我們很高興宣布 NVIDIA Quantization Aware Training ( QAT ) Toolkit for TensorFlow 2 目標是在 NVIDIA GPU 上使用 NVIDIA TensorRT 加速量化網絡。該工具包為您提供了一個易于使用的 API ,以一種優化的方式量化網絡,只需幾行額外的代碼即可進行 TensorRT 推理。
這篇文章伴隨著 走向 INT8 推理:使用 TensorRT 部署量化感知訓練網絡的端到端工作流 GTC 課程。有關 PyTorch 量化工具包等效工具,請參閱 PyTorch 量化 .
出身背景
加速深層神經網絡( DNN )推理是實現實時應用(如圖像分類、圖像分割、自然語言處理等)延遲關鍵部署的重要步驟。
改進 DNN 推理延遲的需要引發了人們對以較低精度運行這些模型的興趣,如 FP16 和 INT8 。在 INT8 精度下運行 DNN 可以提供比其浮點對應項更快的推理速度和更低的內存占用。 NVIDIA TensorRT 支持訓練后量化( PTQ )和 QAT 技術,將浮點 DNN 模型轉換為 INT8 精度。
在這篇文章中,我們討論了這些技術,介紹了用于 TensorFlow 的 NVIDIA QAT 工具包,并演示了一個端到端工作流,以設計最適合 TensorRT 部署的量化網絡。
量化感知訓練
QAT 背后的主要思想是通過最小化訓練期間的量化誤差來模擬低精度行為。為此,可以通過在所需層周圍添加量化和去量化( QDQ )節點來修改 DNN 圖。這使得量化網絡能夠將由于模型量化和超參數的微調而導致的 PTQ 精度損失降至最低。
另一方面, PTQ 在模型已經訓練之后,使用校準數據集執行模型量化。由于量化沒有反映在訓練過程中,這可能導致精度下降。圖 1 顯示了這兩個過程。
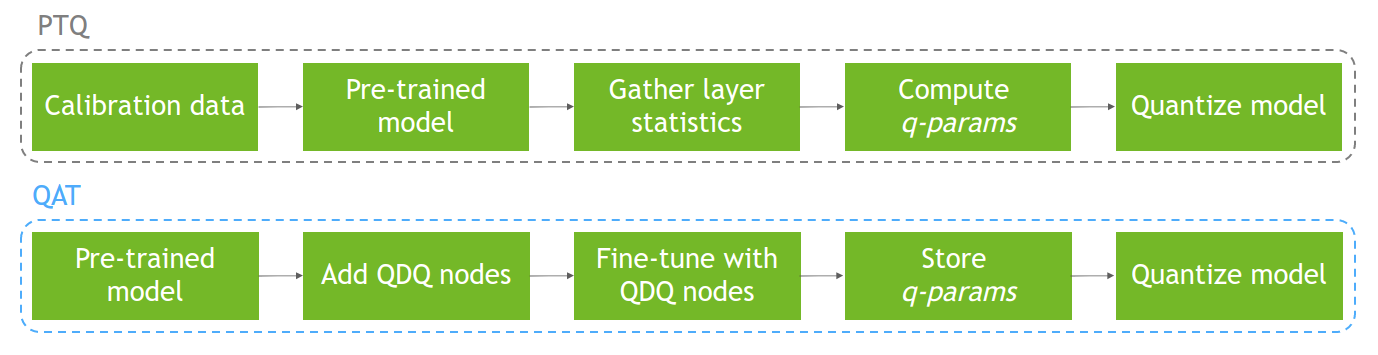
有關量化、量化方法( PTQ 與 QAT 相比)和 TensorRT 中量化的更多信息,請參閱 使用 NVIDIA TensorRT 的量化感知訓練實現 INT8 推理的 FP32 精度 。
用于 TensorFlow 的 NVIDIA QAT 工具包
該工具包的目標是使您能夠以最適合于 TensorRT 部署的方式輕松量化網絡。
目前, TensorFlow 在其開源軟件 模型優化工具包 中提供非對稱量化。他們的量化方法包括在所需層的輸出和權重(如果適用)處插入 QDQ 節點,并提供完整模型或部分層類類型的量化。這是為 TFLite 部署而優化的,而不是 TensorRT 部署。
需要此工具包來獲得一個量化模型,該模型非常適合 TensorRT 部署。 TensorRT optimizer 傳播 Q 和 DQ 節點,并通過網絡上的浮點操作將它們融合在一起,以最大化 INT8 中可以處理的圖形比例。這將導致 NVIDIA GPU 上的最佳模型加速。我們的量化方法包括在所需層的輸入和權重(如果適用)處插入 QDQ 節點。
我們還執行對稱量化( TensorRT 使用),并通過層名稱和 基于模式的層量化 的部分量化提供擴展量化支持。
表 1 總結了 TFMOT 和用于 TensorFlow 的 NVIDIA QAT 工具包之間的差異。
| Feature | TFMOT | NVIDIA QAT Toolkit |
| QDQ node placements | Outputs and weights | Inputs and weights |
| Quantization support | Whole model (full) and of some layers (partial by layer class) | Extends TF quantization support: partial quantization by layer name and pattern-based layer quantization by extending CustomQDQInsertionCase |
| Quantization op used | Asymmetric quantization (tf.quantization.fake_quant_with_min_max_vars) |
Symmetric quantization, needed for TensorRT compatibility (tf.quantization.quantize_and_dequantize_v2) |
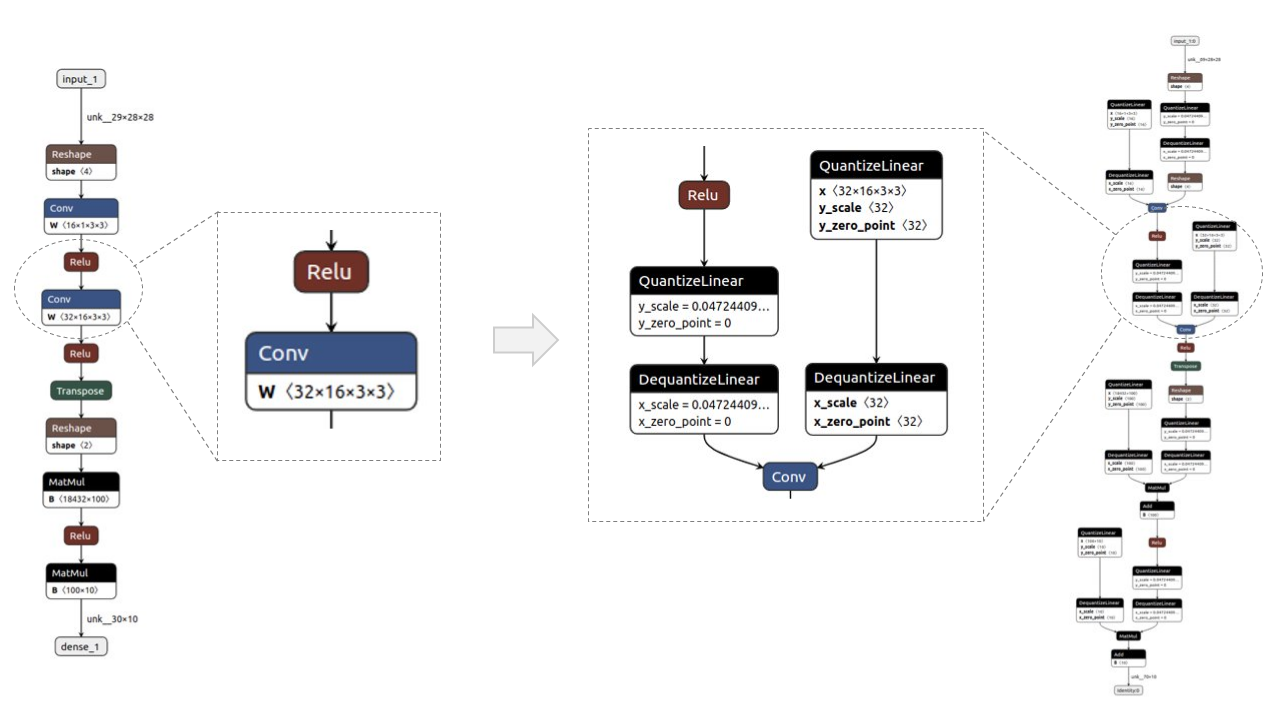
圖2顯示了一個簡單模型的前/后示例,用 ?Netron 可視化。QDQ節點放置在所需層的輸入和權重(如適用)中,即卷積(Conv)和完全連接(MatMul)。
TensorRT 中部署 QAT 模型的工作流
圖 3 顯示了在 TensorRT 中部署 QAT 模型的完整工作流,該模型是通過 QAT 工具包獲得的。

- 假設預訓練的 TensorFlow 2 模型為 SavedModel 格式,也稱為基線模型。
- 使用
quantize_model功能對該模型進行量化,該功能使用 QDQ 節點克隆并包裝每個所需的層。 - 微調獲得的量化模型,在訓練期間模擬量化,并將其保存為
SavedModel格式。 - 將其轉換為 ONNX 。
然后, TensorRT 使用 ONNX 圖來執行層融合和其他圖優化,如 專用 QDQ 優化 ,并生成一個用于更快推理的引擎。
ResNet-50v1 示例
在本例中,我們將向您展示如何使用 TensorFlow 2 工具包量化和微調 QAT 模型,以及如何在 TensorRT 中部署該量化模型。有關更多信息,請參閱完整的 example_resnet50v1.ipynb Jupyter 筆記本。
要求
要跟進,您需要以下資源:
- Python 3.8
- TensorFlow 2.8
- NVIDIA TF-QAT 工具包
- TensorRT 8.4
準備數據
對于本例,使用 ImageNet 2012 數據集 進行圖像分類(任務 1 ),由于訪問協議的條款,需要手動下載。 QAT 模型微調需要此數據集,它還用于評估基線和 QAT 模型。
登錄或注冊鏈接網站,下載列車/驗證數據。您應該至少有 155 GB 的可用空間。
工作流支持 TFRecord 格式,因此請使用以下說明(從 TensorFlow 說明 ) 轉換下載的。將 ImageNet 文件轉換為所需格式:
- set
IMAGENET_HOME=/path/to/imagenet/tar/filesin data/imagenet_data_setup.sh 。 - 將 imagenet_to_gcs.py 下載到
$IMAGENET_HOME。 - Run
./data/imagenet_data_setup.sh.
您現在應該可以在$IMAGENET_HOME中看到兼容的數據集。
量化和微調模型
from tensorflow_quantization import quantize_model from tensorflow_quantization.custom_qdq_cases import ResNetV1QDQCase # Create baseline model model = tf.keras.applications.ResNet50(weights="imagenet", classifier_activation="softmax") # Quantize model q_model = quantize_model(model, custom_qdq_cases=[ResNetV1QDQCase()]) # Fine-tune q_model.compile( optimizer="sgd", loss=tf.keras.losses.SparseCategoricalCrossentropy(), metrics=["accuracy"] ) q_model.fit( train_batches, validation_data=val_batches, batch_size=64, steps_per_epoch=500, epochs=2 ) # Save as TF 2 SavedModel q_model.save(“saved_model_qat”)
將 SavedModel 轉換為 ONNX
$ python -m tf2onnx.convert --saved-model=<path_to_saved_model> --output=<path_to_save_onnx_file.onnx> --opset 13
部署 TensorRT 發動機
將 ONNX 模型轉換為 TensorRT 引擎(還可以獲得延遲測量):
$ trtexec --onnx=<path_to_onnx_file> --int8 --saveEngine=<path_to_save_trt_engine> -v
獲取驗證數據集的準確性結果:
$ python infer_engine.py --engine=<path_to_trt_engine> --data_dir=<path_to_tfrecord_val_data> -b=<batch_size>
后果
在本節中,我們報告了 ResNet 和 EfficientNet 系列中各種型號的準確性和延遲性能數字:
- ResNet-50v1
- ResNet-50v2
- ResNet-101v1
- ResNet-101v2
- 效率網 -B0
- 效率網 -B3
所有結果都是在 NVIDIA A100 GPU 上獲得的,批次大小為 1 ,使用 TensorRT 8.4 ( EA 用于 ResNet , GA 用于 EfficientNet )。
圖 4 顯示了基線 FP32 模型與其量化等效模型( PTQ 和 QAT )之間的精度比較。正如您所見,基線模型和 QAT 模型之間的準確性幾乎沒有損失。有時,由于模型的進一步整體微調,精度甚至更高。由于 QAT 中模型參數的微調, QAT 的精度總體上高于 PTQ 。
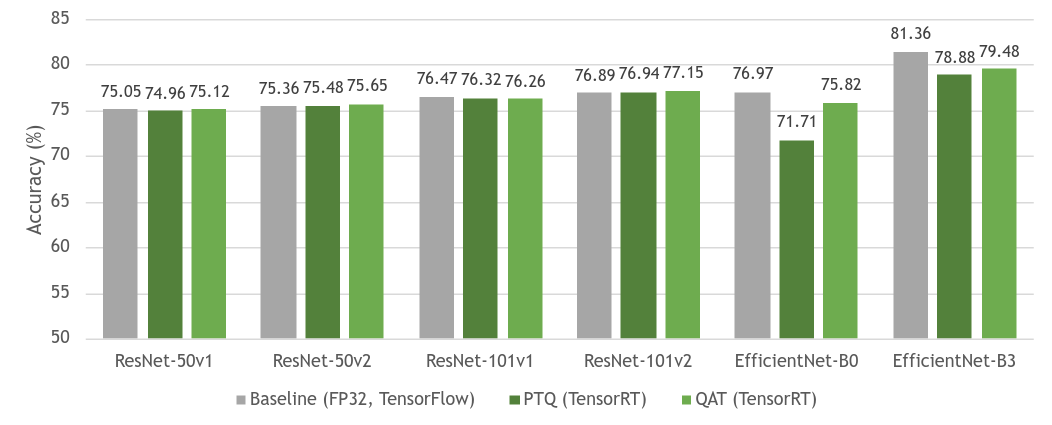
ResNet 作為一種網絡結構,一般量化穩定,因此 PTQ 和 QAT 之間的差距很小。然而, EfficientNet 從 QAT 中獲益匪淺,與 PTQ 相比,基線模型的準確度損失有所減少。
有關不同模型如何從 QAT 中受益的更多信息,請參見 深度學習推理的整數量化:原理與實證評價 (量化白皮書)中的表 7 。
圖 5 顯示了 PTQ 和 QAT 具有相似的時間,與各自的基線模型相比,它們引入了高達 19 倍的加速。
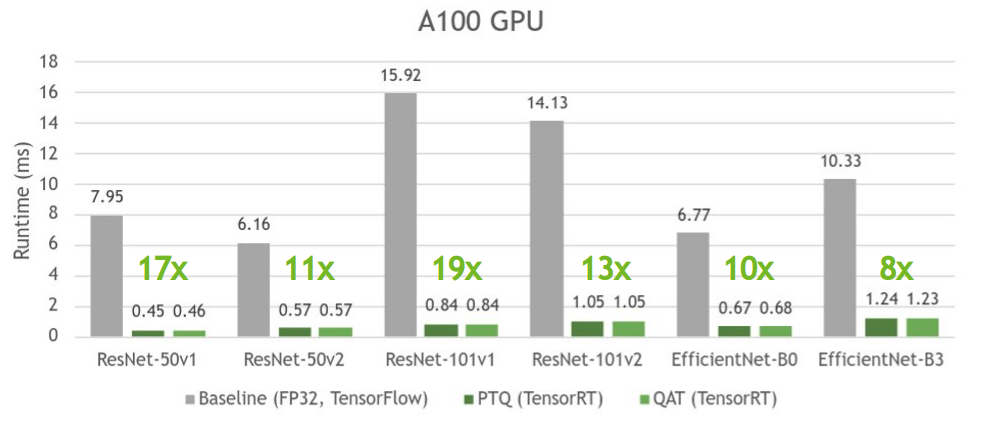
PTQ 有時可能比 QAT 略快,因為它試圖量化模型中的所有層,這通常會導致更快的推斷,而 QAT 僅量化用 QDQ 節點包裹的層。
有關 TensorRT 如何使用 QDQ 節點的更多信息,請參閱 TensorRT 文檔中的 使用 INT8 和 走向 INT8 推理:使用 TensorRT 部署量化感知訓練網絡的端到端工作流 GTC 會話。
有關各種受支持型號的性能數字的更多信息,請參閱 model zoo 。
結論
在本文中,我們介紹了 TensorFlow 2 的 NVIDIA QAT 工具包 . 我們討論了在 TensorRT 推理加速環境中使用該工具包的優勢。然后,我們演示了如何將該工具包與 ResNet50 結合使用,并對 ResNet 和 EfficientNet 數據集執行準確性和延遲評估。
實驗結果表明,與 FP32 模型相比,用 QAT 訓練的 INT8 模型的精度相差約 1% ,實現了 19 倍的延遲加速。
有關更多信息,請參閱以下參考資料:
- Toward INT8 Inference: An End-to-End Workflow for Deploying Quantization-Aware Trained Networks Using TensorRT GTC 會話
- 代碼存儲庫:
- NVIDIA TF-QAT 工具包 (本文討論)
- PyTorch 量化工具包 ( PyTorch 等效)
- 使用 TensorRT 和 ONNX 加速 DNNs :
- TensorFlow : 使用 TensorFlow 、 ONNX 和 NVIDIA TensorRT 加速深度學習推理
- PyTorch: 使用 NVIDIA TensorRT 加速深度學習推理(更新)
- 直接在 DL 框架中使用 TensorRT 加速 DNN :
- TensorFlow: 利用 TensorFlow- TensorRT 集成實現低延遲推理
- PyTorch: 使用 Torch TensorRT 將 PyTorch 中的推理速度提高到 6 倍
- 深度學習推理的整數量化:原理與實證評價
- 使用 NVIDIA TensorRT 的量化感知訓練實現 INT8 推理的 FP32 精度
- 使用 NVIDIA TensorRT 進行深度學習部署 (網絡研討會)
- 使用 NVIDIA TensorRT 使用 ONNX 模型和自定義圖層估計深度
?