
這個 系列的第一篇文章 介紹了矢量搜索索引,解釋了它們在實現廣泛的重要應用中所起的作用,并使用了 RAFT 庫。
在這篇文章中,我們深入探討第 1 部分中提到的每種 GPU 加速索引方法,并簡要解釋了算法的工作原理,以及總結重要的微調參數。
然后,我們通過一個簡單的端到端示例,用預訓練的大型語言模型演示 RAFT 在問答問題上的 Python API,并在涉及同時傳遞給搜索算法的不同查詢向量數量的幾個不同場景下,將 RAFT 的算法與 HNSW 的性能進行比較。
此帖子提供:
- 可與 GPU 一起使用的矢量搜索索引算法概述
- 一個端到端的例子演示了使用 Python 在 GPU 上運行矢量搜索是多么容易
- GPU 上的矢量搜索與 CPU 上當前最先進的 HNSW 方法的性能比較
矢量搜索索引
使用矢量搜索時,矢量通常會轉換為索引格式,該格式針對快速查找進行了優化。選擇正確的索引算法很重要,因為它會影響索引構建和搜索時間。此外,每種不同的索引類型都有自己的一組參數,用于微調行為、權衡索引構建時間、存儲成本、搜索質量和搜索速度。
當正確的索引算法與正確的參數設置配對時, GPU 上的矢量搜索為各種召回率提供了更快的構建和搜索時間。
IVF-Flat
由于它是最簡單的索引類型,我們建議您從 IVF-Flat 算法 開始。在該算法中,一組訓練向量首先被分割成一些聚類,然后被存儲在由它們最近的聚類中心組織的 GPU 內存中。索引構建步驟比本文中介紹的其他算法更快,即使在大量簇的情況下也是如此。
為了搜索 IVF-Flat 索引,選擇與每個查詢向量最近的聚類,并根據這些最接近的聚類中的每個來計算 k 個最近鄰居(k-NN)。因為 IVF-Flat 以原始形式存儲向量,意味著沒有壓縮,它的優勢是計算它搜索的每個簇內的精確距離。正如我們稍后在本文中所描述的,當搜索相同數量的最接近聚類時,這提供了一個優勢,通常比 IVF-PQ 具有更高的召回率。當 GPU 內存可以容納全量索引時,IVF-Flat 索引是一個很好的選擇。
RAFT 的 IVF-Flat 索引包含幾個參數,有助于權衡查詢性能和準確性:
- 訓練索引時,n_lists參數確定用于對訓練數據集進行分區的簇的數量。
- 搜索參數n_probes確定要搜索的最近聚類的數量,以計算一組查詢點的最近鄰居。
一般來說,較少的探針數量會以召回為代價,導致搜索速度更快。當探測器的數量設置為列表的數量時,會計算出確切的結果。但是,在這種情況下,RAFT 的暴力搜索表現更佳。
IVF-PQ
當數據集變得太大而無法放在 GPU 上時,您可以通過使用 IVF-PQ 索引類型 來解決。與 IVF Flat 一樣,IVF-PQ 將點劃分為多個簇(也由 n_lists 參數指定)并搜索最近的聚類以計算最近的鄰居(也由 n_probes 參數指定),但它使用一種稱為 product quantization 的方法。
壓縮索引最終允許在 GPU 上存儲更多的矢量。壓縮量可以通過調整參數來控制,我們稍后將對此進行描述,但更高級別的壓縮可以以調用為代價提供更快的查找時間。IVF-PQ 是目前 RAFT 最具內存效率的矢量索引。
RAFT 的 IVF-PQ 提供了兩個控制內存使用的參數:
- pq_dim 設置壓縮向量的目標維度。
- pq_bits 設置壓縮后每個矢量元素的位數。
我們建議將前者設置為 32 的倍數,而將后者限制在 4-8 位的范圍內。默認情況下,RAFT 根據 pq_bits,但可以調整此值以降低每個矢量的內存占用面積。使用這些參數可以查看哪些設置最適合您,這很有用。
當使用大量壓縮時,refinement step 可以通過在 IVF-PQ 索引中查詢比所需數量更多的鄰居,并計算對結果鄰居的精確搜索,以將集合減少到最終期望的數量來執行。細化步驟需要主機內存上的原始未壓縮數據集。
想要獲取更多關于構建 IVF-PQ 索引的信息,以及深入的細節和建議,請參閱在 GitHub 存儲庫上的 RAFT IVF-PQ 完整指南 筆記本 。
CAGRA
CAGRA 是 RAFT 最新的、最先進的 ANN 指數。這是一種高性能的、 GPU 加速的、基于圖的方法,專門針對小批量情況進行了優化,其中每次查找只包含一個或幾個查詢向量。與其他流行的基于圖的方法一樣,如分層可導航小世界圖(HNSW)和 SONG,優化的 k-NN 圖是在索引訓練時構建的,具有各種質量,可以在合理的召回水平上產生有效的搜索。
CAGRA 通過首先從圖中隨機選擇候選頂點,然后擴展或遍歷這些頂點來計算到其子頂點的距離,并在搜索過程中存儲最近的鄰居來執行搜索(圖 1)。每次遍歷一組頂點時,它都會執行一次迭代。
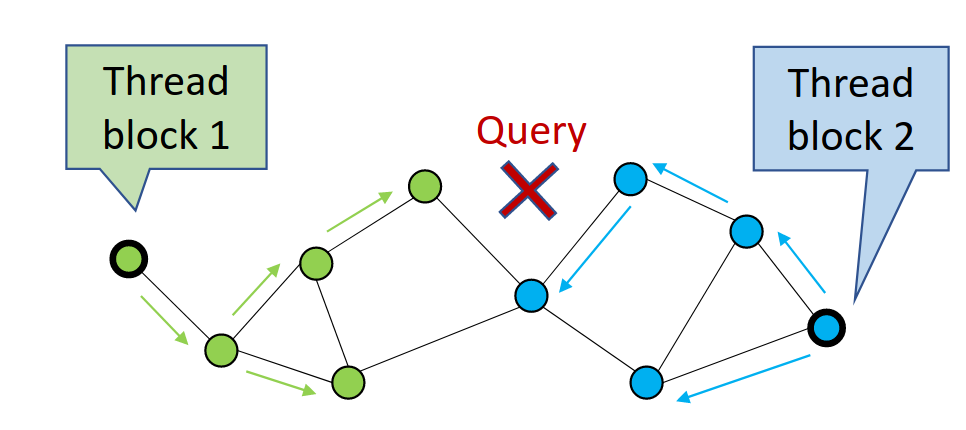
在圖 1 中,CAGRA 使用多個線程塊并行訪問更多的圖節點。這最大限度地提高了單查詢搜索的 GPU 利用率。
因為 CAGRA 像前面描述的算法一樣返回近似的最近鄰居,所以它還提供了一些參數來控制召回和速度。
可以調整以權衡搜索速度的主要參數是itopk_size,指定內部排序列表的大小,該列表存儲可以在下一次迭代中探索的節點。的較高值itopk_size在內存中保留更大的搜索上下文,這會以花費更多時間維護隊列為代價來提高召回率。
參數搜索寬度定義在每次搜索迭代中為展開其子頂點而遍歷的最近父頂點的數目。
另一個有用的參數是要執行的迭代次數。默認情況下,該設置是自動選擇的,但可以將其更改為更高或更低的值,以換取更快的搜索。
CAGRA 的優化圖是固定度的,使用參數進行調整圖形度固定度通過在搜索圖時保持計算次數的一致性來更好地利用 GPU 資源。它通過計算實際的 k-NN 來構建初始 k-NN 圖,例如通過使用前面解釋的 IVF-PQ 來計算訓練數據集中所有點的最近鄰居。
的編號k-最近的鄰居(k)可以使用一個名為中間圖形度以權衡最終可搜索的 CAGRA 圖的質量。
可以使用更大的中間圖形度值,這意味著最終優化的圖更有可能找到產生高召回率的最近鄰居。RAFT 提供了幾個有用的參數來調整 CAGRA 算法。想了解更多詳細信息,請參閱CAGRA API 文檔。
同樣,這個參數可以用來控制搜索對整個空間的覆蓋程度,但這也是以必須進行更多搜索才能找到最近的鄰居為代價的,這降低了搜索性能。
pylibraft 入門
Pylibraft 是 RAFT 的輕量級 Python 庫,使您能夠使用 RAFT 的 ANN 算法在 Python 中進行矢量搜索。Pylibraft 可以接受任何支持 __CUDA_array_interface__ 的庫,例如 Torch 或 CuPy。
以下示例簡要演示了如何使用 Pylibraft 構建和查詢 RAFT CAGRA 索引。
from pylibraft.neighbors import cagraimport cupy as cp?
# On small batch sizes, using "multi_cta" algorithm is efficientindex_params = cagra.IndexParams(graph_degree=32)search_params = cagra.SearchParams(algo="multi_cta")?
corpus_embeddings = cp.random.random((1500,96), dtype=cp.float32)query_embeddings = cp.random.random((1,96), dtype=cp.float32)?
cagra_index = cagra.build(index_params, corpus_embeddings)# Find the 10 closest vectorshits = cagra.search(search_params, cagra_index, query_embeddings, k=10) |
隨著 LLM 的最近成功,語義搜索已經成為展示使用 RAFT 的向量相似性搜索的完美方式。在以下示例中,DistilBERT transformer 模型與三個神經網絡指標中的每一個指標相結合,用于解決一個簡單的問題檢索問題。簡單英語維基百科數據集用于回答用戶的搜索查詢。
語言模型首先將訓練語句轉換為插入 RAFT ANN 索引的向量嵌入。推理是通過對查詢進行編碼并使用我們訓練的 ANN 索引來找到與編碼的查詢向量相似的向量來完成的。你返回給用戶的答案是簡單維基百科中最近的文章,你可以使用相似性搜索中最接近的向量來獲取它。
您可以使用 pylibraft 和本筆記本開始 RAFT 的問題檢索任務:
 by
by 基準
使用 GPU 作為矢量搜索應用程序的硬件加速器可以提高性能,這在大型數據集上表現得尤為明顯。您可以通過參考 RAFT 的端到端基準測試文檔來完全復制這個基準。我們的基準測試假設數據已經可以用于計算,這意味著數據傳輸沒有被考慮在內,盡管由于最近 NVIDIA 硬件的高傳輸速度(超過 25 GB/s),這應該不會造成顯著的差異。
我們使用在 H100 GPU 上的 DEEP-100M 數據集,以將 RAFT 索引與運行在 Intel Xeon Platinum 8480CL CPU 上的 HNSW 進行比較。
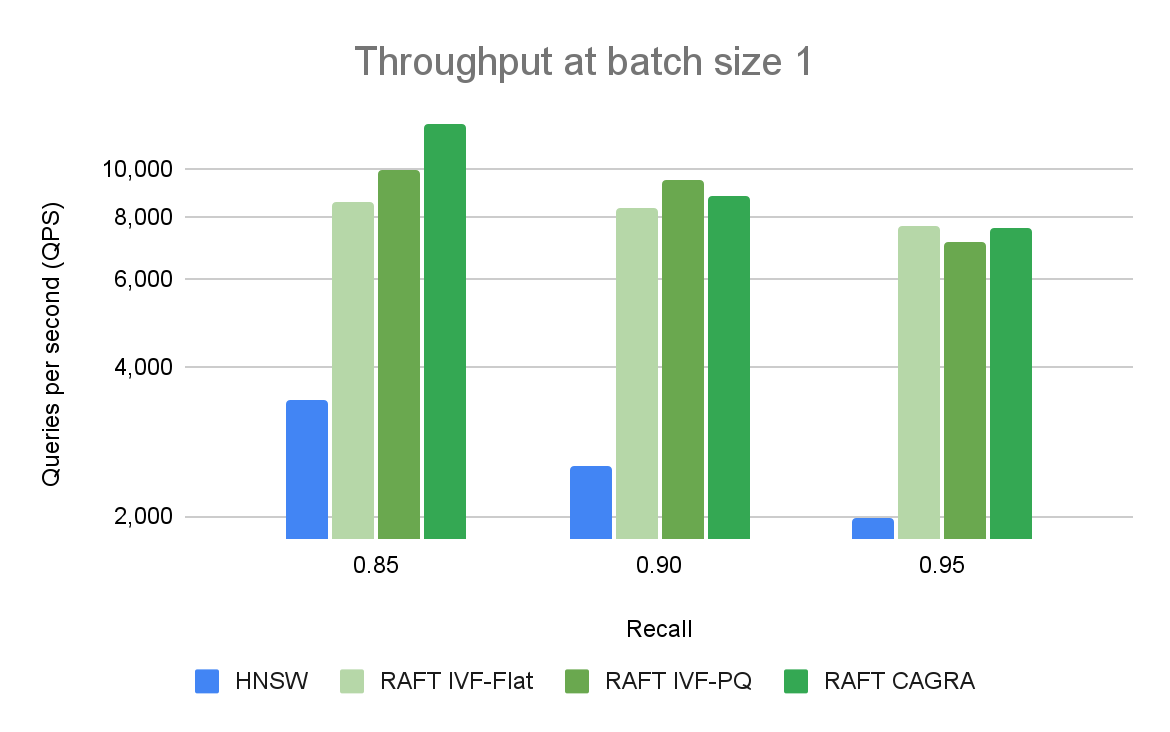
圖 2 比較了單個查詢在不同召回率和吞吐量水平下的 ANN 算法。在高召回率下,RAFT 的方法顯示出比其他替代庫更高的吞吐量。
我們一次對單個向量的查詢進行性能比較,稱為在線搜索。它是矢量搜索的主要用例之一。與使用 CPU 或 GPU 的其他庫相比,基于 RAFT 的索引提供了更高的吞吐量(以每秒查詢量(QPS)衡量)。
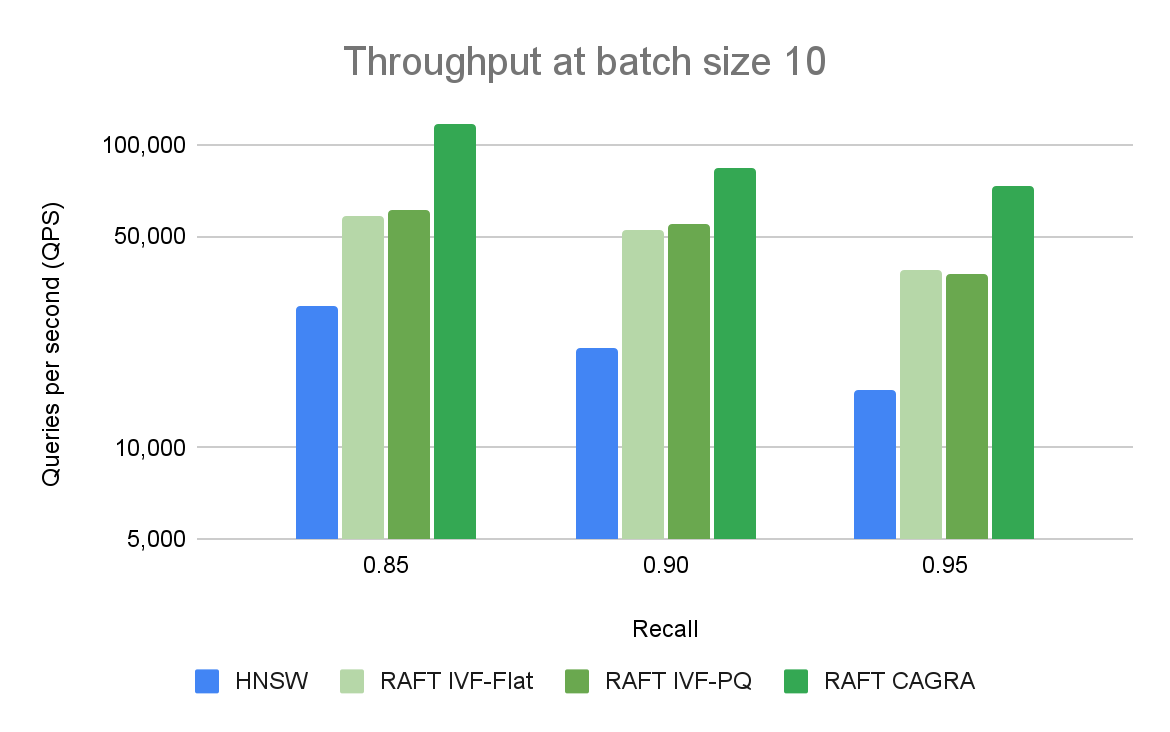
圖 3 比較了不同召回和吞吐量級別的 ANN 算法與 10 個查詢的批量大小。RAFT 的方法在所有實驗中都表現出比 HNSW 更高的吞吐量。
將 GPU 用于矢量搜索應用程序的好處在更大的批量中最為普遍。 CPU 和 GPU 之間的性能差距很大,可以很容易地擴大規模。圖 3 顯示,對于批量大小為 10 的情況,當比較每秒的查詢數時,只有基于 RAFT 的索引是相關的。對于 10k 的批量大小(圖 4),CAGRA 迄今為止優于所有其他指數。
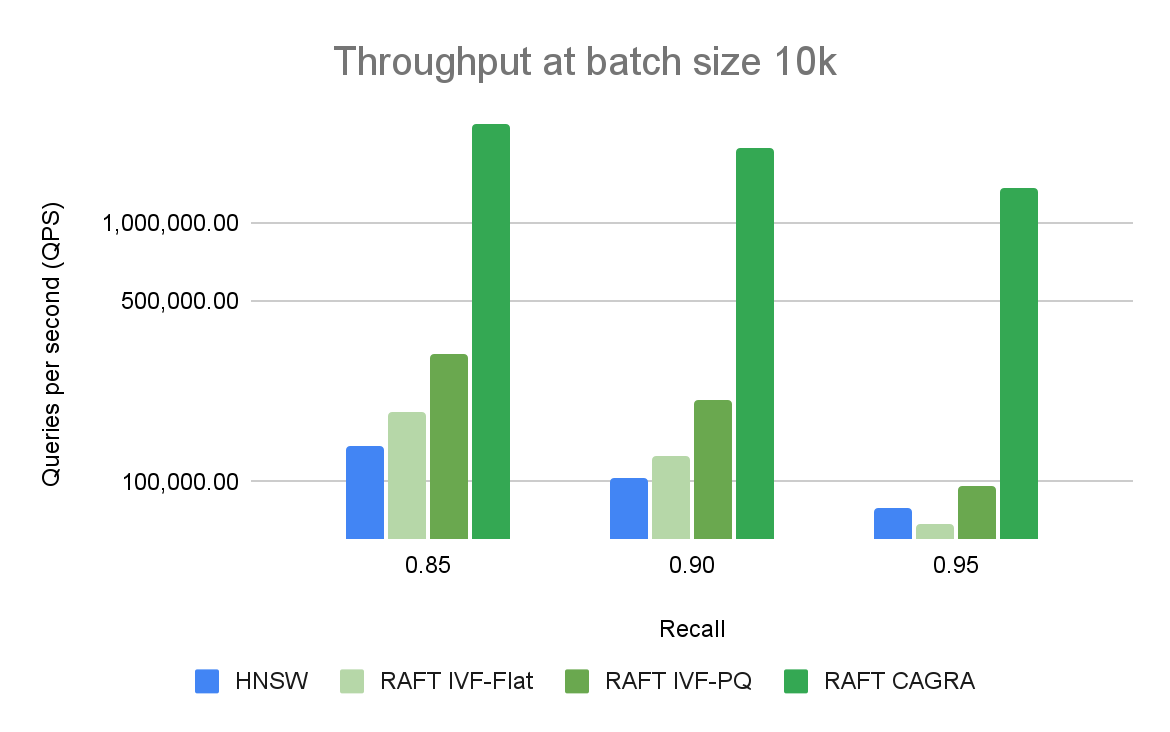
圖 4 將不同召回和吞吐量級別的 ANN 算法與批量大小為 10K 的查詢進行了比較。RAFT 的方法在所有實驗中都表現出比 HNSW 更高的吞吐量。
總結
每種不同的矢量搜索索引類型都有優缺點,最終取決于您的需求。這篇文章概述了其中的一些優點和缺點,簡要解釋了每種不同算法的工作原理,以及一些最重要的參數,這些參數可以用來權衡存儲成本、構建時間、搜索質量和搜索性能。在所有情況下, GPU 都可以提高索引構建和搜索性能。
RAPIDS RAFT 是完全開源的,可在 /rapidsai/raft GitHub 上獲取。您可以通過閱讀 文檔,運行 可復現的基準測試 套件,或基于示例矢量搜索 模板項目 來了解。此外,請務必在 Milvus、Redis 和 FAISS 中查找啟用 RAFT 索引的選項。最后,您可以在 Twitter 上關注我們 @rapidsai。









