 SQL 查詢。 – Amazon QuickSight 來構建數據可視化控制面板。您還可以將圖像元數據與 其他健康數據模式 相結合,以執行多模態數據分析。
第 4 步:訪問醫學影像數據?
借助托管 API,訪問將成為無縫體驗。AWS HealthImaging 可讓您以亞秒級的速度以高性能和精細的方式訪問成像數據。
AWS 合作伙伴的 PACS 查看器和 VNA 云端解決方案可以將圖像查看應用程序與 AWS HealthImaging 集成。這些應用程序經過優化,以提供用戶友好且高效的體驗,以大規模查看和分析醫學影像。AWS 合作伙伴 PACS 的示例包括 Allina Health、圖像成像和 Visage Imaging。
科學家和研究人員可以利用 Amazon SageMaker 來執行 AI 和 ML 建模,以獲得高級見解,并自動執行審查和標注任務。Amazon SageMaker 與 MONAI 可用于開發強大的 AI 模型。使用 Amazon SageMaker notebook,用戶可以從 AWS HealthImaing 中檢索像素幀,并使用開源工具 (例如 itkwidget) 創建 SageMaker 托管訓練作業 或 模型托管端點。
作為符合 HIPAA 標準的服務,AWS HealthImaging 提供靈活性,允許遠程用戶安全訪問和審計醫療影像數據。訪問控制由 Amazon 身份和訪問管理 管理,確保授權用戶對 ImageSet 數據 的訪問被精細控制。訪問活動也可以通過 Amazon CloudTrail 跟蹤。
第 5 步:支持 GPU 的 HTJ2K 解碼?
在典型的 AI 或 ML 工作流程 (CPU 解碼路徑) 中,HTJ2K 編碼的像素幀將加載到 CPU 顯存中,然后解碼并轉換為 CPU 中的張量。GPU 可以復制和處理這些像素。nvJPEG2000 可以從 AWS HealthImaging 中提取已編碼的像素,并直接將其解碼為 GPU 顯存 (GPU 解碼路徑),而 MONAI 具有內置功能,可將圖像數據轉換為可隨時輸入到深度學習模型中的張量。與 CPU 解碼方法相比,它的路徑更短,如圖 2 所示。
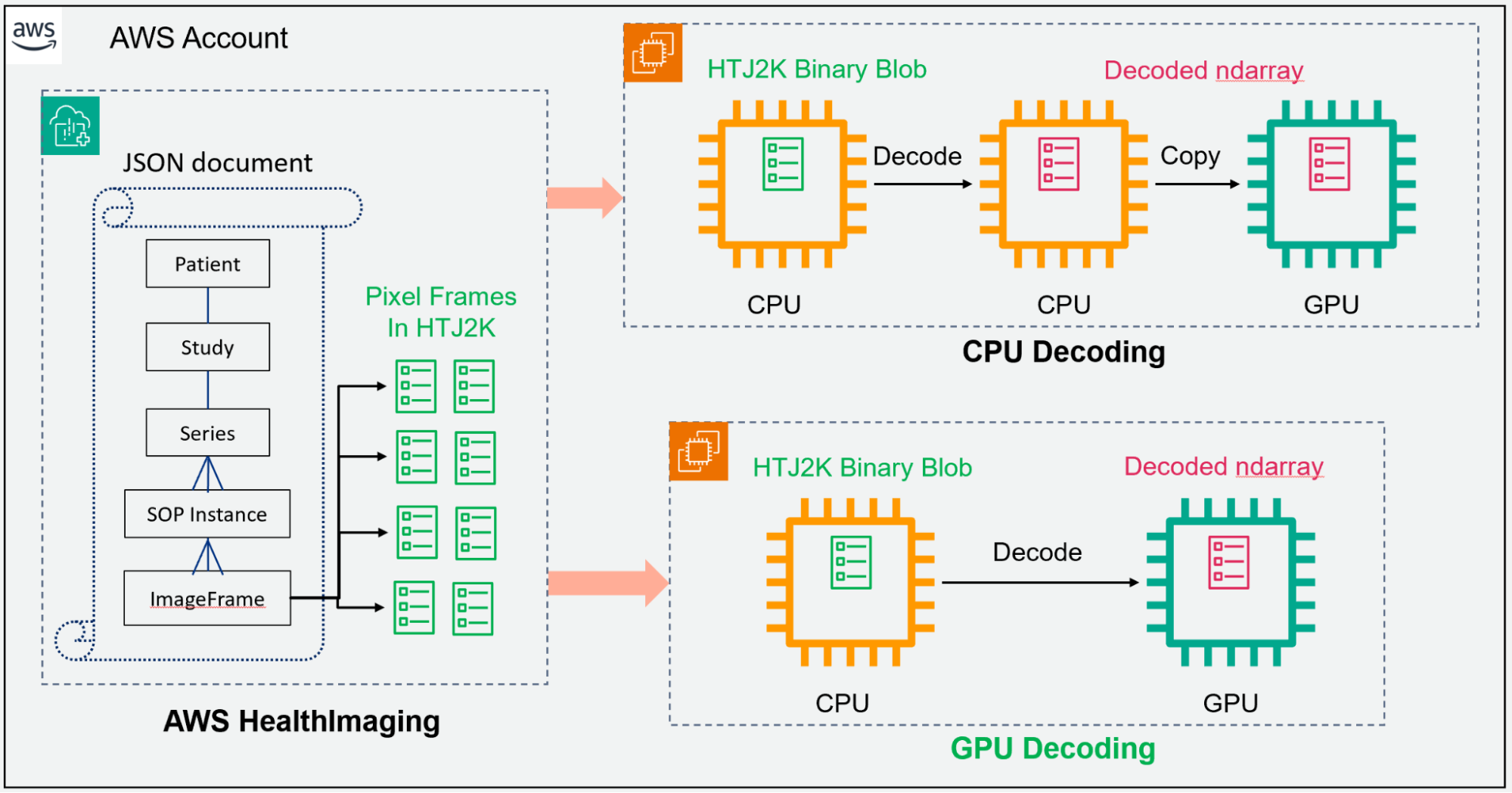
此外,nvJPEG2000 的 GPU 加速可顯著提高解碼性能,降低延遲并增強整體響應速度。該庫與 Python 無縫集成,為開發者提供熟悉且強大的環境來執行圖像解碼任務。
演示 Notebook,運行在 Amazon SageMaker 上,展示了如何以可擴展且高效的方式集成和利用 GPU 加速圖像解碼的強大功能。在我們的實驗中,SageMaker g4dn.2 xlarge 實例上的 GPU 解碼速度比 SageMaker m5.2 xlarge 實例上的 CPU 解碼速度快 7 倍 (圖 3)。
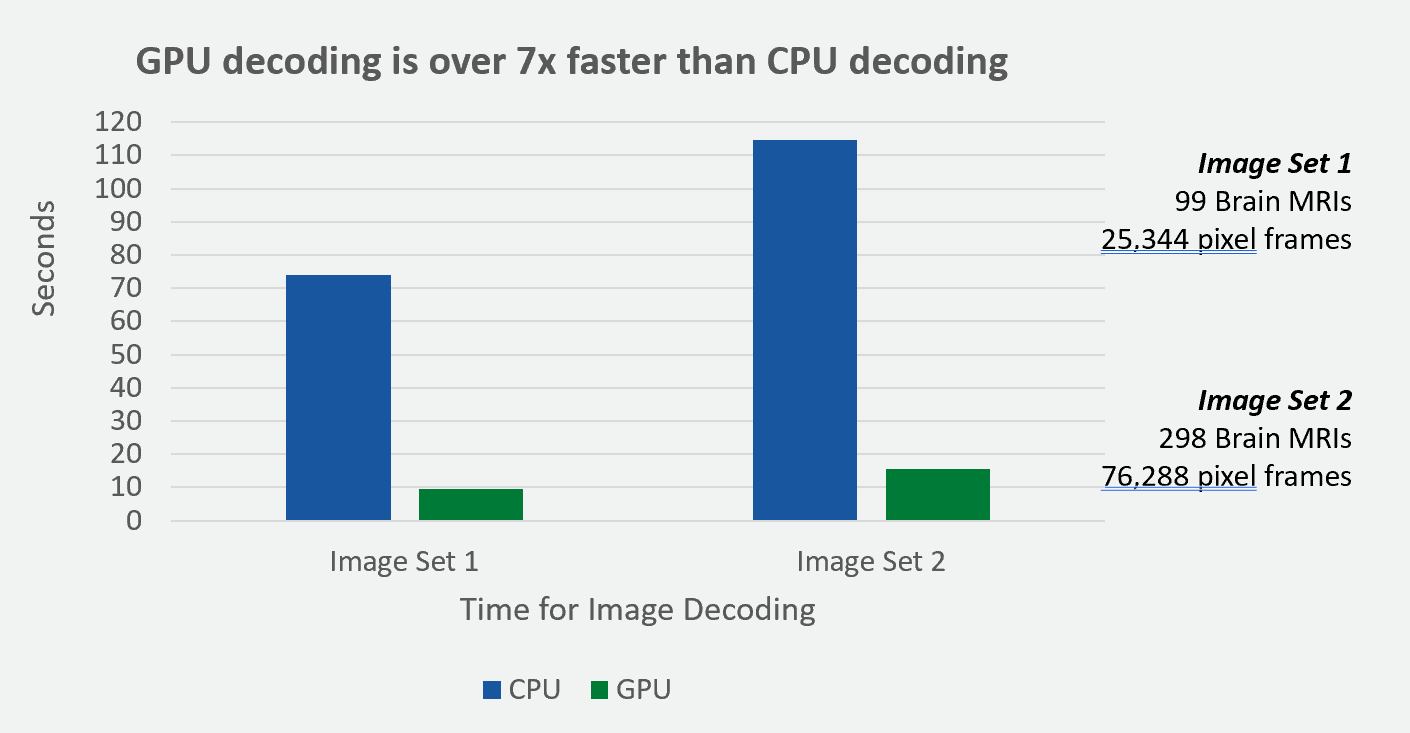
本實驗中,我們使用了 合成一致性 數據集。對于不同大小的數據集,GPU 加速表現出相似的加速系數。上面標記的圖像集包含腦 MRI 和像素幀。這些像素幀表示 DICOM MRI 圖像,并以壓縮的 HTJ2K 數據格式進行編碼。
成本效益分析?
AWS HealthImaging 與先進的圖像解碼技術相結合,不僅能提高效率,還能為醫療保健組織提供經濟高效的解決方案。所提議的解決方案具有巨大的端到端成本優勢,特別是考慮到通過 GPU 加速實現的驚人吞吐量加速。
單臺設備的加速 NVIDIA T4 GPU 在 EC2 G4 實例上的性能提升約為 CPU 基準的 5 倍,而 EC2 G6 實例上的新 L4 GPU 通過使用多個 GPU 實例進行擴展,性能表現出近乎線性的可擴展性,在四個?NVIDIA T4 GPU 和 4個 NVIDIA L4 GPU GPU 實例上分別達到 19 倍和 48 倍。
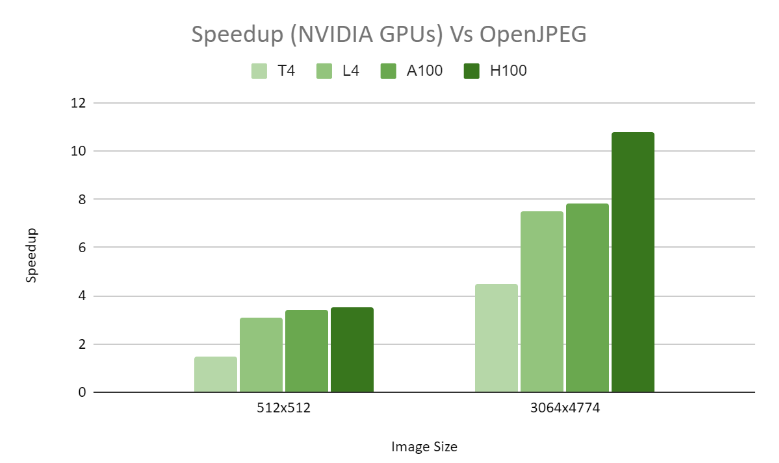
在解碼性能方面,我們使用 OpenJPEG 進行了比較分析。對于 CT1 16 位 512 × 512 灰度圖像,我們注意到不同 GPU 配置的速度顯著提高了 2.5 倍。此外,對于尺寸為 3064 × 4774 的 MG1 16 位灰度圖像,我們在各種 GPU 設置中實現了驚人的 8 倍速度提升。
為了全面評估年度云成本和能源使用情況,我們根據標準分割工作負載進行計算。此工作負載涉及每分鐘向 MONAI 服務器平臺上傳 500 個 DICOM 文件。我們的成本估算目前僅考慮 T4 GPU,預計未來將使用 L4 GPU。我們假設使用 Amazon EC2 G4 實例。
在這種情況下,在單個 T4 GPU 上處理 DICOM 工作負載的年度成本估計約為 7400 萬美元,而與 CPU 流程相關的成本為 3.454 億美元。這意味著云支出大幅減少,預測表明此類醫院工作負載可能會節省數億美元。
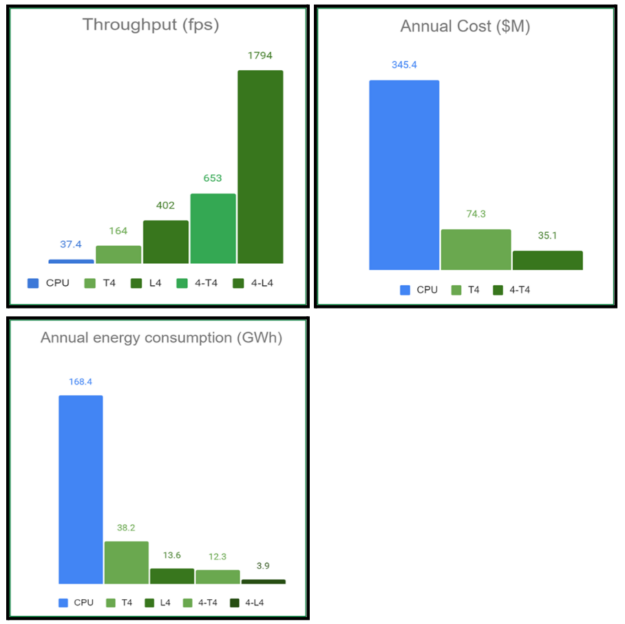
在單個 T4 GPU 上,與 CPU 基準相比,端到端吞吐量加速大約快 5 倍。在新的 L4 GPU 上,這種加速進一步提升到大約快 12 倍。當使用多個 GPU 實例時,性能幾乎呈線性擴展。例如,使用 4 個 T4 GPU 時,加速大約達到 19 倍,而使用 4 個 L4 GPU 時,加速大約快 48 倍。
考慮到對環境的影響,能效是數據中心處理大型工作負載的關鍵因素。我們的計算表明,使用基于 GPU 的相應硬件時,以 GWh 為單位的年能耗顯著降低。具體來說,單個 L4 系統的能耗約為 CPU 服務器的十二分之一。
對于類似于示例 DICOM 視頻場景 (每分鐘 500 小時的視頻) 的工作負載,預計每年可節省數百 GWh 的能源。這些能源節省不僅具有經濟效益,而且還具有重大的環境意義。溫室氣體排放量的減少量相當可觀,類似于避免每年行駛的成千上萬輛客車排放,每輛車每年約覆蓋 11000 英里。
為何選擇 nvImageCodec?
NVIDIA 提供 nvImageCodec 庫,為開發者提供用于圖像解碼任務的可靠高效解決方案。nvImageCodec 利用 NVIDIA GPU 的強大功能,可提供加速解碼性能,非常適合需要高吞吐量和低延遲的應用程序。
主要特性
- GPU 加速:nvImageCodec 的主要特點之一是其 GPU 加速功能。利用 NVIDIA GPU 的計算能力,nvImageCodec 可有效提高圖像解碼速度,從而更快地處理大型數據集。
- 無縫集成:*nvImageCodec 與 Python 無縫集成,為開發者提供熟悉的圖像處理工作流環境。借助用戶友好型 API,將 nvImageCodec 集成到現有 Python 項目中非常簡單。
- 高效性能:借助優化的算法和并行處理,nvImageCodec 提供卓越的性能,即使在處理復雜的圖像解碼任務時也是如此。它支持 JPEG、JPEG 2000、TIFF 等多種圖像格式,并確保快速高效的處理。
- 通用性:nvImageCodec 支持從醫學成像到計算機視覺應用的各種用例。它支持處理灰度圖像和彩色圖像,并提供通用性和靈活性,以滿足您的圖像解碼需求。
用例
- 醫學成像:在醫學影像領域,快速準確的圖像解碼對于及時診斷和治療至關重要。借助 nvImageCodec,醫療保健專業人員可以快速準確地解碼醫學影像,從而加快決策制定并改善患者治療效果。
- 計算機視覺:在計算機視覺應用中,圖像解碼速度在物體檢測和圖像分類等實時處理任務中至關重要。通過利用 nvImageCodec 的 GPU 加速,開發者可以實現高效的圖像解碼,從而提高其應用的響應速度。
- 遙感:在遙感應用中,快速高效地解碼大型衛星圖像對于環境監測和災害管理等各種任務至關重要。借助 nvImageCodec,研究人員和分析人員可以輕松解碼衛星圖像,從而實現及時的分析和決策制定。
如何獲取 nvImageCodec
獲取 nvImageCodec 非常簡單。您可以從以下來源獲取: – PyPI – NVIDIA 開發者領地 – GitHub 下載后,您可以開始嘗試編碼和解碼示例,以提高圖像編解碼器管線的效率。
如何批量解碼高吞吐量的 JPEG 2000 醫學影像?
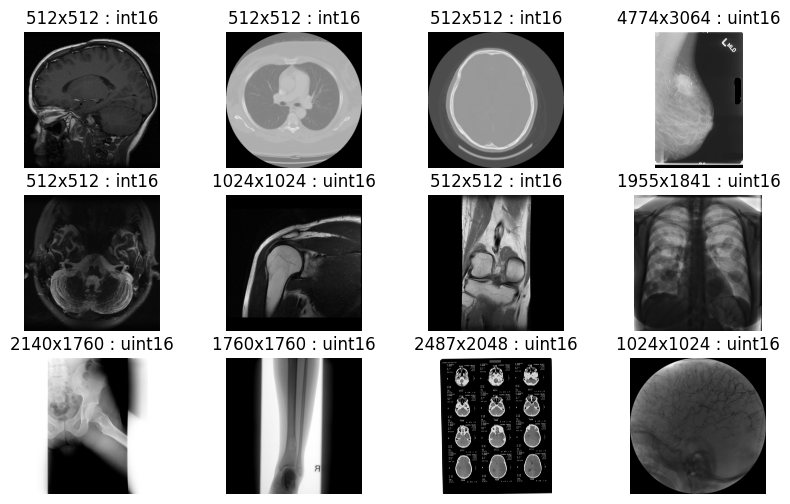
以下是一個 Python 示例,展示了 批量圖像解碼 使用 nvImageCodec 庫。此示例說明了如何使用 nvImageCodec 對 HTJ2K 圖像進行批量解碼。指定文件夾中的所有圖像均以無損 HTJ2K 格式壓縮,精度為 uint16 位。輸出確認所有醫學影像均已成功解碼,且無損質量 (圖 8)。
import os; import os.pathfrom matplotlib import pyplot as pltfrom nvidia import nvimgcodec?
?
dir = "htj2k_lossless"image_paths = [os.path.join(dir, filename) for filename in os.listdir(dir)]decode_params = nvimgcodec.DecodeParams(allow_any_depth = True, color_spec=nvimgcodec.ColorSpec.UNCHANGED)nv_imgs = nvimgcodec.Decoder().read(image_paths, decode_params)?
?
cols= 4rows = (len(nv_imgs)+cols-1)//colsfig, axes = plt.subplots(rows, cols); fig.set_figheight(2*rows); fig.set_figwidth(10)for i in range(len(nv_imgs)):????axes[i//cols][i%cols].set_title("%ix%i : %s"%(nv_imgs[i].height, nv_imgs[i].width, nv_imgs[i].dtype));????axes[i//cols][i%cols].set_axis_off()????axes[i//cols][i%cols].imshow(nv_imgs[i].cpu(), cmap='gray') |
如何批量解碼多個 JPEG 2000 圖塊?
以下是一個 Python 示例,展示了 基于塊的圖像解碼 使用 nvImageCodec 庫處理大型圖像。這個示例展示了如何使用 nvImageCodec 解碼相當大小的 JPEG 2000 壓縮圖像的過程。每個圖塊代表一個感興趣的區域 (ROI),其大小為 512 x 512 像素。
解碼過程包括將圖像分割為圖塊,確定區域總數,然后使用 nvImageCodec 根據每個圖塊的索引對其進行解碼,從而提供特定的圖塊解碼信息。生成的輸出會顯示與不同圖塊相關的信息。
from matplotlib import pyplot as pltimport numpy as npimport random; random.seed(654321)from nvidia import nvimgcodecjp2_stream = nvimgcodec.CodeStream('./B_37_FB3-SL_570-ST_NISL-SE_1708_lossless.jp2')def get_region_grid(stream, roi_height, roi_width):????regions = []????num_regions_y = int(np.ceil(stream.height / roi_height))????num_regions_x = int(np.ceil(stream.width / roi_width))????for tile_y in range(num_regions_y):????????for tile_x in range(num_regions_x):????????????tile_start = (tile_y * roi_height, tile_x * roi_width)????????????tile_end = (np.clip((tile_y + 1) * roi_height, 0, stream.height), np.clip((tile_x + 1) * roi_width, 0, stream.width))????????????regions.append(nvimgcodec.Region(start=tile_start, end=tile_end))????print(f"{len(regions)} {roi_height}x{roi_width} regions in total")????return regionsregions_native_tiles = get_region_grid(jp2_stream, jp2_stream.tile_height, jp2_stream.tile_width) # 512x512 tiles?
?
dec_srcs = [nvimgcodec.DecodeSource(jp2_stream, region=regions_native_tiles[random.randint(0, len(regions_native_tiles)-1)]) for k in range(16)]imgs = nvimgcodec.Decoder().decode(dec_srcs)?
?
fig, axes = plt.subplots(4, 4)fig.set_figheight(15)fig.set_figwidth(15)i = 0for ax0 in axes:????for ax1 in ax0:????????ax1.imshow(np.array(imgs[i].cpu()))????????i = i + 1 |
結束語?
無論您是醫療健康提供商、研究人員還是開發者,JPEG 2000 的復興與尖端技術一起,為醫學成像的關鍵領域開辟了新的創新途徑。AWS HealthImaging 與先進的壓縮標準和 GPU 加速相結合,成為致力于增強診斷能力和提高患者治療效果的醫療健康專業人員的重要工具。
這項創新為高性能 多模態數據分析 無縫集成基因組學、臨床和醫學成像數據,以提取有意義的見解。云上托管的數據科學平臺簡化了模型訓練和部署流程,減少了摩擦。利用這些進步,并通過加速和可靠的圖像解碼來推動醫療健康行業的未來發展。
要開始使用,請探索以下資源: – nvImageCodec:用于圖像編碼和解碼的庫。 – MONAI on AWS 研討會:有關使用 MONAI 在 AWS 上的指南。 – 借助 AWS Health 和機器學習服務進行多模態數據分析:有關使用 AWS Health 和機器學習服務進行多模態數據分析的指南。
- 使用 nvJPEG2000 庫加速數字病理學和衛星圖像的 JPEG 2000 解碼。
- 借助 AWS 上的 MONAI 加速醫學影像研究
- 使用 NVIDIA nvJPEG2000 在 AWS HealthImaging 中解碼醫學影像
- NVIDIA DGX 上細胞分辨率下的全人腦神經網絡映射
?