加載時長。它們是任何試圖構建無縫體驗的開發人員的禍根。在游戲中試圖通過迫使玩家在狹窄的通道中搖擺或乘坐極慢的電梯來隱藏負載,會破壞沉浸感。
現在,開發人員有了更好的解決方案。 NVIDIA 與 Microsoft 和 IHV 合作伙伴合作,為 DirectStorage 1.1 開發了 GDeflate ,這是 GPU 壓縮的開放標準。當前的 Game Ready Driver (版本 526.47 )包含 NVIDIA RTX IO 技術,包括對 GDeflate 的優化。
GDeflate :開放式 GPU 壓縮標準
GDeflate 是一種高性能、可擴展、 GPU 優化的數據壓縮方案,可以幫助應用程序利用現代 NVMe 設備上的大量數據吞吐量。它通過消除整個 I / O 管道中的 CPU 瓶頸,使此類設備的流解壓縮變得切實可行。 GDeflate 還提供帶寬放大效果,進一步提高 I / O 子系統的有效吞吐量。
GDeflate 開源將在 GitHub 上發布,并為 IHV 和 ISV 提供許可證。我們希望鼓勵快速采用 GDeflate 作為數據并行壓縮標準,促進其在 PC 生態系統和其他平臺上的應用。
為了顯示 GDeflate 的好處,我們在一個代表性的游戲數據集上測量了系統性能,該數據集包含紋理和幾何數據,在沒有壓縮的情況下,使用標準 CPU 側解壓縮,以及使用 GPU 加速的 GDeflate 解壓縮。
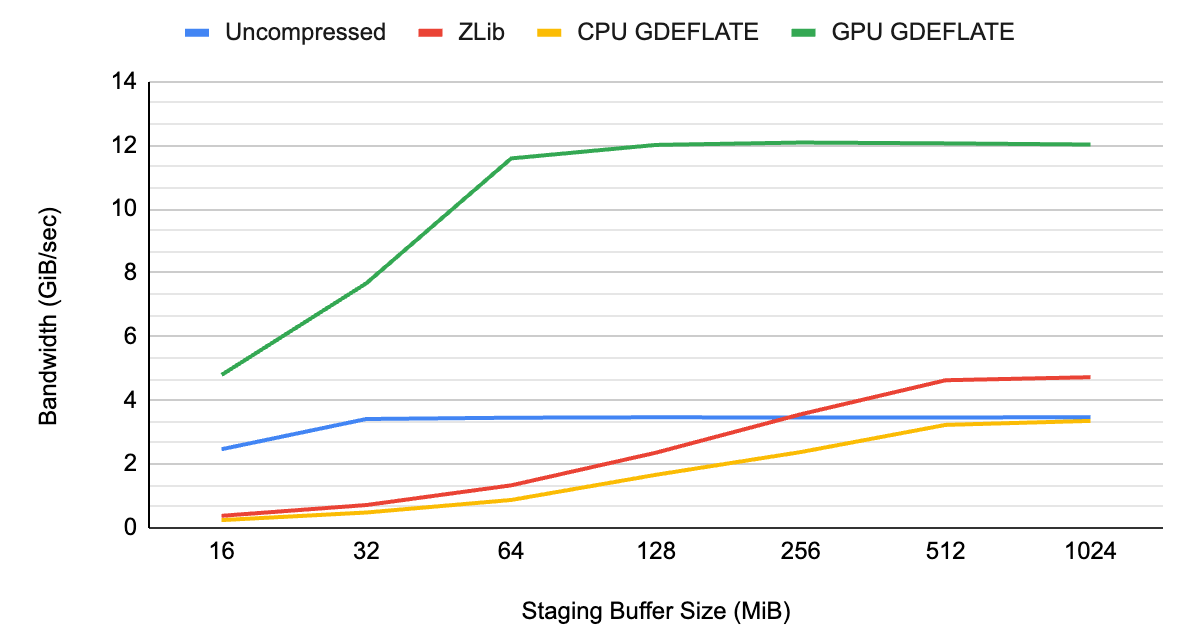
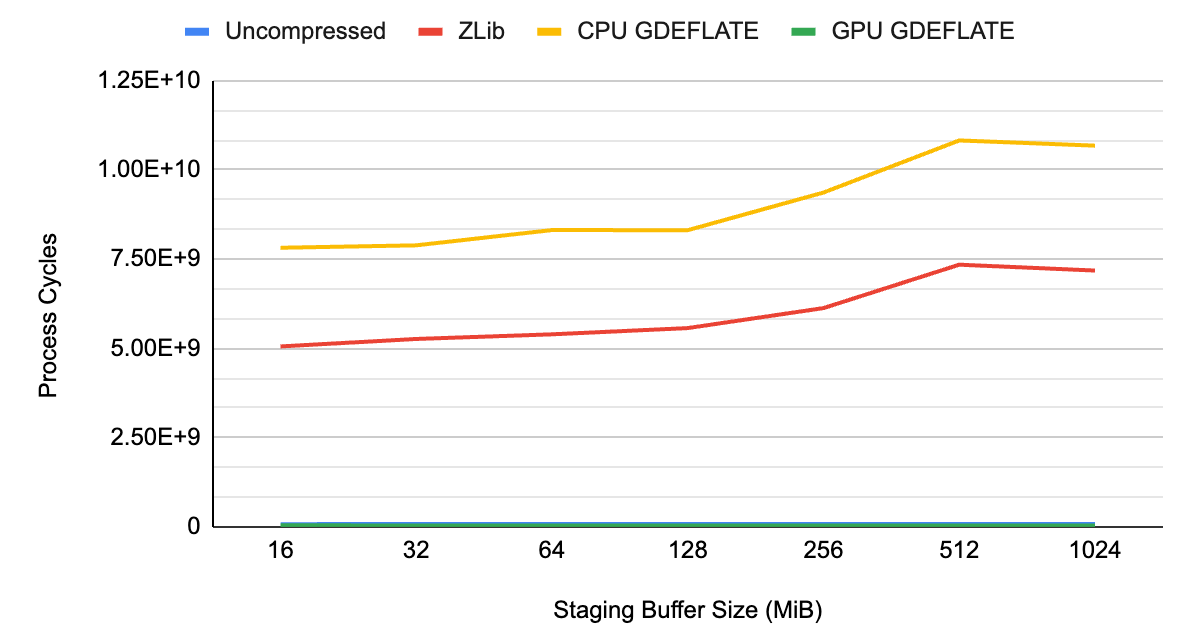
如圖 1 和圖 2 所示,未壓縮流的數據吞吐量受到系統總線帶寬的限制,大約為~ 3 GB / s ,這恰好是 Gen3 PCIe 互連的限制。
當在 CPU 上應用傳統壓縮和解壓縮時, CPU 會成為整體瓶頸,導致吞吐量低于未壓縮流的吞吐量。它不僅沒有充分利用系統的可用 I / O 資源,而且還占用了其他需要 CPU 資源的任務的 CPU 周期。
通過 GPU 加速的 GDeflate 解壓縮,系統可以在不應用壓縮的情況下提供超出可能范圍的有效帶寬。它有效地將數據吞吐量乘以壓縮比。 CPU 仍然完全可用于執行其他重要任務,最大限度地提高系統級性能。
GDeflate 在 DirectStorage 1.1 中作為標準 GPU 解壓縮選項提供, DirectStorage 1.1 是一個來自 Microsoft 的現代 I / O 流 API 。我們期待著下一代游戲引擎通過大幅減少加載時間而從 GDeflate 中受益。
資源流和數據壓縮
如今的視頻游戲具有極其詳細的交互環境,需要管理巨大的資產。這些數據必須首先傳送到最終用戶的系統,然后在運行時主動流式傳輸到 GPU 進行處理。游戲內容包的大部分由自然針對 GPU 的資源組成:紋理、材質和幾何數據。
傳統的數據壓縮技術適用于很少改變的游戲內容。例如,當玩家進入游戲關卡時,僅編寫一次的紋理可能需要加載多次。這些資產通常在打包分發時被壓縮,在游戲進行時按需解壓縮。將壓縮應用于游戲資產以減少可下載內容的大小(及其安裝占用空間)已成為標準做法。
然而,大多數數據壓縮方案是為 CPU 設計的,并假定串行執行語義。事實上,數據壓縮過程通常用基本上串行的術語來描述:在尋找冗余或重復模式的同時,對數據流進行串行掃描。它用對這些模式先前出現的引用來替換這些模式的多次出現。因此,此類算法無法輕松擴展到數據并行架構,也無法滿足現代游戲內容所要求的更快解壓縮速率的需求。
同時, I / O 技術的最新進展極大地提高了終端用戶系統上的可用 I / O 帶寬。消費者系統通常配備 PCIe Gen3 或 Gen4 NVMe 設備,能夠提供高達 7 GB / s 的數據帶寬。
從這個角度來看,按照這個速度,高端 NVIDIA GeForce RTX 4090 GPU 上的 24 GB 幀緩沖存儲器可以在 3 秒鐘內填滿!
為了跟上這些系統級 I / O 速度的提高,我們需要在數據壓縮技術方面取得巨大進步。在這些速率下,在最終用戶的系統上使用 CPU 進行數據解壓縮不再可行。這需要在這項輔助任務上花費大量寶貴的 CPU 周期。它還可能降低整個系統的速度。
CPU 不應該成為阻礙 I / O 子系統的瓶頸。
數據并行解壓縮和 GDeflate 架構
隨著摩爾定律的終結,我們再也不能指望從串行處理器中獲得“免費”的性能改進。
高性能系統長期以來一直采用大規模數據并行,以繼續擴展許多應用程序的性能。另一方面,傳統數據壓縮算法的并行化一直是一個挑戰,因為基本的串行假設“烘焙”到了它們的設計中。
我們需要的是一種 GPU 友好的數據壓縮方法,它可以隨著 GPU 變得更寬和更并行而擴展性能。
這就是我們開始用 GDeflate 解決的問題,這是一種針對高通量 GPU 解壓縮優化的新型數據并行壓縮方案。我們設計 GDeflate 的目標如下:
- 高性能 GPU 優化解壓縮以支持最快的 NVMe 設備
- 卸載 CPU 以避免其成為 I / O 操作期間的瓶頸
- 可移植到各種數據并行架構,包括 CPU 和 GPU
- 可以使用現有 IP 在固定功能硬件中廉價實現
- 建立數據并行數據壓縮標準
正如您可以從名稱中猜到的那樣, GDeflate 建立在公認的 RFC 1951 DEFLATE 算法的基礎上,對其進行擴展和調整,以適應數據并行處理。盡管存在更復雜的壓縮方案,但原始 DEFLATE 數據編碼的簡單性和健壯性使其成為高度優化的基于 GPU 的實現的一個吸引人的選擇。
DEFLATE 的現有固定函數實現也可以很容易地進行調整,以支持 GDeflate ,從而提高兼容性和性能。
兩級并行
多核 SIMD 機器在設計上消耗 GDeflate 比特流,顯式地暴露兩個級別的并行性。
首先,原始數據流被分割成 64KB 的塊,這些塊被獨立處理。這種粗粒度分解提供了線程級并行性,使多個瓦片能夠在目標處理器的多個內核上并發處理。這也使得能夠以瓦片粒度隨機訪問壓縮數據。例如,流引擎可以請求根據給定幀的所需工作集來解壓縮稀疏瓦片集。
此外, 64 KB 恰好是圖形 API ( DirectX 和 Vulkan )中平鋪或稀疏資源的標準平鋪大小,這使得 GDeflate 與利用這些 API 功能的未來點播流架構兼容。
其次,瓦片內的比特流被專門格式化,以暴露更細粒度的 SIMD 級并行性。我們預計,一組協作線程將處理單個瓦片,因為該組可以使用硬件加速數據并行操作直接解析 GDeflate 比特流,這在大多數 SIMD 架構上都是可用的。
SIMD 組中的所有線程共享解壓縮狀態。比特流的格式被精心構造以實現對壓縮數據的高度優化的協作處理。
這種兩級并行化策略使 GDeflate 實現能夠在廣泛的數據并行架構中輕松擴展,同時為支持未來甚至更廣泛的數據平行機提供了必要的空間,而不會影響解壓縮性能。
NVIDIA RTX IO 支持 DirectStorage 1.1
NVIDIA RTX IO 現在包含在當前的 Game Ready 驅動程序(版本 526.47 )中,它提供了加速的解壓縮吞吐量。
DirectStorage 和 RTX IO 都利用了 GDeflate 壓縮標準。
“微軟很高興與 NVIDIA 合作,為 Windows 游戲玩家帶來下一代 I / O 的好處。 DirectStorage for Windows 將使游戲能夠利用 NVIDIA 的尖端 RTX IO ,并為游戲開發者提供一種高效、標準的方法,以從 GPU 中獲得最佳性能和 I / O 系統。使用 DirectStorage ,游戲大小最小化,加載時間縮短,虛擬世界可以自由地變得更廣闊和更詳細,流媒體流暢無縫。”
Bryan Langley , Windows 圖形和游戲組項目經理
RTX IO 驅動程序中的 DirectStorage 入門
我們還有一些建議可以幫助確保在 NVIDIA GPU 上使用 DirectStorage 和 GPU 解壓縮的最佳體驗。
為 DirectStorage 準備應用程序
使用具有 GPU 解壓縮的 DirectStorage 實現最大端到端吞吐量需要將足夠數量的讀取請求排隊,以保持管道完全飽和。
在準備 DirectStorage 集成時,應用程序應及時將資源 I / O 和創建請求分組在一起。理想情況下,資源 I / O 和創建操作發生在自己的 CPU 線程中,與執行其他加載屏幕活動(如著色器創建)的線程分開。
磁盤上的資產也應該打包成足夠大的塊,以便將 DirectStorage API 調用頻率保持在最低水平,并將 CPU 成本降至最低。這確保可以向 DirectStorage 提交足夠的工作,以保持管道完全飽和。
有關一般最佳實踐的更多信息,請參見 Using DirectStorage 和 DirectStorage 1.1 Now Available Microsoft 帖子。
決定暫存緩沖區大小
- 確保在使用 GPU 解壓縮時更改默認的暫存緩沖區大小。當前的 32 MB 默認值不足以使現代 GPU 功能飽和。
- 在決定暫存緩沖區大小時,請確保對具有不同 NVMe 、 PCIe 和 GPU 功能的不同平臺進行基準測試。我們發現 128-MB 的暫存緩沖區大小是合理的默認值。較小的 GPU 可能需要更少,較大的 GPU 則可能需要更多。
壓縮比注意事項
- 確保測量不同資源類型對壓縮節省和 GPU 解壓縮性能的影響。
- 通常,各種數據類型(如紋理和幾何體)以不同的比率壓縮。這可能導致 GPU 解壓縮執行性能的一些變化。
- 這不會對端到端吞吐量產生重大影響。然而,當將資源內容傳遞到其最終位置時,這可能導致延遲的變化。
Windows 文件系統
- 嘗試將 DirectStorage 訪問的磁盤文件與其他 I / O API 訪問的文件分開。跨不同 I / O API 的共享文件使用可能會導致旁路 I / O 改進的丟失。
后臺流時的命令隊列調度
- 在 Windows 10 中,命令隊列調度爭用可能發生在 DirectStorage 復制和計算命令隊列以及應用程序管理的復制和計算指令隊列之間。
- NVIDIA Nsight Systems 、 PIX 和 GPUView 工具可以幫助確定 DirectStorage 的后臺流是否與重要的應用程序管理的命令隊列發生沖突。
- 在 Windows 11 中, DirectStorage 和應用程序命令隊列之間的重疊執行是完全預期的。
- 如果重疊執行導致應用程序工作負載的性能不理想,我們建議限制 DirectStorage 讀取。這有助于在后臺流傳輸時保持關鍵的應用程序性能。
總結
下一代游戲引擎需要大量的數據流,旨在創建越來越真實、詳細的游戲世界。鑒于此,有必要重新思考游戲引擎的資源流架構,并充分利用 I / O 技術的改進。
使用 GPU 作為計算密集型加速器,數據解壓縮對于最大化系統性能和減少加載時間至關重要。
GDeflate 的 NVIDIA RTX IO 實現是一種可擴展的 GPU 優化壓縮技術,使應用程序能夠從 GPU 的 I / O 加速計算能力中獲益。它可以作為帶寬放大器,實現當今和未來系統的高性能 I / O 功能。
?