
在 2023 年的人工智能領域,矢量搜索成為最熱門的話題之一,因為它在大語言模型(LLM)和生成式人工智能中發揮了重要作用。語義矢量搜索實現了一系列重要任務,如檢測欺詐交易、向用戶推薦產品、使用上下文信息增強全文搜索以及查找潛在安全風險的參與者。
數據量持續飆升,傳統的逐一比較的方法在計算上變得不可行。矢量搜索方法使用近似查找,這種查找更具可擴展性,可以更有效地處理大量數據。正如我們在這篇文章中所展示的,在 GPU 上加速矢量搜索不僅提供了更快的搜索時間,而且索引構建時間也可以更快。
此帖子提供:
- 矢量搜索簡介及流行應用綜述
- 在 GPU 上加速矢量搜索的 RAFT 庫綜述
- GPU 加速矢量搜索索引與 CPU 上最新技術的性能比較
本系列的第二篇文章深入探討了每一個 GPU 加速指數,并簡要解釋了算法的工作原理以及微調其行為的重要參數摘要。想要了解更多信息,請訪問 加速向量搜索:微調 GPU 索引算法。
什么是矢量搜索?

圖 1 顯示了矢量搜索需要創建一個矢量索引,并執行查找以在索引中找到一些最接近查詢矢量的矢量。矢量可以小到激光雷達點云中的三維點,也可以是文本文檔、圖像或視頻中的較大嵌入向量。
矢量搜索是查詢數據庫以查找最相似矢量的過程。這種相似性搜索是在可以表示任何類型對象的數字向量上進行的(圖 2)。這些向量通常是從多媒體(如圖像、視頻和文本片段)或整個文檔中創建的嵌入向量,這些文檔經過深度學習模型將其語義特征編碼為向量形式。
嵌入向量通常具有比原始文檔更小的對象(維度更低)的優勢,同時保持盡可能多的源信息。因此,兩個相似的文檔通常具有相似的嵌入向量。
圖 2 中的點是 3D 的,但它們可能是 500 維甚至更高。
這使得比較對象更容易,因為嵌入向量更小,并且保留了大部分信息。當兩個文檔共享相似的特征時,它們的嵌入向量通常在空間上接近或相似。
矢量搜索的近似方法
為了有效地處理較大的數據集,通常使用近似最近鄰(ANN)方法進行向量搜索。神經網絡方法通過逼近最接近的矢量來加快搜索速度。這避免了精確暴力方法通常需要的窮舉距離計算,該方法需要將查詢與數據庫中的每個向量進行比較。
除了搜索計算成本外,存儲許多向量還可能消耗大量內存。為了確保快速搜索和低內存使用率,必須以高效的方式對向量進行索引。正如我們稍后所概述的,這有時可以從壓縮中受益。矢量索引是建立在數學模型上的一種空間有效的數據結構,用于一次有效地查詢多個矢量。
當索引需要數小時甚至數天才能建立時,更新索引(例如插入和刪除向量)可能會導致問題。事實證明,這些索引通常可以在 GPU 上更快地構建。我們稍后將在帖子中展示這一表現。
LLM 中的矢量搜索
LLM 由于捕捉和保存原始文檔的語義和上下文而變得流行起來。這意味著可以使用向量相似性搜索。此搜索可查找恰好包含相似單詞、形狀或移動對象的項目。它還發現了在上下文和語義上意味著相似事物的向量。
這種語義搜索不依賴于精確的單詞匹配。例如,在圖像數據庫中搜索術語“我想買一輛肌肉車”應該能夠將句子置于上下文中,以理解以下內容:
- 買車和租車不同,所以你希望找到更接近汽車經銷商和購車者評論的載體,而不是租車公司。
- 肌肉車不同于健美運動員,所以你會期望找到道奇充電器的矢量,而不是阿諾德·施瓦辛格。
- 購買肌肉車與購買肌肉放松劑或經濟型汽車不同。
最近出現了基于大型語言 transformer 的模型,如NeMo和 BERT,它們提供了重大的技術飛躍,提高了模型的上下文意識,使其更加有用,適用于更多的行業。
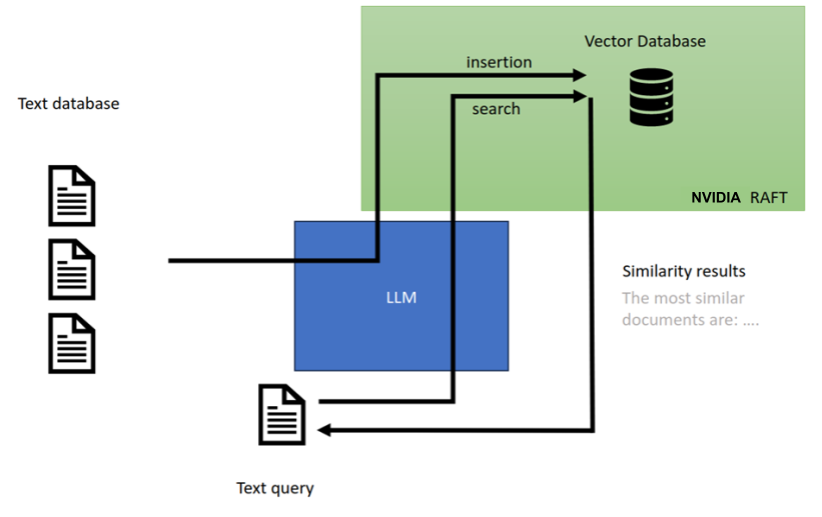
除了創建可以存儲和稍后搜索的嵌入向量外,這些新的 LLM 模型還在管道中使用語義搜索,這些管道從通過查找類似向量收集的上下文中生成新內容。如圖 3 所示,這個內容生成過程稱為檢索增強了生成人工智能。
在矢量數據庫中使用矢量搜索
矢量數據庫存儲高維矢量(例如,嵌入向量),并促進基于矢量相似性的快速準確搜索和檢索(例如,ANN 算法)。一些數據庫是專門為矢量搜索而構建的(例如 Milvus)。其他數據庫包括矢量搜索功能作為附加功能(例如 Redis)。
選擇要使用的矢量數據庫取決于工作流的要求。
檢索增強語言模型允許通過使用已由 LLM 編碼為向量并存儲在向量數據庫中的附加上下文來增強搜索,從而為特定產品、服務或其他領域特定用例定制預訓練的模型。
更具體地說,搜索被編碼為向量形式,并且在向量數據庫中找到相似的向量以增強搜索。然后將向量與 LLM 一起使用,以形成適當的響應。檢索增強 LLM 是生成人工智能的一種形式,它們徹底改變了聊天機器人和語義文本搜索行業。
向量相似性搜索的其他應用
除了用于生成人工智能的檢索增強 LLM 之外,嵌入向量已經存在了一段時間,并在現實世界中發現了許多有用的應用:
- 推薦系統:根據用戶的興趣或互動行為,提供個性化建議。
- 財務:欺詐檢測模型將用戶交易向量化,從而可以確定這些交易是否與典型的欺詐活動相似。
- 網絡安全:使用嵌入向量對不良行為者和異常活動的行為進行建模和搜索。
- 基因組學:在基因組學分析中,我們可以發現相似的基因和細胞結構,如單細胞 RNA 分析。
- 化學:對化學結構的分子描述符或指紋進行建模,以便比較它們或在數據庫中找到類似的結構。
我們總是有興趣了解您的用例,所以如果您已經使用矢量搜索,或者想討論它如何對您的應用程序有益,請不要猶豫,留下評論。
RAPIDS RAFT 矢量搜索庫
RAFT 是一個可組合構建塊庫,用于加速 GPU 上的機器學習算法,例如最近鄰居和向量搜索中使用的算法。ANN 算法是構成矢量搜索庫的核心構建塊之一。最重要的是,這些算法可以極大地受益于 GPU 加速。
有關 RAFT 的核心 API 及其包含的各種加速構建塊的更多信息,請參閱RAPIDS RAFT 中的機器學習和數據分析的可復用計算模式。
用于快速搜索的人工神經網絡
除了精確搜索的暴力法,RAFT 目前為 ANN 搜索提供了三種不同的算法:
- IVF-Flat
- IVF-PQ
- CAGRA
算法的選擇可能取決于您的需求,因為它們各自提供不同的優勢。有時,暴力甚至是更好的選擇。更多內容將在即將發布的版本中添加。
由于這些算法沒有進行精確的搜索,可能會遺漏一些高度相似的向量。這個 recall 度量可以用于表示結果中有多少鄰居是查詢的實際最近鄰居。我們的大多數基準都以 85% 及更高的召回率為目標,這意味著檢索到 85%(或更多)的相關向量。
要針對不同的召回級別調整結果索引,請在訓練近似近鄰算法時使用各種設置或超參數。降低召回率通常會提高搜索速度,而提高召回則會降低搜索速度。這就是所謂的召回-速度權衡。
想要了解更多信息,請訪問 加速向量搜索:微調 GPU 索引算法。
性能比較
GPU 擅長一次處理大量數據。當一次計算數千或數萬個點的最近鄰居時,剛才提到的所有算法都可以優于 CPU 上的相應算法。
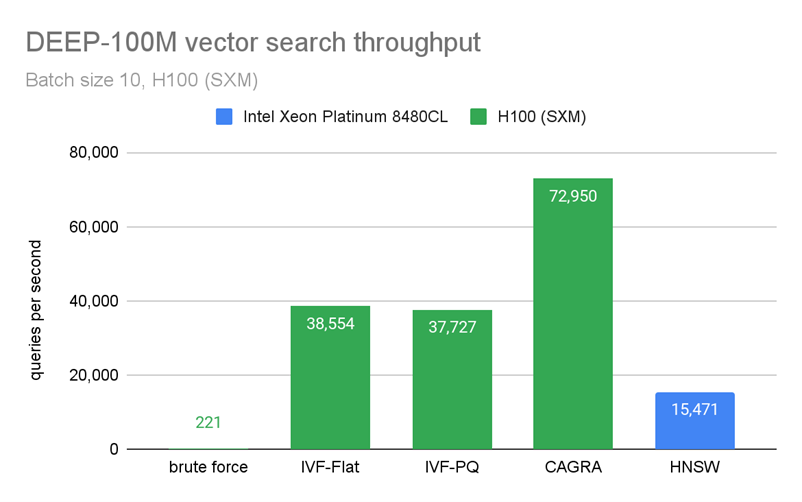
然而,CAGRA 是專門為在線搜索而設計的,這意味著即使一次只查詢幾個數據點的最近鄰居,它的性能也優于 CPU 。
圖 4 和圖 5 顯示了我們通過在 100M 向量上構建索引并一次只查詢 10 個向量來執行的基準測試。在圖 4 中,CAGRA 在原始搜索性能方面優于 HNSW,HNSW 是 CPU 上最受歡迎的矢量搜索索引之一,即使是 10 個矢量的極小批量。然而,這種速度是以內存為代價的。在圖 5 中,您可以看到 CAGRA 的內存占用比其他近鄰方法略高。
在圖 5 中,IVF-PQ 的主機內存用于可選的細化步驟。
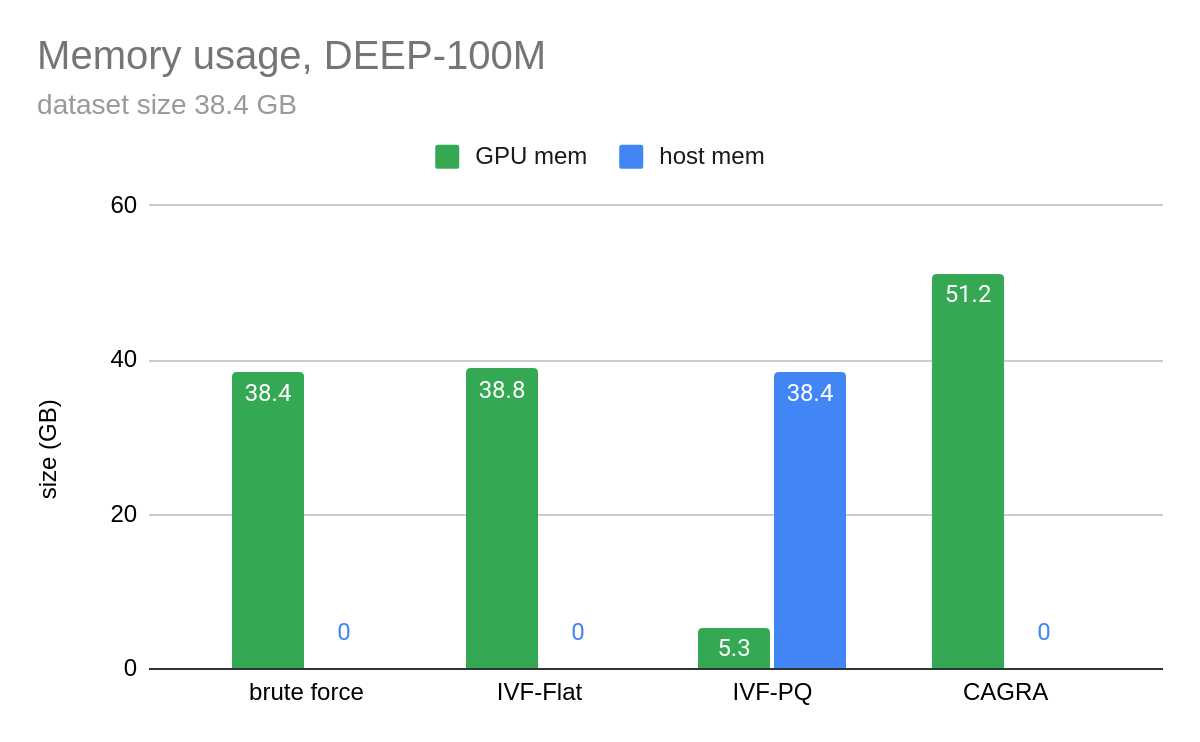
圖 6 顯示了索引構建時間的比較,并表明索引通常可以在 GPU 上更快地構建。
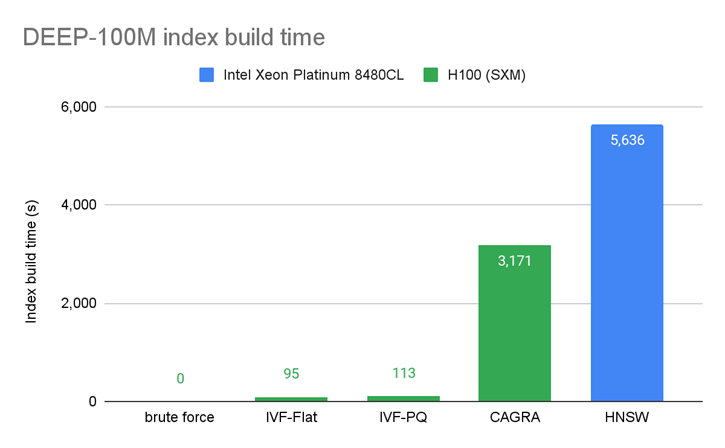
總結
從特征庫到生成人工智能,向量相似性搜索可以應用于每個行業。 GPU 上的矢量搜索以較低的延遲執行,并為在線和批量處理的每一級調用實現更高的吞吐量。
RAFT 是一組可組合的構建塊,可用于加速任何數據源中的矢量搜索。它為 Python 和 C++預先構建了 API。Milvus、Redis 和 FAISS 的 RAFT 集成正在進行中。我們鼓勵數據庫提供商嘗試 RAFT,并考慮將其集成到他們的數據源中。
除了最先進的 ANN 算法,RAFT 還包含了如矩陣和向量運算、迭代求解器和聚類算法等其他 GPU 加速構建塊。在本系列的第二篇文章中,我們深入探討了每種 GPU 加速索引方法,并簡要解釋了算法的工作原理,以及總結重要的微調參數。有關詳細信息,請參閱 加速向量搜索:微調 GPU 索引算法。
RAPIDS RAFT 是完全開源的,您可以在 /rapidsai/raft GitHub 上查看。您也可以在 Twitter 上關注我們 @rapidsai。
?









