隨著可用數據規模的不斷增長,對可擴展的智能數據處理系統的需求也在不斷增長,以快速利用有用的知識。尤其是在生命科學和金融等高風險領域,數據驅動流程的可擴展性和透明度對于確保高度可信賴至關重要。
Prometheux 是一家 NVIDIA 初創加速計劃公司,由來自牛津大學知識圖譜實驗室和維也納工業大學的科學家創立,致力于構建能夠解釋其精確邏輯過程的 AI.從 AstraZeneca 的藥物再利用到意大利中央銀行應用研究團隊的金融數據處理,Prometheux 技術為一些世界上最大的知識圖提供高度可擴展和可解釋的推理。
Prometheux 已利用 NVIDIA GPU無縫集成 適用于 Apache Spark 的 RAPIDS 加速器 到他們專有的知識圖管理系統 Vadalog 并行處理引擎。在處理包含數億實體和數十億關系的大型知識圖時,他們為客戶實現了顯著的加速并節省了成本。
知識圖和推理
在過去幾十年中,由于可用數據的規模不斷增長,大型企業知識圖的受歡迎程度迅速上升。用于利用這些知識圖的可擴展智能處理系統也相應增加。
知識圖可作為數據集成的支柱,并提供通用的表示結構,以支持跨大型數據源的查詢應答。A知識圖可定義為由以下內容組成的半結構化數據模型:
- 一個擴展組件:整合來自異構數據源的知識,包括現有的實體和關系。
- 一個密集型組件:領域知識,可以采用統計和 ML 模型的形式,也可以是以邏輯規則聲明方式定義的。
- 衍生的擴展組件:通過在所謂的推理過程中應用領域知識來生成擴展組件。
從復雜的公司所有權圖到蛋白質交互網絡,知識圖可為各種領域提供簡潔直觀的抽象概念,并可用于為真實世界的實體及其相互關系建模。
Vadalog Parallel
類似于人類智能中直覺和邏輯思維的相互作用,AI 也朝著神經符號是 ML 和基于邏輯的推理的協同組合。
Prometheux 面向神經符號 AI 構建,提供 Vadalog Parallel,這是其知識圖形管理系統 (KGMS),可提供演完全可解釋框架。此 KGMS 將數據與域邏輯相結合,并以高可擴展性和透明度為核心,自動處理大型知識圖形上的復雜推理任務。
Vadalog Parallel 充當異構企業數據源與基于這些數據源的應用程序之間的中間件。它充當數據集成的中堅力量,而無需遷移數據。在高級別對域邏輯進行編碼,可以快速開發全新的解決方案,而無需對大量代碼或設計算法進行編程。
Vadalog Parallel 提供與數據庫無關的兼容性,可無縫連接到所有主要數據庫(RDBMS、RDF 和 NoSQL,例如 Neo4j 和 Mongo 等)以及各種數據源(CSV、Parquet、JSON 等)。無論是處理元組、三元組還是n– 元組。
領域邏輯采用高級聲明編碼,使領域科學家能夠以自動化、可解釋和直觀的邏輯方式直接從大型知識圖形中提取見解,從而節省時間和計算資源。
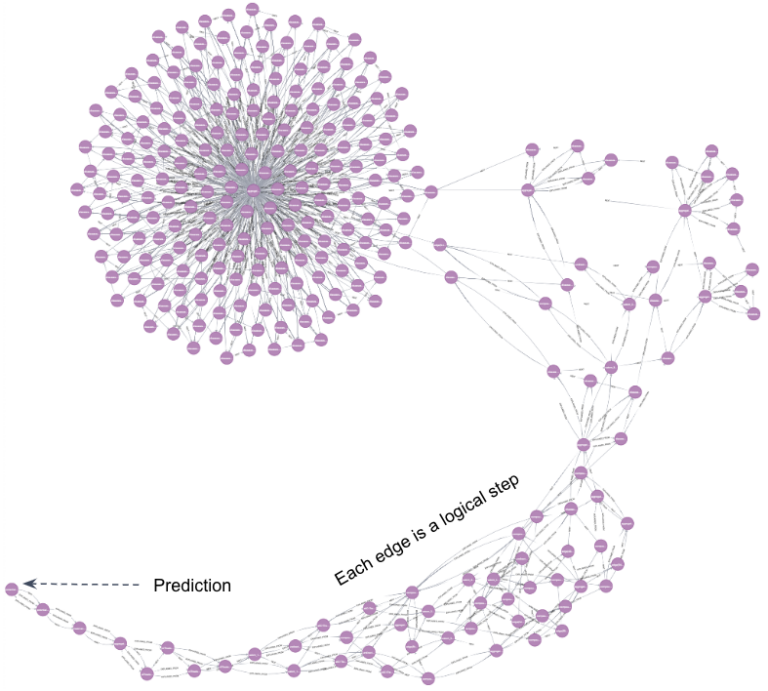
對于每項任務,Vadalog Parallel 都以原生方式提供推理過程的分步、邏輯完整解釋。以閃電般的速度計算出多達數十億個邏輯步驟,并伴隨一個緊湊的視覺解釋,以更快地與領域專家進行互動。
得益于其富有表現力的框架和分布式處理,Vadalog Parallel 在實踐中實現了較低的計算復雜性和可擴展性,并能夠使用高級數據分析功能對復雜領域進行建模。
事實上,它支持高效的圖形遍歷,并捕獲常規路徑查詢(用于使用模式匹配(例如 Cypher)導航圖形)和 OWL2 QL 機制下的 SPARQL (用于查詢語義網絡)。與其他先進系統不同,它支持反事實和時間推理、完全遞歸和存在量化,并且性能優于現有的大數據分析工具。
隨著數據集規模空前,我們對推理引擎的可擴展性和靈活性提出了新的要求,因此 AI 技術可以足夠快地執行。為了保證此類需求,Prometheux 精確地研究和開發了編譯技術,將經典推理、推理方法和工具轉移到大數據平臺上。
即使僅在 CPU 上運行,Vadalog Parallel 也已經實現了無與倫比的可擴展性。但是,在對一些世界上最大的知識圖(具有數億個實體和數十億個關系)進行推理時,GPU 成為不可或缺的資產。
可解釋的藥物再利用及其他用途
Vadalog Parallel 用于查找 各種應用 在計算生物學領域的研究成果,包括其對適應癥擴展的實際影響。
Prometheux 使生命科學組織能夠以自動化和邏輯可解釋的方式,以可擴展的方式推理大型生物(和其他類型的)知識圖。這有助于做出更明智的決策,并加快與領域專家的互動,從而加速全球流程開發,實現值得信賴的精準醫療。
通過對專有數據集和客戶數據集的自動化分析,Prometheux 通過邏輯推理揭示了隱藏的見解,并釋放了現有藥物用于新治療目的的潛力。通過以閃電般的速度計算數十億個邏輯步驟,Vadalog Parallel 生成了數百個成功驗證的適應癥(以及更多待研究的適應癥),有效地提供了一個動態和可解釋的推薦系統,用于適應癥擴展。
推薦內容的簡潔直觀解釋能夠加快與領域專家的互動,并能快速適應反饋,使每個人從最初的知識到新的適應癥,所需的時間比傳統技術快得多。
在以下各節中,我們還將為一系列推理任務提供 Vadalog Parallel 與 NVIDIA GPU 的實驗分析。我們使用 Prometheux 的內部試點生物知識圖 (BIO KG),這是尚未構建自己的知識圖的生命科學組織的起點。
BIO KG 擁有約 470 萬個數據點,涵蓋化合物、疾病、基因、生物途徑、癥狀等。Vadalog Parallel 借助 Spark RAPIDS 實現高達 9 倍的加速。
金融機構
Vadalog Parallel 的另一個引人注目的應用在金融和經濟的動態領域中展開。Prometheux 的知識圖形輔助方法可增強對金融實體之間復雜互聯的理解,無論這些實體是機構、公司、金融中介機構、其他類型的股東還是交易。
它可用于編碼國際法規的金融科技、RegTech、SupTech 和 InsurTech 應用程序以及其他領域邏輯。其目標是通過知識圖形自動推理,并實現 AI 輔助的銀行監督、合規性檢查、信用評估、反洗錢、欺詐檢測、沖擊傳播、公司控制、收購檢測等。
這種全面的方法使分析師能夠主動管理風險、應對挑戰、優化策略并促進財務穩定。
對于此領域,我們還展示了 Vadalog Parallel 在推理公司所有權圖(Company KG)時使用 NVIDIA GPU 的性能。
公司 KG 是一個綜合構建的知識圖譜,反映了 意大利公司的知名拓撲,其中公司和股東之間擁有 800 萬股的優勢關系。在這些圖譜中,Vadalog Parallel 借助 Spark RAPIDS 實現了高達 3 倍的加速。
策略和解決方案設計
Vadalog Parallel 架構具有以下關鍵組件,可在 Spark、Flink、GraphX 等分布式框架上高效執行推理任務:
- 規則解析
- 邏輯優化
- 查詢規劃
- 規劃器優化
- 查詢編譯
總體而言,Vadalog Parallel 公開了具有以下接口的推理 API:
reason(kg_ref,domain_logic)
客戶端應用程序向推理 API 發出調用,指定對知識圖的引用kg_refVadalog Parallel 連接并處理知識圖形庫,每個庫都有唯一的標識符 kg_ref.推理引擎編碼domain_logic轉換為一組分布式操作(窄、寬 transformation,即 shuffling),并計算推理任務的答案。它可以使用新知識擴展知識圖形,也可以在指定的輸出數據源中實現輸出。
為了確保更快速、更可靠的處理,Prometheux 已將 Spark-RAPIDS 無縫集成到 Vadalog Parallel 中,超越了傳統的 Spark 功能。
RAPIDS Shuffle Manager 是 Spark-rapids 不可或缺的一部分,通過引入交換 shuffle 數據的自定義機制提供了顯著優勢。這項創新提供了兩種不同的操作模式:多線程和 UCX,可配置為利用 GPU 到 GPU 通信和 RDMA 功能。它利用 Vadalog Parallel 為推理任務提供無與倫比的性能和效率水平。
場景和數據
如果沒有強大的遞歸,瀏覽圖形可能非常具有挑戰性。例如,標準 SQL 缺乏對遞歸的原生支持。
Vadalog Parallel 框架支持完全遞歸。在本文中,我們將展示如何通過 Spark-RAPIDS 集成 GPU 來顯著加速圖形遍歷和圖形分析任務。
我們將這些任務分為以下不同類型:
- 非遞歸:執行計劃的結構是一棵樹,其中每個分布式操作都只執行一次。
- 遞歸:執行計劃以圖形方式構建操作集,并應用分布式操作集,直至徹底探索知識圖譜。
在此過程中,我們使用遞歸運算對 NVIDIA Spark-RAPIDS 進行首次評估。
實驗結果
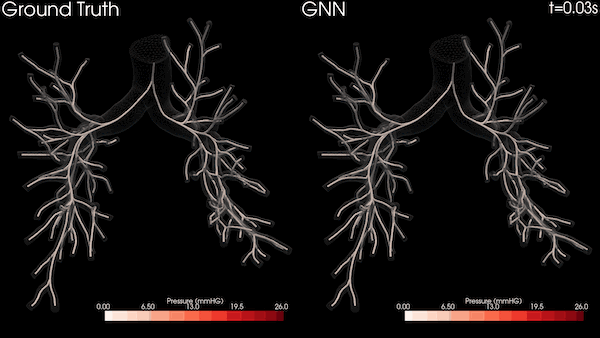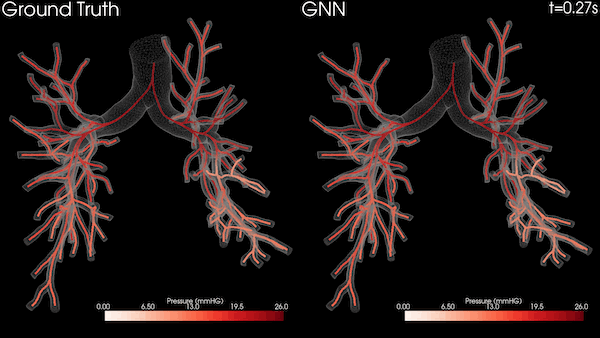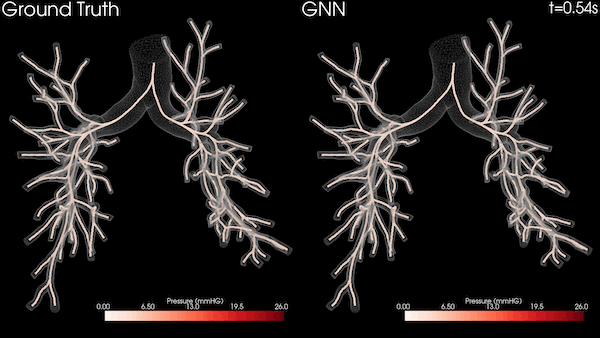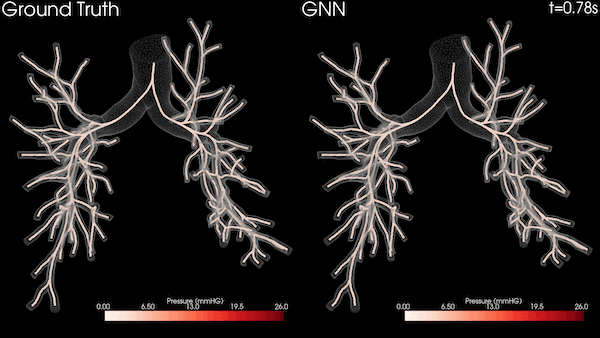
圖 3 顯示了四個包含遞歸和非遞歸運算的知識圖分析任務,其中兩個在 Bio KG 上,兩個在 Company KG 上。對于所有測量,我們對每個實驗運行了 10 次,并對結果求取了平均值。
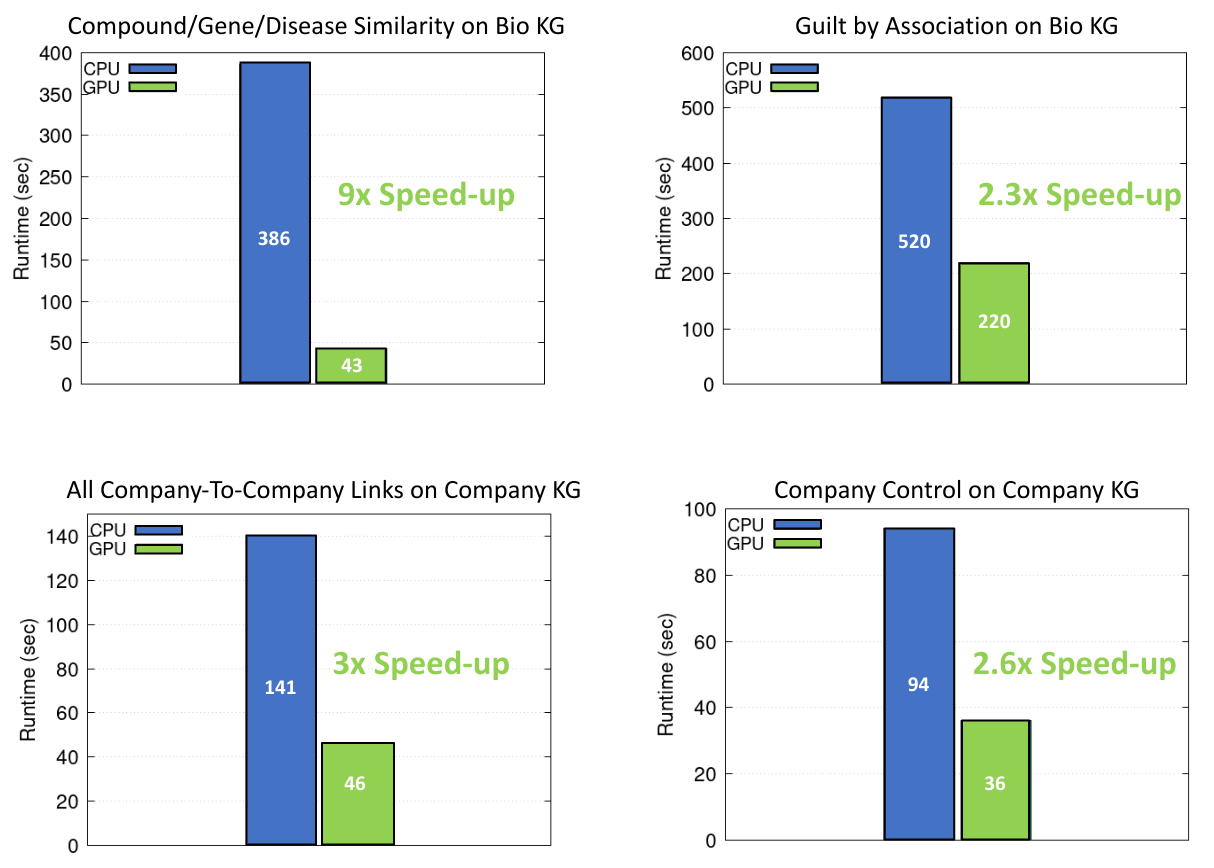
圖 3 顯示了之前介紹的知識圖中的四項推理任務。我們在提供相關實驗評估時特別關注使用 NVIDIA GPU 和 Spark RAPIDS 實現的加速。
硬件和軟件配置
在所有實驗分析中,Vadalog Parallel 均基于與 Spark-RAPIDS v23.08.1 集成并使用 CUDA v12.0 和 Java v8 作為 Spark 語言的 Spark 3.3.2 獨立集群執行。該集群本地安裝在 Amazon EC2 AMI p3.16 xlarge 上,具有 64 個 vCPU 8 GPU、480 GB RAM 和 8 個 NVIDIA V100 Tensor 核心,每個核心具有 16 GB GPU 核心內存。
測試設置
所有任務均需執行以下步驟:
- 調用 Vadalog Parallel 推理 API,在輸入中傳遞描述任務的領域邏輯以及對兩個知識圖之一的引用。
- 與 Spark 集群建立連接。
- 從特定知識圖中提取輸入子圖。
- 執行任務。
- 在 Parquet 文件中寫入輸出。
| KG | 邊緣 | 任務 | 說明 | 運營 | 推理時間(秒) |
生物 KG |
470 萬 |
化合物/基因/疾病相似性 | 根據常見特征確定基因、化合物和疾病的配對相似性 |
非遞歸寬轉換:3 個連接,3 個聚合; 非遞歸窄帶變換:3 個貼圖,3 個濾波器; |
CPU:386 GPU:43 |
生物 KG |
470 萬 |
關聯犯罪 |
根據治療一組類似疾病的相似化合物,為每種化合物推薦新的適應癥 |
非遞歸寬轉換:11 個連接,11 個聚合; 非遞歸窄帶轉換:52 個映射,26 個濾波器; |
CPU:520 GPU:220 |
公司 KG |
800 萬 |
所有公司間鏈接 |
確定所有節點之間的成對連接 |
非遞歸 Wide Transformation:1 聚合; 非遞歸窄帶變換:2 個映射,1 個濾波器; 遞歸寬轉換:1 個連接,2 個聚合; 遞歸窄帶變換:4 個貼圖,4 個濾鏡 |
CPU:141 GPU:46 |
公司 KG |
800 萬 |
公司控制 |
查找每家公司的所有控制器對 |
非遞歸寬轉換:2 次聚合; 非遞歸窄 transformation:2 個 Maps; 遞歸寬轉換:1 個連接,1 個聚合; 遞歸窄變換:1 張地圖 |
CPU:94 GPU:36 |
結束語
在本文中,我們討論了使用邏輯推理在大型企業知識圖以及用于利用這些知識的可擴展智能處理系統中的迅速普及。我們展示了 Prometheux 的知識圖管理系統 Vadalog Parallel.Vadalog Parallel 是一個強大的框架,可將數據與域邏輯結合起來,并自動執行復雜的推理任務。這是一種解決方案,推動我們朝著神經符號式 AI是 ML 和基于邏輯的推理的協同組合。
我們還討論了 Vadalog Parallel 在金融和生命科學領域的應用。在處理一些世界上最大的知識圖時,集成 RAPIDS 可利用 NVIDIA GPU 顯著加速并節省成本。
如需了解更多信息,請通過 Prometheux 的 LinkedIn 頁面聯系他們,或發送 電子郵件。有關 Spark 3.0 和 RAPIDS 的更多信息,請參閱 RAPIDS 開發者論壇。
?