NetworkX 在其文檔中指出,它是“… 用于創建、操作和研究復雜網絡的結構、動態和功能的 Python 軟件包”。自 2005 年首次公開發布以來,它已成為最受歡迎的 Python 圖形分析庫。這也許可以解釋為什么 NetworkX 僅在 2023 年 9 月就累計了 2700 萬 PyPI 下載量。
NetworkX 如何實現如此大規模的吸引力?是否有 NetworkX 不足的用例,如果是,可以做些什么來解決這些問題?我將在本文中探討這些問題以及更多內容。
NetworkX:輕松進行圖形分析
NetworkX 之所以在數據科學家、學生和許多對圖形分析感興趣的其他人中如此受歡迎,有幾個原因。NetworkX 是開源的,由一個龐大而友好的社區提供支持,他們渴望回答問題并提供幫助。代碼成熟且有據可查,軟件包本身易于安裝,不需要額外的依賴項。但最重要的是,NetworkX 擁有大量算法,通過易于使用的 API 涵蓋每個人的東西(包括繪圖!)。
只需幾行簡單的代碼,您就可以使用提供的任何算法加載和分析圖形數據。以下是找到簡單的四節點圖形的最短加權路徑的示例:
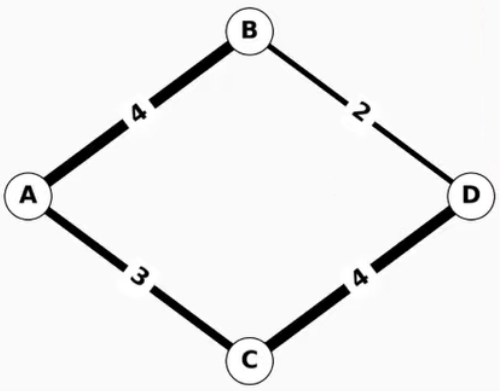
>>> import networkx as nx>>> G = nx.Graph()>>> G.add_edge("A", "B", weight=4)>>> G.add_edge("B", "D", weight=2)>>> G.add_edge("A", "C", weight=3)>>> G.add_edge("C", "D", weight=4)>>> nx.shortest_path(G, "A", "D", weight="weight")['A', 'B', 'D'] |
只需按 Python 提示輕松輸入幾行,即可交互式探索圖形數據。
缺少什么?
雖然 NetworkX 提供了開箱即用的大量可用性,但大中型網絡的性能和可擴展性遠遠沒有達到一流水平,并且會嚴重限制數據科學家的工作效率。
為了了解圖形大小和算法選項對運行時的影響,以下是一個有趣的分析,它回答了有關真實數據集的問題。
使用中間性中心審查有影響力的美國專利
該圖,由斯坦福網絡分析平臺 ( SNAP )提供,是一張顯示了 1975 年至 1999 年期間授予的專利的專利引文圖,這些專利共被引用了 16522438 次。如果您知道哪些專利比其他專利更重要,您可能會了解它們的相對重要性。
可以使用 pandas 庫處理引文圖形,以創建包含圖形邊緣的 DataFrame.DataFrame 有兩列:一列用于源節點,另一列用于每個邊緣的目標節點。然后,NetworkX 可以獲取此 DataFrame 并創建圖形對象,然后使用該對象運行介于中間性的中心位置。
間隔中心性是一個量化節點在多大程度上充當其他節點之間的媒介的指標,具體取決于節點所在最短路徑的數量。在專利引文的上下文中,它可用于衡量專利在多大程度上連接了其他專利。
使用 NetworkX,您可以betweenness_centrality找到這些中心專利。NetworkX 選擇k隨機節點,用于間隔核心計算所使用的最短路徑分析。k從而以增加計算時間為代價,獲得更準確的結果。
以下代碼示例加載引文圖形數據,創建 NetworkX 圖形對象,并運行 Betweenness_centrality.
################################################################################ Run Betweenness Centrality on a large citation graph using NetworkXimport sysimport timeimport networkx as nximport pandas as pdk = int(sys.argv[1])# Dataset from https://snap.stanford.edu/data/cit-Patents.txt.gzprint("Reading dataset into Pandas DataFrame as an edgelist...", flush=True, end="")pandas_edgelist = pd.read_csv( "cit-Patents.txt", skiprows=4, delimiter="\t", names=["src", "dst"], dtype={"src": "int32", "dst": "int32"},)print("done.", flush=True)print("Creating Graph from Pandas DataFrame edgelist...", flush=True, end="")G = nx.from_pandas_edgelist( pandas_edgelist, source="src", target="dst", create_using=nx.DiGraph)print("done.", flush=True)print("Running betweenness_centrality...", flush=True, end="")st = time.time()bc_result = nx.betweenness_centrality(G, k=k)print(f"done, BC time with {k=} was: {(time.time() - st):.6f} s") |
通過k運行代碼時,值為 10:
bash:~$ python nx_bc_demo.py 10Reading dataset into Pandas DataFrame as an edgelist...done.Creating Graph from Pandas DataFrame edgelist...done.Running betweenness_centrality...done, BC time with k=10 was: 97.553809 s |
如您所見,betweenness_centrality在一個中等大小的圖形上k=10而快速的現代 CPU (Intel Xeon Platinum 8480CL)幾乎需要 98 秒。要實現更高水平的準確性以符合您對這種規模的圖形的期望,就需要大幅提高k但是,這將導致運行時間更長,正如本文稍后的基準測試結果中所強調的那樣,執行時間會延長到幾個小時。
RAPIDS cuGraph:速度和 NetworkX 互操作性
創建 RAPIDS cuGraph 項目的目的是為了彌補基于 GPU 的快速、可擴展的圖形分析與 NetworkX 易用性之間的差距。如需了解更多信息,請參閱 RAPIDS cuGraph 增加了 NetworkX 和 DiGraph 兼容性。
cuGraph 在設計時就考慮到了 NetworkX 互操作性,這一點在您僅替換betweenness_centrality使用 cuGraph 的betweenness_centrality并保留代碼的其余部分。
因此,只需更改幾行代碼,即可將速度提高 12 倍以上:
################################################################################ Run Betweenness Centrality on a large citation graph using NetworkX# and RAPIDS cuGraph.# NOTE: This demonstrates legacy RAPIDS cuGraph/NetworkX interop. THIS CODE IS# NOT PORTABLE TO NON-GPU ENVIRONMENTS! Use nx-cugraph to GPU-accelerate# NetworkX with no code changes and configurable CPU fallback.import sysimport timeimport cugraph as cgimport pandas as pdk = int(sys.argv[1])# Dataset from https://snap.stanford.edu/data/cit-Patents.txt.gzprint("Reading dataset into Pandas DataFrame as an edgelist...", flush=True, end="")pandas_edgelist = pd.read_csv( "cit-Patents.txt", skiprows=4, delimiter="\t", names=["src", "dst"], dtype={"src": "int32", "dst": "int32"},)print("done.", flush=True)print("Creating Graph from Pandas DataFrame edgelist...", flush=True, end="")G = cg.from_pandas_edgelist( pandas_edgelist, source="src", destination="dst", create_using=cg.Graph(directed=True))print("done.", flush=True)print("Running betweenness_centrality...", flush=True, end="")st = time.time()bc_result = cg.betweenness_centrality(G, k=k)print(f"done, BC time with {k=} was: {(time.time() - st):.6f} s") |
當您在同一臺機器上使用相同的k值,您可以看到它的速度提高了 12 倍以上:
bash:~$ python cg_bc_demo.py 10Reading dataset into Pandas DataFrame as an edgelist...done.Creating Graph from Pandas DataFrame edgelist...done.Running betweenness_centrality...done, BC time with k=10 was: 7.770531 s |
此示例很好地展示了 cuGraph 與 NetworkX 的互操作性。但是,在將 cuGraph 添加到代碼中時,有些實例需要您做出更重大的更改。
許多差異都是有意的(出于性能原因,不同的選項可以更好地映射到 GPU 實現,不支持的選項等),而另一些則是不可避免的(cuGraph 實施的算法較少,cuGraph 需要 GPU,等等)。這些差異需要您添加特殊情況代碼來轉換選項,或者檢查代碼是否在 cuGraph 兼容的系統上運行,如果它們打算支持沒有 GPU 或 cuGraph 的環境,則調用等效的 NetworkX API.
cuGraph 本身是一個易于使用的 Python 庫,但它并不打算取代 NetworkX.
與此同時,NetworkX 增加了調度 … …
NetworkX 最近增加了向第三方提供的不同分析后端分配 API 調用的功能。這些后端可以為各種 NetworkX API 提供替代實現,從而大大提高性能。
后端可以通過backend=keyword支持的 API 上的參數,或者通過設置NETWORKX_AUTOMATIC_BACKENDS環境變量。
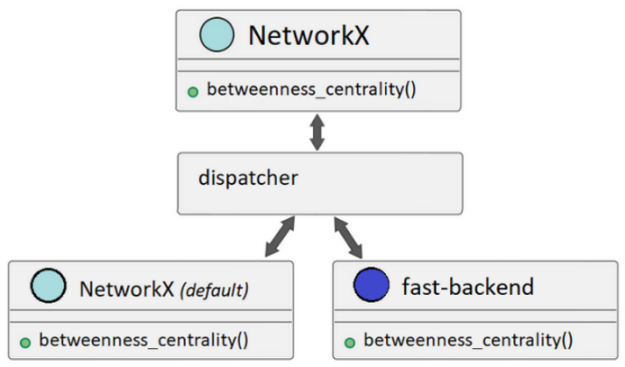
如果發出了 NetworkX API 調用,但后端無法支持該調用,則可以將 NetworkX 配置為引發信息性錯誤或自動回退到其默認實現以滿足調用要求(圖 2)。
即使后端已安裝且可用,如果您未指定要使用的一個或多個后端,NetworkX 也會使用默認實現。
通過使其他圖形庫能夠通過后端輕松擴展 NetworkX,NetworkX 成為標準的圖形分析前端。這意味著更多用戶可以使用其他圖形庫的功能,而無需使用與新庫相關的學習曲線和集成時間。
庫維護人員還可以從 NetworkX 調度中受益,因為他們可以覆蓋更多用戶,而不會產生維護面向用戶的 API 的開銷。相反,他們可以專注于提供后端。
使用 nx-cugraph 的 GPU 加速 NetworkX
NetworkX 調度為 RAPIDS cuGraph 團隊創建 nx-cugraph 打開了大門,nx – cugraph 是一個新項目,基于 RAPIDS cuGraph 提供的圖形分析引擎為 NetworkX 添加了后端。
此方法還可減少 nx-cugraph 的依賴項,并避免 cuGraph Python 庫添加的代碼路徑,從而與 RAPIDS cuDF 進行高效集成,而 NetworkX 不需要這樣做。
借助 nx-cugraph,NetworkX 用戶最終可以獲得一切:易用性、GPU 和非 GPU 環境之間的可移植性以及性能,所有這些都無需更改代碼。
但也許最棒的是,您現在可以通過添加 GPU 和 nx-cugraph 來解鎖以前因運行時間過長而不實際的用例。有關更多信息,請參閱本文后面的基準測試部分。
安裝 nx-cugraph
假設已安裝 NetworkX 3.2 或更高版本,則可以使用 conda 或 pip 安裝 nx-cugraph.
conda
conda install -c rapidsai-nightly -c conda-forge -c nvidia nx-cugraph |
pip
python -m pip install nx-cugraph-cu11 --extra-index-url https://pypi.nvidia.com |
Nightly wheel 構建在 23.12 版本之前不可用,因此穩定版本的索引 URL 將用于pip install命令。
有關安裝任何 RAPIDS 包的更多信息,請參閱 快速本地安裝。
使用 nx-cugraph 重溫 NetworkX 間隔中心性
當您安裝 nx-cugraph 并指定 cugraph 后端時,NetworkX 會分配betweenness_centrality調用 nx-cugraph.您無需更改代碼即可了解 GPU 加速的優勢。
以下運行是在本文后面的基準測試部分中使用的同一系統上完成的。這些演示也不包括熱身運行,這可以提高性能,但稍后展示的基準測試確實做到了。
以下是在 k=10 的情況下,在美國專利數據集上運行的初始 NetworkX:
bash:~$ python nx_bc_demo.py 10Reading dataset into Pandas DataFrame as an edgelist...done.Creating Graph from Pandas DataFrame edgelist...done.Running betweenness_centrality...done, BC time with k=10 was: 97.553809 s |
在不更改代碼的情況下,設置環境變量NETWORKX_AUTOMATIC_BACKENDS使用 nx-cugraphbetweenness_centrality運行并觀察速度提升 6.8 倍:
bash:~$ NETWORKX_AUTOMATIC_BACKENDS=cugraph python nx_bc_demo.py 10Reading dataset into Pandas DataFrame as an edgelist...done.Creating Graph from Pandas DataFrame edgelist...done.Running betweenness_centrality...done, BC time with k=10 was: 14.286906 s |
更大k值會導致默認 NetworkX 實現速度顯著放緩:
bash:~$ python nx_bc_demo.py 50Reading dataset into Pandas DataFrame as an edgelist...done.Creating Graph from Pandas DataFrame edgelist...done.Running betweenness_centrality...done, BC time with k=50 was: 513.636750 s |
在相同的位置使用 cugraph 后端k值將導致速度提升 31 倍:
bash:~$ NETWORKX_AUTOMATIC_BACKENDS=cugraph python nx_bc_demo.py 50Reading dataset into Pandas DataFrame as an edgelist...done.Creating Graph from Pandas DataFrame edgelist...done.Running betweenness_centrality...done, BC time with k=50 was: 16.389574 s |
如你所見,當你增加k您會看到加速增加。越大k由于 GPU 具有很高的并行處理能力,因此在使用 cugraph 后端時,值對運行時的影響很小。
事實上,您可以使用k在與整體運行時間幾乎沒有區別的情況下提高準確性:
bash:~$ NETWORKX_AUTOMATIC_BACKENDS=cugraph python nx_bc_demo.py 500Reading dataset into Pandas DataFrame as an edgelist...done.Creating Graph from Pandas DataFrame edgelist...done.Running betweenness_centrality...done, BC time with k=500 was: 18.673590 s |
設置k如果使用默認的 NetworkX 實現需要一個多小時,但如果使用 cugraph 后端,則只需幾秒鐘。有關更多信息,請參閱下一節基準測試。
基準測試
使用以下數據集和系統硬件配置,使用和不使用 nx-cugraph 的 NetworkX 基準測試結果如表 1-3 所示:
- 數據集:定向圖形,包含 370 萬個節點和 1650 萬個邊緣
- CPU: 英特爾 Xeon Platinum 8480CL,2TB
- GPU: NVIDIA H100,80GB
這些基準測試使用 pytest 和 pytest-benchmark 插件運行。每次運行都包括 NetworkX 和 nx-cugraph 的熱身步驟,可提高測量運行的性能。
基準測試代碼可以在 cuGraph Github 庫 中找到。
nx.betweenness_centrality(G, k=k)
| ? | k=10 | k=20 | k=50 | k=100 | k=500 | k=1000 |
| NetworkX | 97.28 秒 | 184.77 秒 | 463.15 秒 | 915.84 秒 | 4585.96 秒 | 9125.48 秒 |
| nx-cugraph | 8.71 秒 | 8.26 秒 | 8.91 秒 | 8.67 秒 | 11.31 秒 | 14.37 秒 |
| 加速 | 1117 倍 | 22.37 倍 | 51.96 倍 | 105.58 倍 | 405.59 X | 634.99 X |
nx.edge_betweenness_centrality(G, k=k)
| ? | k=10 | k=20 | k=50 | k=100 | k=500 | k=1000 |
| NetworkX | 112.22 秒 | 211.52 秒 | 503.57 秒 | 993.15 秒 | 4937.70 秒 | 9858.11 秒 |
| nx-cugraph | 19.62 秒 | 19.93 秒 | 21.26 秒 | 22.48 秒 | 41.65 秒 | 57.79 秒 |
| 加速 | 5.72 倍 | 10.61 倍 | 23.69 倍 | 44.19 倍 | 118.55 倍 | 170.59 倍 |
nx.community.louvain_communities(G)
| NetworkX | 2834.86 秒 |
| nx-cugraph | 21.59 秒 |
| 加速 | 131.3 倍 |
結束語
NetworkX 調度是 NetworkX 演變的新篇章,這將使更多用戶在以前不可行的用例中采用 NetworkX.
可互換的第三方后端使 NetworkX 成為標準化的前端,您無需再重寫 Python 代碼以使用不同的圖形分析引擎。nx-cugraph 將基于 cuGraph 的 GPU 加速和可擴展性直接添加到 NetworkX,因此您最終可以在不更改代碼的情況下從 NetworkX 獲得所缺少的速度和可擴展性。
由于 NetworkX 和 nx-cugraph 都是開源項目,因此歡迎提供反饋、建議和貢獻。如果您想看到一些內容,例如 nx – cugraph 中的特定算法或其他可調度的 NetworkX API,請在適當的 GitHub 項目中留下建議:
如果您想詳細了解如何使用 nx-cugraph 在 GPU 上加速 NetworkX,請注冊參加 AI 和數據科學虛擬峰會。
?