NVIDIA 最近發布了 cuEmbed,這是一個高性能、僅使用標頭的 CUDA 庫,可加速 NVIDIA GPU 上的嵌入查找。如果您要構建推薦系統,嵌入操作可能會消耗大量計算資源。
嵌入查找是一項獨特的優化挑戰。它們是內存密集型操作,具有不規則的訪問模式。cuEmbed 專為應對這些挑戰而設計,其吞吐量是 power-law 分布式輸入索引的 HBM 內存帶寬峰值的兩倍以上。
在本文中,我將解釋嵌入查找是什么,它們為什么對推薦系統至關重要,以及 cuEmbed 優化技術如何提供卓越性能。無論您是直接使用 C++ 還是使用 PyTorch,我都會提供將 cuEmbed 集成到項目中的實踐指導。
NVIDIA 認識到嵌入用例因應用而異,因此將 cuEmbed 完全開源。這使您能夠自定義和擴展核心性能內核。
什么是嵌入查找?
某些輸入自然會使用神經網絡進行處理,例如浮點數向量或像素值,這些輸入可以直接傳遞給卷積層或全連接層。
但是,大多數數據都是非數值數據,這意味著它表示為一系列類別中的一個選項。例如,考慮推薦的產品 (例如特定電影) ,以及類型或創作年份。
嵌入是一種將非數值特征轉換為用于預測的浮點數向量的方法。 嵌入表 是一組與非數值特征對應的所有已學習向量。cuEmbed 中正在優化的核心運算是 嵌入查找 運算 (Figure 1) 。此操作具有以下特征:
- 獲取一個或多個查找索引,這些索引表示作為輸入引用的一個或多個類別。
- 從嵌入表檢索相應行。
- (可選) 通過求和、均值或 concatenation 等方式組合這些向量。
- 為下游神經網絡處理生成密集輸出向量。
在 PyTorch 中,可以使用 nn.Embedding 進行單索引查找,使用 nn.EmbeddingBag 進行多索引查找。
生產系統中的嵌入操作規模巨大。典型的嵌入操作可能涉及從 O(1) 查找到 O(100) 索引,因此處理完整的批量可能涉及加載數萬甚至數百萬個嵌入行。有關更多信息,請參閱 來自 Ele.me 的推薦數據 和 來自 Alibaba 的用戶行為數據集 。

學習嵌入向量需要向后傳遞,即從下游神經網絡到達的梯度會傳播回嵌入表。這在計算上類似于正向傳遞。在前向傳遞中,您可以收集并有選擇地累積單個批量樣本中索引引用的所有行。但是,在向后傳遞中,您可以從前向查找中包含該行索引的所有批量樣本中收集并累積指定為單個嵌入行的梯度。
優化推薦嵌入和 cuEmbed
嵌入查找操作占用大量內存,在浮點運算中相對較少。它們非常適合 GPU,因為 GPU 的可用顯存帶寬為 TB/s(每秒數萬億字節)。
眾所周知,要在 GPU 上實現高顯存帶寬,應跨線程合并訪問。然而,圖 2 顯示,即使是相對較窄的訪問,例如在嵌入表中均勻分布的浮點格式嵌入寬度 32 (每行 128 字節) ,也可以達到接近峰值的 HBM 吞吐量。如果在線程束中對齊和合并訪問,則不同的線程束可以訪問不相交的內存位置,并且仍然實現高內存性能,就像嵌入查找中的情況一樣。
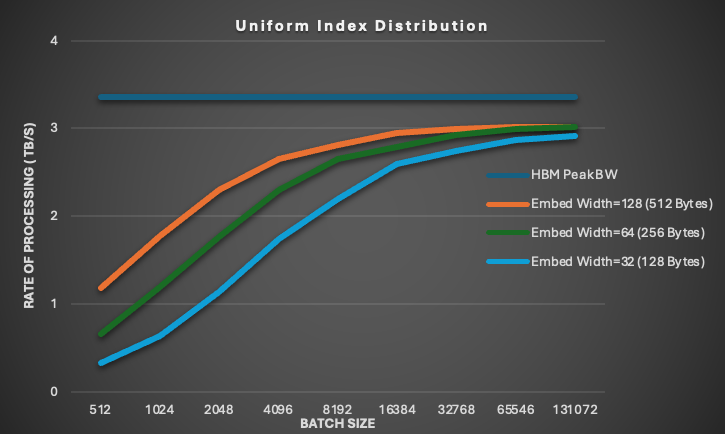
圖 2 涵蓋 10M 個類別;統一索引分布、fixed-hotness 格式,其中 hotness=64,float32 嵌入類型,sum 組合模式,和 1K 迭代。
由于緩存的帶寬放大效應,GPU 在嵌入查找方面更加出色。為嵌入查找提供的索引往往遵循冪律分布,這意味著某些項目或行比其他項目或行更受歡迎。常用行保留在 GPU 上的 L1 和 L2 緩存中。這可以緩解內存系統的下游壓力,并加快片上處理速度。
cuEmbed 用于提高嵌入查找性能的策略是最大限度地增加呈現給內存系統的 loads-in-flight 數量。這是由 Little’s law 推動的,該定律將并行處理的項目數量和訪問的延遲與所達到的總帶寬相關聯。
我們提供更少的線程,每個線程都有更多寄存器,以增加專用于全局加載 (LDG) 指令的資源總量。我們還使用循環展開,通過從單個線程同時加載多個嵌入行來提高內存級并行性。我們使用向量類型 (例如 float4) 進行加載和存儲,并將索引預加載到共享顯存中,從而將加載粒度增加到每線程 128 位 (LDG.128) ,以降低索引訪問的延遲。
圖 3 顯示了以 TB/s 為單位處理嵌入行的速率可能超過 8 TB/s,比 HBM 峰值帶寬速率高 2 倍以上。

圖 3 涵蓋 1000 萬個類別,Power-Law (PSX) 指數分布:α=1.05,fixed-hotness 格式,其中 hotness=64;float32 嵌入類型、sum 組合模式和 1K 迭代。
總之,在 H100 GPU 上運行的 cuEmbed 能夠在各種配置和合理的批量大小下以 TB/s 的速率處理嵌入行。
如何使用 cuEmbed?
cuEmbed 是一個 C++ header-only 庫,您無需單獨構建或安裝。相反,請將 cuEmbed 作為子模塊添加到您的項目中,并包含相關的 .cuh 文件以訪問 API。
例如,要訪問 embedding lookup 函數,請包含以下內容:
cuembed/include/embedding_lookup.cuh |
向后傳遞需要對查找索引進行額外轉換,例如 transposition:
cuembed/include/index_transformations.cuh |
您還可以通過 CMake Package Manager (CPM) 將 cuEmbed 直接添加到您的項目中。將以下代碼添加到您的 CMakeLists.txt 文件中,并將 my_library 替換為目標的名稱:
CPMAddPackage( NAME cuembed GIT_REPOSITORY https://github.com/NVIDIA/cuembed.git GIT_TAG main OPTIONS "BUILD_TESTS OFF" "BUILD_BENCHMARKS OFF")target_link_libraries(my_library cuembed::hdrs) |
/examples/pytorch 目錄包含將 cuEmbed 集成到 PyTorch 的示例。cuEmbed 前向、后向和各種輔助函數作為 C++ 擴展程序向 PyTorch 公開,這些擴展程序進一步封裝在自定義 PyTorch 操作中。目前,cuEmbed 和本示例僅支持 torch.nn.EmbeddingBag 功能的子集。
有關更多信息 (包括詳細文檔和示例) ,請參閱 /NVIDIA/cuembed GitHub 資源庫 。cuEmbed 完全開源。內核使用 C++ 模板設計,易于閱讀,因此您可以根據需要擴展和增強這些內核,同時保留高性能所需的優化。
Pinterest 的成功案例:Faster recommender 訓練
我們與 Pinterest 的工程師分享了 cuEmbed,以測試其在實際推薦系統工作負載上的性能。我們得到的反響鼓舞人心。
Pinterest ML Foundations 團隊的 Chen Yang 表示:“稀疏或分類特征的嵌入查找通常是我們基于 GPU 的推薦系統模型中的瓶頸。在集成 cuEmbed 并將代碼更改降至最低后,我們在關鍵產品排名和推薦 ML 工作負載中實現了 15-30% 的 GPU-roofline 訓練吞吐量提升。”
總結?
cuEmbed 為 NVIDIA GPU 上的嵌入查找提供高性能解決方案,通過優化的內存訪問模式和有效的緩存利用率,實現超過原始 HBM 帶寬的吞吐率。通過開源此庫,我們的目標是使社區能夠針對不同的嵌入用例定制和擴展這些優化。
無論您是構建推薦系統、圖形神經網絡,還是使用語言模型,cuEmbed 都能以最少的代碼更改顯著加速嵌入操作。
后續步驟?
cuEmbed 為 NVIDIA GPU 上的嵌入查找提供高性能解決方案,通過優化的內存訪問模式和有效的緩存利用率,實現超過原始 HBM 帶寬的吞吐率。通過開源此庫,NVIDIA 旨在使社區能夠針對不同的嵌入用例定制和擴展這些優化。
無論您是構建推薦系統、圖形神經網絡,還是使用語言模型,cuEmbed 都能以最少的代碼更改顯著加速嵌入操作。
- 從 /NVIDIA/cuembed GitHub 資源庫下載 cuEmbed。有關 Python 集成模式,請探索
/examples目錄。有關高級使用場景,請參閱 cuEmbed 文檔 。
?