大型語言模型( LLM ),如 GPT,由于其理解和生成類人文本的能力,已成為自然語言處理( NLP )中的革命性工具。這些模型基于大量不同的數據進行訓練,使其能夠學習模式、語言結構和上下文關系。它們是基礎模型,可以針對廣泛的下游任務進行定制,具有高度的通用性。
諸如分類之類的下游任務可以包括基于預定義標準對文本進行分析和分類,這有助于諸如情緒分析或垃圾郵件檢測之類的任務。在封閉式問答( QA )中,他們可以根據給定的上下文提供精確的答案。在生成任務中,它們可以生成類似人類的文本,例如故事寫作或詩歌創作。即使是頭腦風暴, LLM 也可以利用其龐大的知識庫產生創造性和連貫性的想法。
LLM 的適應性和多功能性使其成為廣泛應用的寶貴工具,使企業、研究人員和個人能夠以顯著的效率和準確性完成各種任務。
這篇文章向您展示了 LLM 如何使用分布式數據集和聯合學習來適應下游任務,以保護隱私并提高模型性能。
LLM 適應下游任務
參數高效的 LLM 微調已經成為使用特定于任務的模塊的一種重要方法,其中保持預訓練的 LLM 層固定,同時使較小的附加參數集適應手頭的特定任務。為了促進這一過程,已經開發了各種技術,包括prompt tuning,p-tuning,adapters,LoRA等。
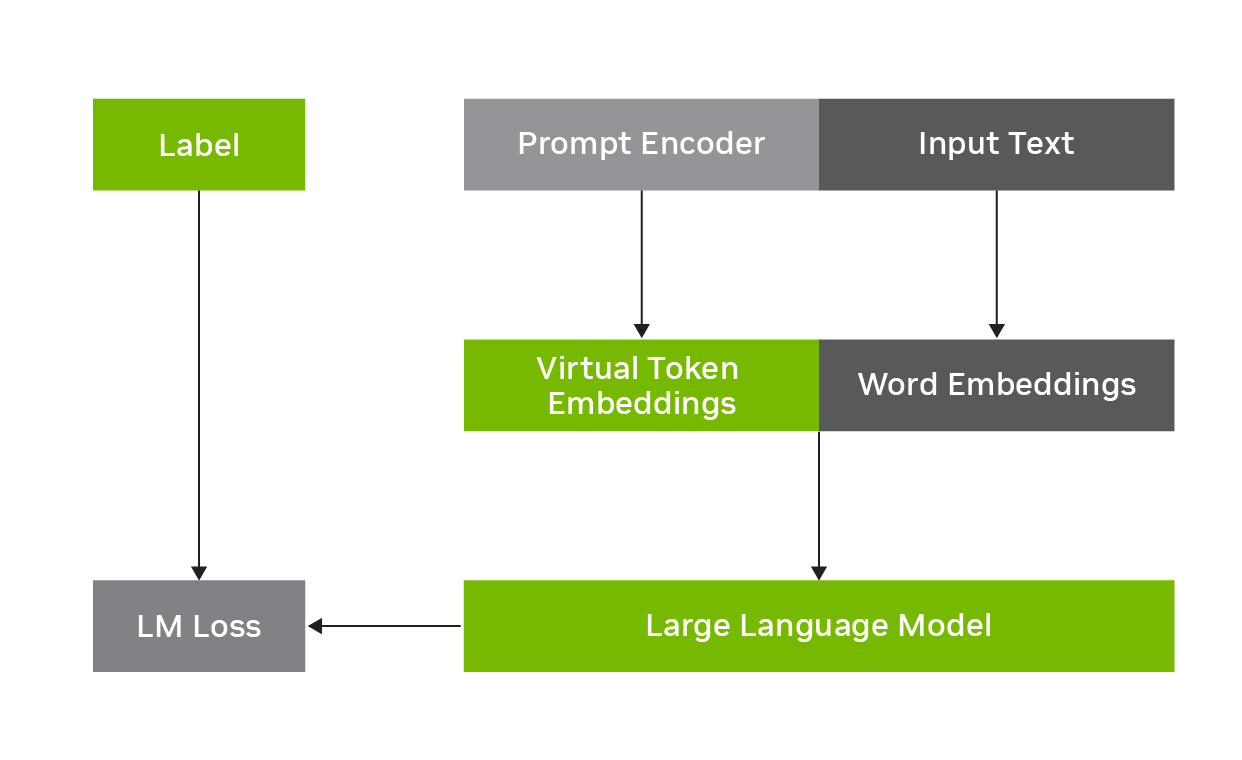
例如, p 調整包括凍結 LLM 并學習預測與原始輸入文本組合的虛擬令牌嵌入,如圖 1 所示.任務特定的虛擬令牌嵌入由提示編碼器網絡預測,該網絡與輸入單詞嵌入一起被饋送到 LLM 中,以在推理時增強下游任務的性能。它是參數有效的,因為只有提示編碼器參數必須在輸入文本和標簽上進行訓練,而基本 LLM 參數可以保持固定。
聯合學習
由于監管限制和復雜的官僚程序,使用私人數據訓練人工智能模型帶來了重大挑戰。隱私法規和數據保護法通常禁止共享敏感信息,限制了傳統數據共享方法的可行性。此外,數據注釋是模型訓練的一個關鍵方面,它會產生巨大的成本,并需要大量的時間和精力。
認識到數據是一種寶貴的資產,聯合學習(FL)已經成為一種解決這些問題的技術。FL 通過共享模型而不是原始數據來繞過傳統的模型訓練過程。參與的客戶端使用它們各自的私有數據集在本地訓練模型,并聚合更新的模型參數,從而保護底層數據的隱私,同時共同受益于培訓過程中獲得的知識。
不需要直接的數據交換,這降低了與數據隱私法規相關的合規風險,并在聯盟中的合作者之間分配了繁重的數據注釋成本。
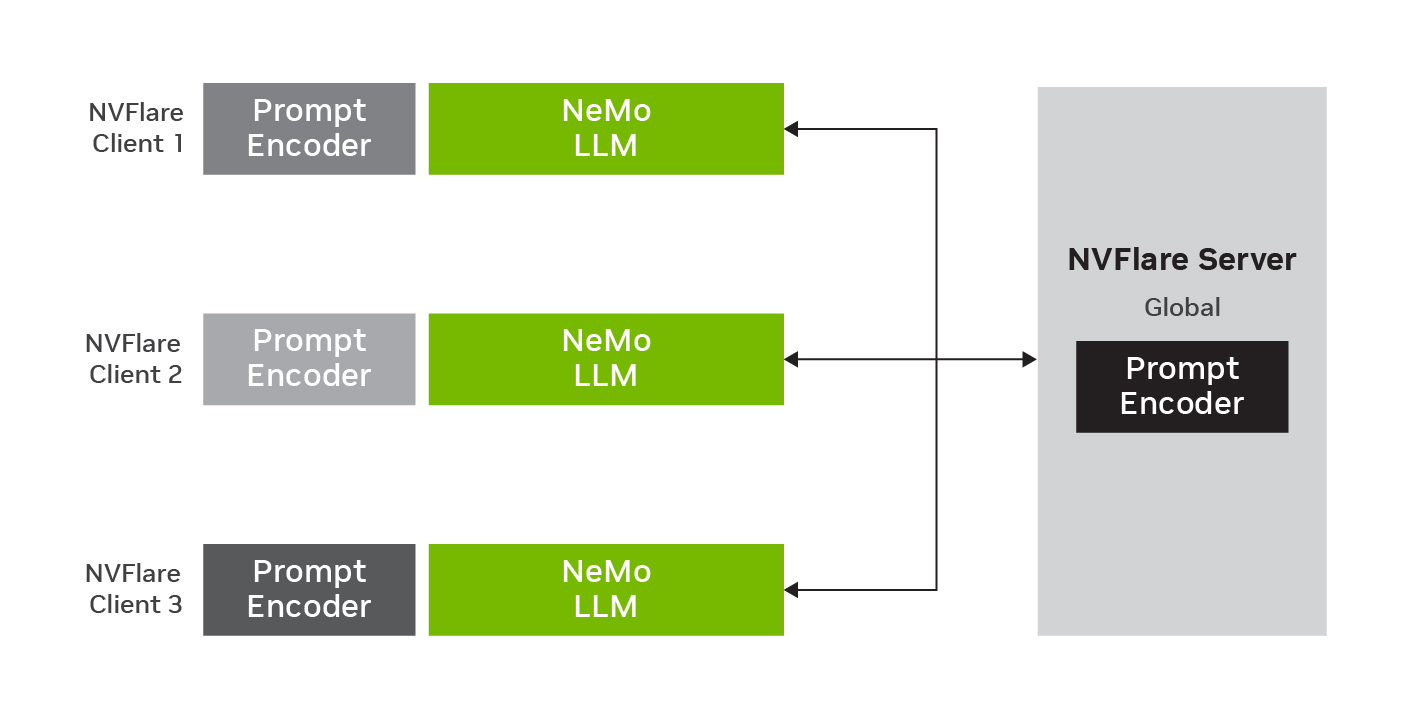
圖 2 顯示了具有全局模型和三個客戶端的聯合 p 調諧。 LLM 參數保持固定,同時在本地數據上訓練提示編碼器參數。在本地訓練之后,新參數在服務器上聚合,以更新全局模型,用于下一輪聯合學習。
將 LLM 的適應性與下游任務聯合起來
FL 通過利用去中心化的數據源使 LLM 能夠適應下游任務。通過在不共享原始數據的情況下跨多個參與者協作訓練 LLM ,可以通過利用集體知識和將模型暴露于更廣泛的語言模式來增強 LLM 的準確性、穩健性和可推廣性(圖 2 )。此外, FL 還提供了各種模型自適應和推理選項,包括基于聚合數據訓練的全局模型和為個人客戶量身定制的個性化模型。
情緒分析的聯合 p 調諧
本節提供了 LLM 的聯合自適應示例,使用 NVIDIA NeMo 框架 對具有下游任務的 NVIDIA Flare 進行 p 調諧。NeMo 和 NVIDIA Flare 都是由 NVIDIA 開發的開源工具包。此微調過程非常有效,因為只需要交換幾十萬個參數,大大減少了通信負擔。
在這個情緒分析任務中,可以使用 p 調諧有效地微調 NeMo Megatron-GPT 模型,它具有 200 億個參數。它使用 Financial PhraseBank dataset,其中包含了從散戶投資者的角度對財經新聞標題的看法。更多詳細信息,請參閱 Good Debt or Bad Debt: Detecting Semantic Orientations in Economic Texts。
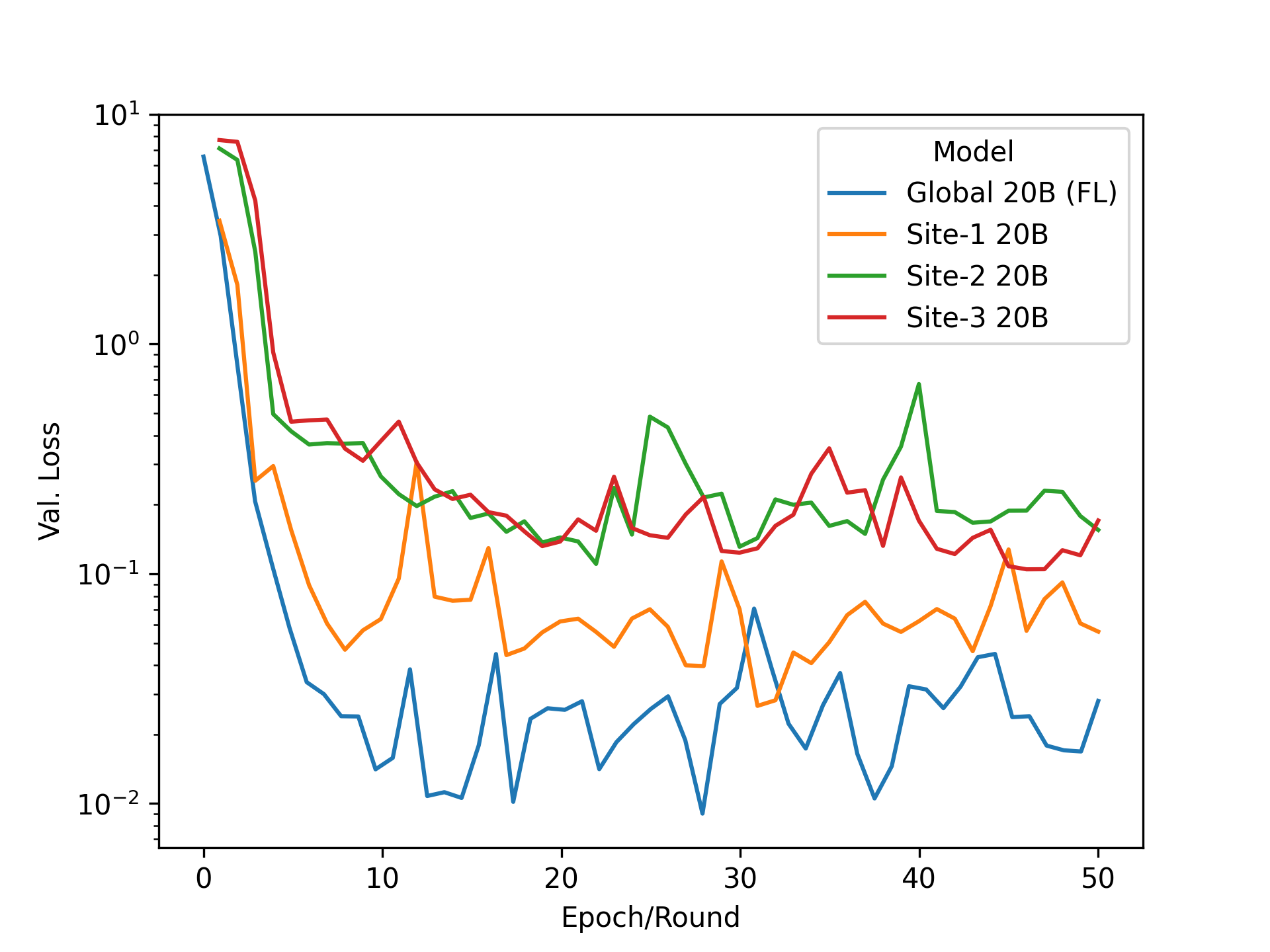
示例輸入和模型預測如圖 3 所示。該數據總共包含 1800 對標題和相應的情緒標簽。在 p 調諧中,僅更新可訓練提示編碼器網絡的 5000 萬個參數(整個 20B 參數的 0 . 25% )。對于 FL 實驗,數據被分為三組,對應于每個網站的 600 個標題和情感對。客戶端使用相同的驗證集來啟用直接比較。

圖 4a 比較了以集中方式訓練模型與聯合模型 50 個時期(或 FL 輪)的情況。在這兩種設置中,自適應模型在下游任務上的表現相當,在驗證集上實現了類似的低損失。圖 4b 將每個客戶端僅在其本地數據集上進行的訓練與使用 FL 進行 p 調諧的模型進行了比較。通過有效地利用協作中可用的較大訓練集,并實現比僅在其數據上進行訓練更低的損失,可以看出使用聯合 p 調諧的全局模型的明顯優勢。
結論
總的來說,這篇文章強調了聯邦 p 調整在使 LLM 適應下游任務方面的潛力,強調了 FL 在實現協作學習以保護隱私和提高模型性能方面的好處。一些關鍵要點是:
- GPT 等大型語言模型徹底改變了 NLP ,為分類、問答、生成和頭腦風暴等各種下游任務提供了多功能性。
- 聯合學習通過共享模型參數而不是原始數據來解決與私人數據相關的挑戰,確保隱私并降低合規風險。
- 使用特定任務模塊(如即時調整或 p 調整)對 LLM 進行微調,可以有效地適應特定任務。
- FL 促進了協作訓練和推理,從而提高了模型性能。
有關詳細信息,請參閱NVIDIA Flare documentation和NVIDIA NeMo framework page。要復制此處解釋的實驗和其他 LLM 任務,請探索Examples of NeMo-NVFlare Integration這里提出的聯合 p 調諧方法可以進一步與附加的privacy-preservingNVIDIA Flare 提供的解決方案,例如homomorphic encryption和differential privacy。要了解更多信息,請參閱NVIDIA FLARE: Federated Learning from Simulation to Real-World.
?