執行詳盡的精確 k 最近鄰 (kNN) 搜索,也稱為暴力搜索,成本高昂,并且它不能很好地擴展到更大的數據集。在向量搜索期間,暴力搜索需要計算每個查詢向量和數據庫向量之間的距離。對于常用的歐幾里德和余弦距離,計算任務等同于大型矩陣乘法。
雖然 GPU 在執行矩陣乘法方面效率很高,但隨著數據量的增加,計算成本變得令人望而卻步。然而,許多應用程序不需要精確的結果,而是可以為了更快的搜索而犧牲一些準確性。當不需要精確的結果時,近似最近鄰 (ANN) 方法通常可以減少搜索期間必須執行的距離計算的數量。
本文主要介紹了 IVF-Flat,這是 NVIDIA RAPIDS RAFT 中的一種方法。IVF-Flat 方法使用原始(即Flat)向量的倒排索引 (IVF)。此算法提供了簡單的調整手段,以減少整體搜索空間并在準確性和速度之間進行權衡。
為了幫助您了解如何使用 IVF-Flat,我們討論了該算法的工作原理,并演示了Python和C++ APIs我們介紹了索引構建的設置參數,并提供了如何配置 GPU 加速的 IVF-Flat搜索的技巧。這些步驟也可以在示例中遵循Python notebook和C++ project.最后,我們演示了 GPU 加速的向量搜索比 CPU 搜索快一個數量級。
IVF-Flat 算法
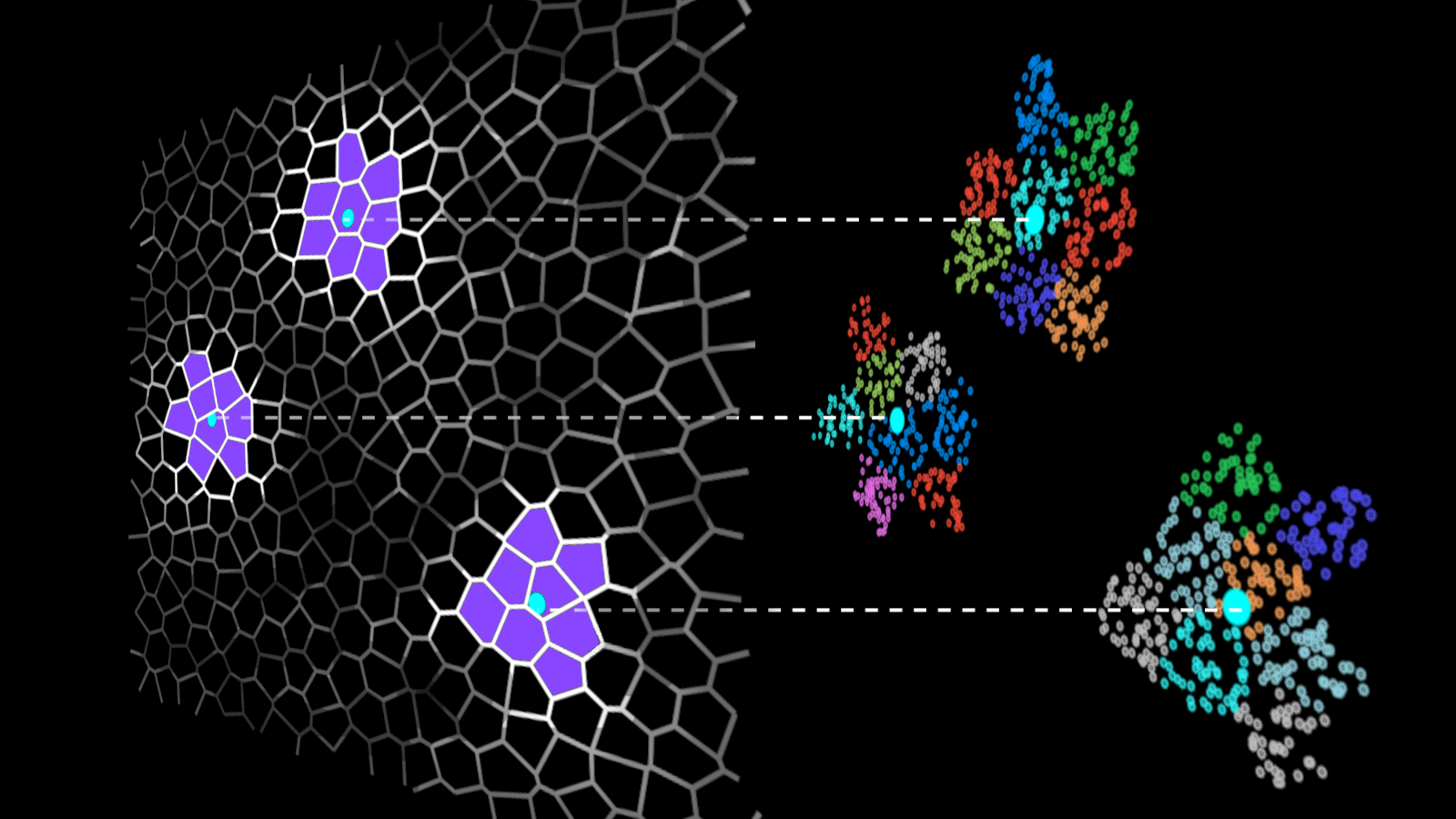
IVF 方法通過將數據集向量分組為簇并將搜索限制在每個查詢的一些最近簇來加速向量搜索(圖 1)。
在 IVF-Flat 算法中,只搜索幾個簇(而不是整個數據集)是實際的近似值。使用此近似值,您可能會錯過分配給您未搜索的簇的一些近鄰,但它極大地縮短了搜索時間。
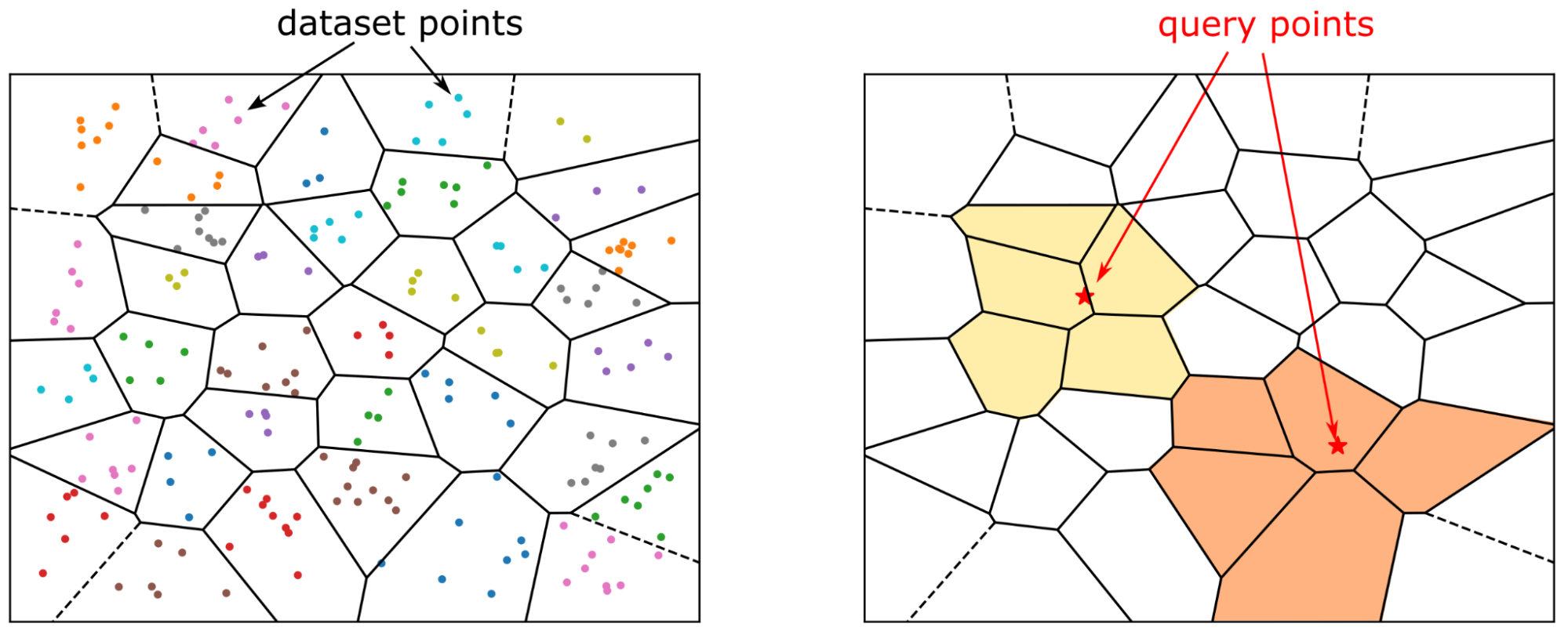
在搜索數據集之前,您必須構建索引,這是一種存儲高效搜索所需信息的結構。對于 IVF-Flat,索引存儲簇的描述:其中心坐標和屬于簇的向量列表。此列表是倒排列表,也稱為倒排文件,這就是 IVF 的首字母縮寫詞。
在討論倒排文件后,我們將在以下部分演示如何構建索引并解釋如何執行搜索。
IVF 含義
為完整起見,以下是一些歷史語境。倒排文件(或倒排索引)來自信息檢索字段。
以幾個簡單的文本文檔為例。如果要搜索包含給定單詞的文檔, forward index會存儲每個文檔的單詞列表。您必須明確閱讀每個文檔才能找到相關的文檔。
相比之下,倒排索引包含了您可以搜索的所有單詞的字典,并且對于每個單詞,都有一個該單詞所在的文檔索引列表。這就是所謂的倒排列表(倒排文件),您可以將搜索限制在選定的列表中。
如今,文本數據通常表示為向量嵌入。IVF-Flat 方法定義了簇中心,這些中心類似于前面示例中的詞典。對于每個簇中心,您都有屬于該簇的向量索引列表,并且搜索速度加快,因為您只需檢查選定的簇。
索引構建
索引構建主要是對數據集進行聚類運算。ivf_flat可以使用以下代碼示例在 Python 中創建索引:
from pylibraft.neighbors import ivf_flat?
build_params = ivf_flat.IndexParams(????????n_lists=1024,????????metric="sqeuclidean"????)?
index = ivf_flat.build(build_params, dataset) |
在 C++中,您有以下語法:
#include <raft/neighbors/ivf_flat.cuh> using namespace raft::neighbors;raft::device_resources dev_resources;?
ivf_flat::index_params index_params;index_params.n_lists = 1024;index_params.metric = raft::distance::DistanceType::L2Expanded;?
auto index = ivf_flat::build(dev_resources, index_params,raft::make_const_mdspan(dataset.view())); |
創建索引的最重要超參數是n_lists其中會指明要使用的簇數量。您還可以指定距離計算指標。
搜索
構建索引后,搜索很簡單。在 Python 中,以下調用返回兩個數組:相鄰數組的索引及其與查詢向量的距離:
distances, indices = ivf_flat.search(ivf_flat.SearchParams(n_probes=50), index, queries, k=10) |
C++中的等效調用需要預先分配輸出數組:
int topk = 10;auto neighbors = raft::make_device_matrix<int64_t, int64_t>(dev_resources, n_queries, topk);auto distances = raft::make_device_matrix<float, int64_t>(dev_resources, n_queries, topk);?
ivf_flat::search_params search_params;search_params.n_probes = 50;?
ivf_flat::search(dev_resources,????????????????search_params,????????????????index,????????????????raft::make_const_mdspan(queries.view()),????????????????neighbors.view(),????????????????distances.view()); |
在這里,您可以搜索k=10每個查詢的近鄰。參數 n_probes 會告知您每個查詢要搜索(或探測)的簇數量,并確定搜索的準確性。
僅通過測試 n_probes 對于每個查詢的簇,您可以省略分配給簇的一些近鄰,簇的中心距離查詢點更遠。搜索質量通常以召回率,這是實際最近 k 近鄰在所有返回近鄰中的百分比。
在內部,搜索分兩個步驟執行(圖 2):
- 粗略搜索選擇 n_probes 每個查詢的附近簇。
- 精細搜索將查詢向量與選定簇中的所有數據集向量進行比較。
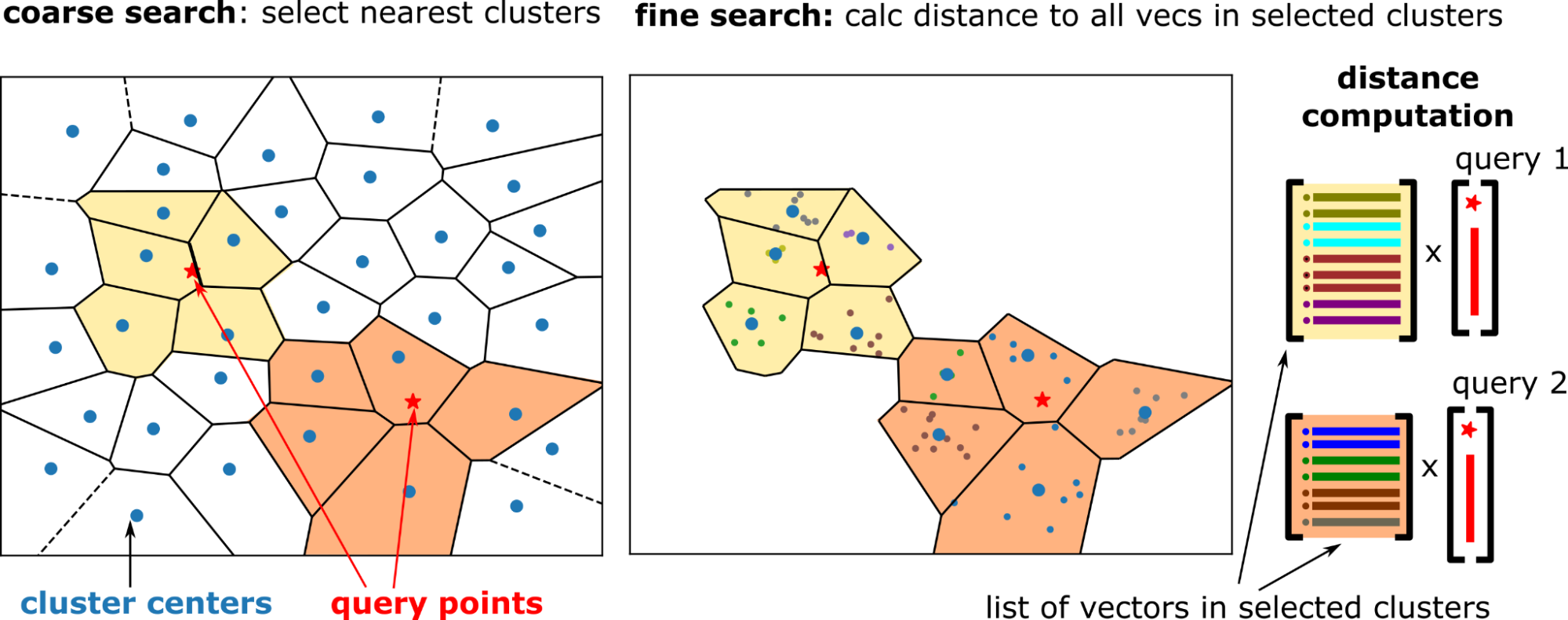
粗略搜索
粗略搜索使用簇中心和查詢向量之間的精確 kNN 搜索完成。選擇最近的簇中心,n_探針簇粗略搜索相對便宜,因為簇數量遠小于數據集大小(例如,1 億個向量的簇數量為 1 萬個)。
精細搜索
對于 IVF-Flat,精細搜索也是精確搜索。但每個查詢都有自己的一組要搜索(要探測)的簇,并且計算查詢向量與被探測簇中所有向量之間的距離。
對于小批量,您在查詢點周圍搜索的區域不會重疊。因此,問題結構變為批量矩陣向量乘法 (GEMV) 運算。此運算受內存帶寬限制,GPU 顯存的大帶寬大大加速了此步驟。
選中每個探測簇的 top-k 近鄰,結果是n_probes=k 個候選近鄰這簡化為 k 個最近的近鄰。
調整索引構建參數
在前面的部分中,您概述了索引構建和搜索。下面詳細介紹了如何設置索引構建的參數。
索引構建包含兩個階段:
- 訓練或計算簇(構建):平衡的分層 k-means 算法會對訓練數據進行聚類。
- 將數據集向量添加到索引(擴展):將數據集向量分配給其簇,并將其添加到相應簇的向量列表中。
簇數量
我們n_listsparameter 對訓練和搜索期間的整體性能有著深遠的影響:它定義了索引數據所劃分的簇數量。設置n_lists=sqrt (n_samples)是一個很好的起點(n_samples,是數據集中的向量數)。
為確保高效利用 GPU 資源,簇的平均大小(即n_samples/n_lists)應在至少 1K 個向量的范圍內,以保持單個流多處理器 (SM) 的繁忙狀態。
使用自動數據子采樣構建索引
K-means 聚類是計算密集型的。為加速索引構建,請對數據集進行子采樣。使用參數kmeans_trainset_fraction=0.1 這意味著您將十分之一的數據集用于訓練簇中心。
build_params = ivf_flat.IndexParams(????????n_lists=1024,????????metric="sqeuclidean",????????kmeans_trainset_fraction=0.1,????????kmeans_n_iters=20????) |
在訓練期間,參數 kmeans_n_iters 將直接傳遞給 k-means 算法。將其設置為適用于大多數數據集的合理默認值 20.但是,此參數只是聚類算法的建議。在幕后,它通常在“平衡”階段執行更多迭代,以確保簇具有相似的大小。
使用用于聚類的特定訓練數據構建索引
在前面的示例中,只需調用ivf_flat.build執行聚類并將整個數據集添加到索引中。或者,您可以調用ivf_flat.build無需將向量添加到索引中即可訓練向量(通過設置add_data_on_build=False).這允許精確控制用于訓練索引的向量。隨后,ivf_flat.extend可用于向索引中添加向量。
如下 Python 代碼示例所示:
n_train = 10000train_set = dataset[cp.random.choice(dataset.shape[0], n_train, replace=False),:]?
build_params = ivf_flat.IndexParams(????????n_lists=1024,????????metric="sqeuclidean",????????kmeans_trainset_fraction=1,????????kmeans_n_iters=20,????????add_data_on_build=False????)?
index = ivf_flat.build(build_params, train_set)ivf_flat.extend(index, dataset, cp.arange(dataset.shape[0], dtype=cp.int64)) |
數據集向量只需調用ivf_flat.extend.在內部,如果需要減少內存消耗,則對數據進行批量處理。相應的 C++代碼如下所示:
index_params.add_data_on_build = false;// Sub sample the dataset to create trainset.// ...// Run k-means clustering using the training setauto index = ivf_flat::build(dev_resources, index_params,????raft::make_const_mdspan(trainset.view()));?
// Fill the index with the dataset vectorsindex = ivf_flat::extend(dev_resources,????raft::make_const_mdspan(dataset.view()),????std::optional<raft::device_vector_view<const int64_t, int64_t>>(),????index); |
向索引中添加新向量
可以通過調用ivf_flat.extend.默認情況下,增加向量列表的成本將通過在增加列表大小時分配額外空間來抵消。C++API 用戶可以通過設置以下參數來更改此行為:
index_params.conservative_memory_allocation = true; |
如果聚類數量較大且預計不會經常添加向量,則此操作會非常有用。
默認情況下,當您向數據集添加向量時,簇中心不會發生變化。adaptive_centers,如果您希望簇中心隨新數據移動,則可以在索引構建期間啟用標志。
調整搜索參數
以下是設置搜索參數的方法:高效使用 GPU 資源并增加 n_probes。
GPU 資源
在搜索過程中,您需要創建內部工作空間內存。我們建議使用池化分配器來減少內存分配用度。
構建 RAFT資源對象非常耗時。資源應通過向搜索函數傳遞資源句柄來重復使用對象。在 Python 中,您可以通過以下方式配置設備資源和內存池:
from pylibraft.common import DeviceResourcesimport rmmmr = rmm.mr.PoolMemoryResource(?????rmm.mr.CudaMemoryResource(),?????initial_pool_size=2**30)rmm.mr.set_current_device_resource(mr)?
handle = DeviceResources()?
search_params = ivf_flat.SearchParams(n_probes=50)distances, indices = ivf_flat.search(search_params, index, queries, k=10, handle=handle)handle.sync() |
C++API 的用戶必須始終傳遞顯式 device_resources 句柄,并且應在單獨調用之間重復使用此句柄進行搜索。可以通過以下方式設置池分配器:
raft::device_resources dev_resources;raft::resource::set_workspace_to_pool_resource(????dev_resources, 2 * 1024 * 1024 * 1024ull);ivf_flat::search(dev_resources, ...) |
C++ 用戶可以為臨時工作空間數組指定一個單獨的分配器,這在前面的示例中已經使用過。全局分配器(用于創建輸入/輸出數組)可以使用 rmm::mr::set_current_device_resource。
探針數量
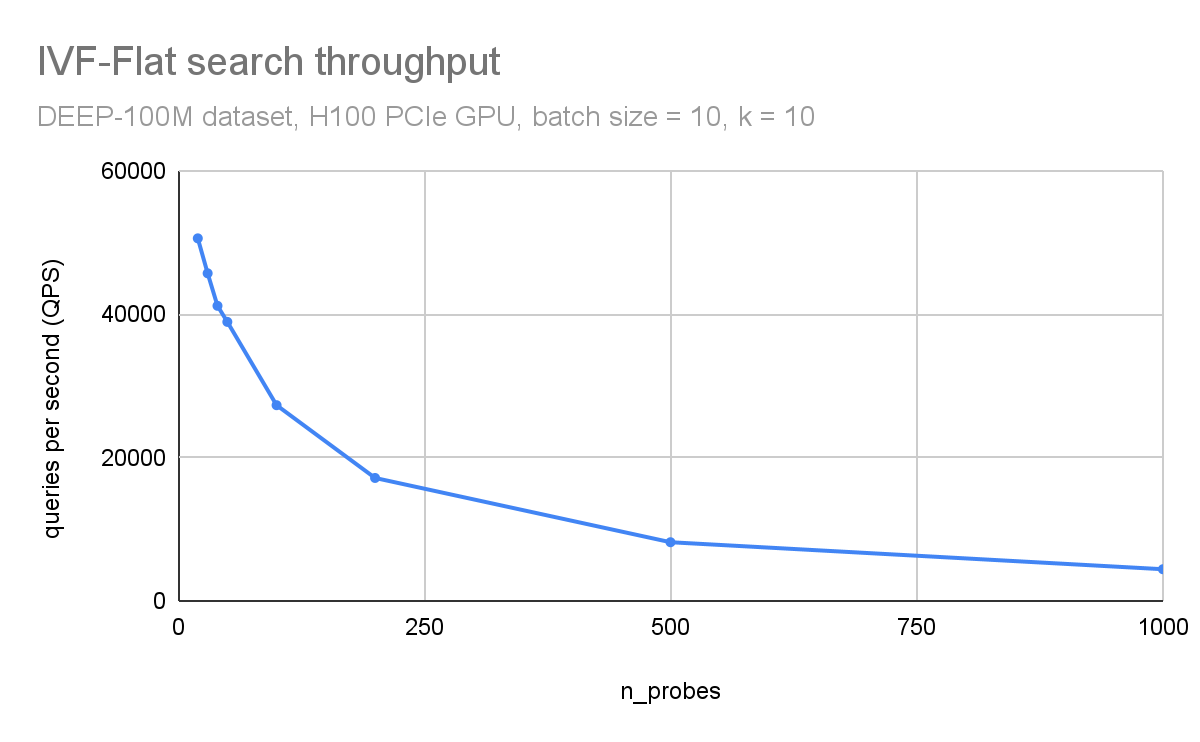
比率n_探針/n_lists表示與每個查詢相比,數據集所占比例。距離計算的數量減少到n_探針/n_簇是暴力搜索計算量的一小部分。搜索質量以及計算時間會隨著您的增加而增加 n_probes 正確的值取決于數據集。
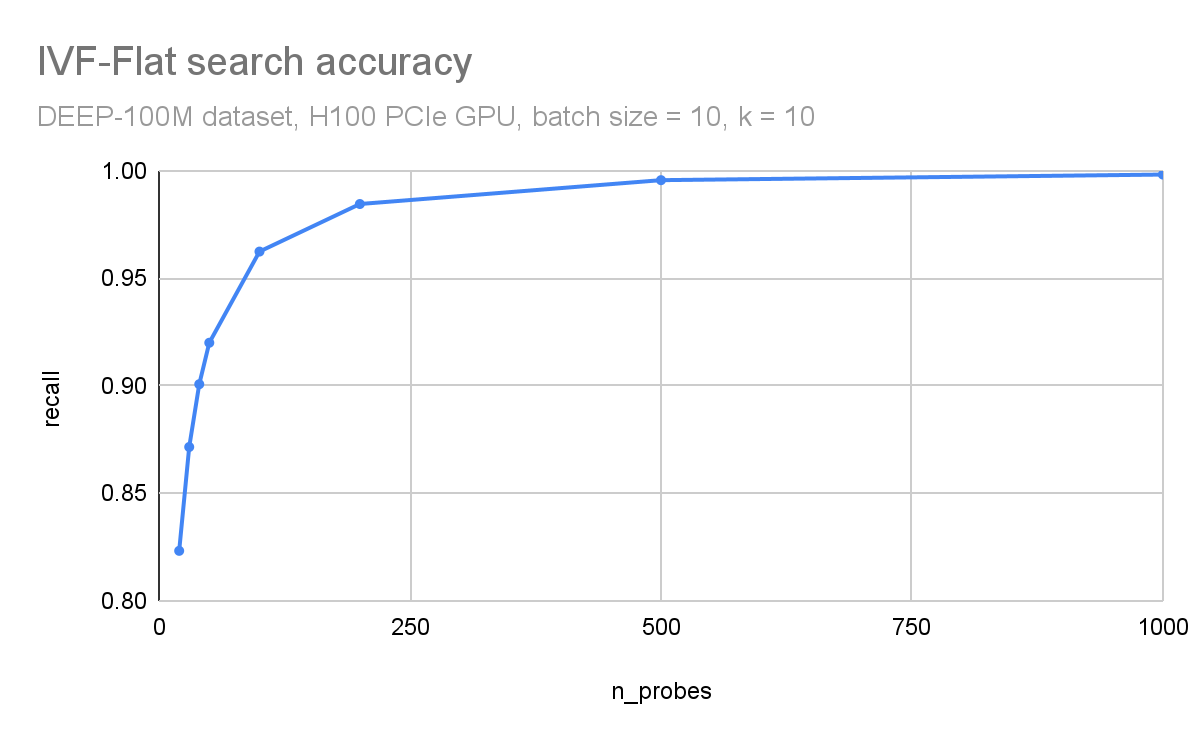
在圖 3 和圖 4 中,您可以觀察到吞吐量(每秒查詢次數)和搜索精度(召回次數)如何依賴于探針的數量。在這里,您正在使用 DEEP1B 數據集 并使用 H100 GPU 進行搜索。
吞吐量與探針的數量成反比。數據集分為 10 萬個簇。僅搜索每個查詢中最近的 100 個簇會導致 96%的召回,搜索 1000 個簇(占數據集的 1%)會導致 99.8%的準確性。
我們通常會將這些圖形組合到單個 QPS 與召回圖中(圖 5)。當您想要緊湊地權衡準確性和搜索吞吐量時,這很有用。在比較不同的 ANN 方法時,這也很有用。
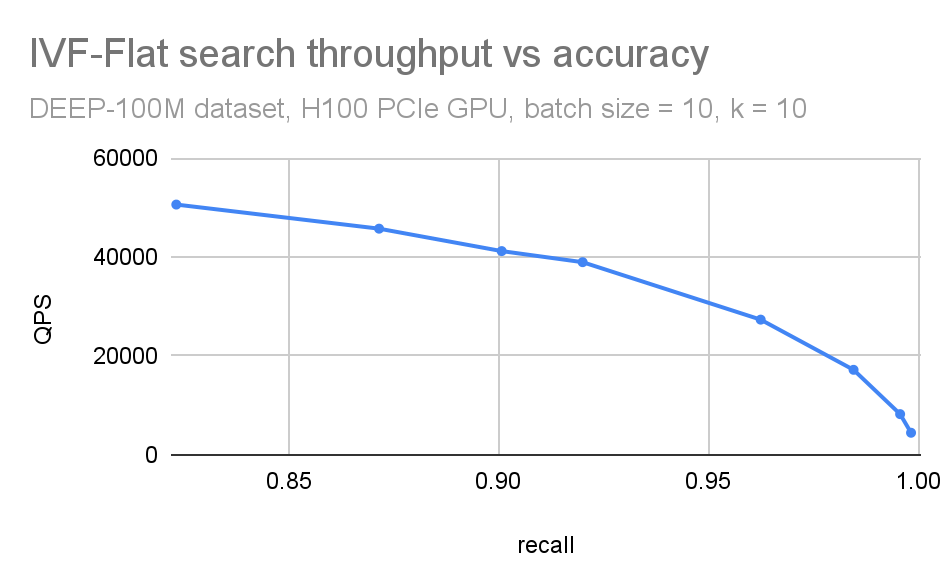
如果n_lists==n_probes 這就像精確(強力)搜索:您將所有數據集向量與所有查詢向量進行比較。在這種情況下,您預計召回次數等于 1 (除了小的舍入誤差)。
作為 n_probes 方法n_lists、IVF-Flat 由于算法所做的額外工作(粗略加精細搜索),速度比強力慢。在實踐中,搜索大約 0.1-1%的列表足以處理許多數據集。但這取決于輸入的聚類效果。
由于 高維空間中距離度量的驚人行為,如果數據集沒有結構(例如,統一隨機數),聚類會變得困難。在這種情況下,IVF 方法的效果不佳。
性能
RAFT 庫可快速實施 IVF-Flat 算法。索引 1 億個向量可在一分鐘內完成(圖 6)。這比使用 CPU 快 14 倍。
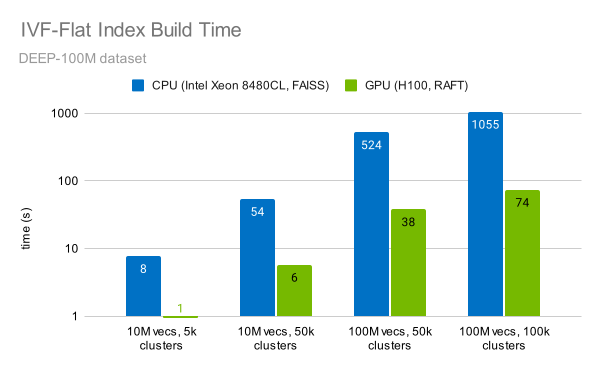
我們在 NVIDIA H100 SXM GPU (使用 RAFT 23.10 進行 GPU 測試)和 Intel Xeon Platinum 8480CL CPU 上執行了FAISS 1.7.4 的測量。
實現這種加速有兩個主要因素:
- GPU 的高計算吞吐量:RAFT 利用 Tensor Core 在索引構建期間加速 k-means 聚類。
- 改進的算法:RAFT 使用平衡的分層 k-means 聚類,即使數據集的向量數量達到數億,也能高效地進行聚類。
您還可以觀察到,構建索引的時間隨向量數量線性增加,隨聚類數量線性增加。
GPU 的高內存吞吐量有助于搜索索引。RAFT 的 IVF-Flat 索引使用優化的內存布局。向量交錯以進行向量化內存訪問,以確保在遍歷每個探測簇中的數據集向量時實現高帶寬利用率。
精細搜索過程中的另一個重要步驟是過濾掉前 k 個候選項。我們有高度優化的方法來選擇前 k 個候選項。我們將優化的 block-select-k 內核融合到距離計算內核中。如圖 7 所示,與 CPU 實現的性能相比,這可以將 RAFT IVF-Flat 的速度提高 20 倍以上(回顧值=0.95)。
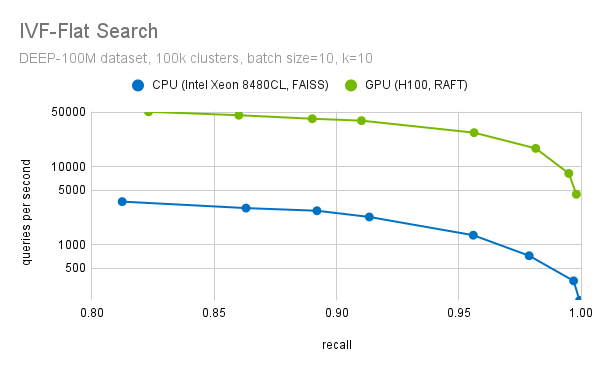
在此基準測試中,我們使用了 FAISS IVF-Flat 的 CPU 實現。FAISS 還提供了此算法的 GPU 實現。如果您使用 FAISS,則只需對代碼進行細微更改即可從 GPU 加速中受益。我們正在與 Meta 合作,將 RAFT 的性能改進引入 FAISS,因此您很快也可以通過 FAISS 使用 RAFT.
總結
在大型數據庫中執行向量搜索時,務必要注意精確搜索的高昂成本,因為這會導致不適合在線服務的低延遲。
RAPIDS RAFT 庫提供了高效的算法,通過將搜索集中到數據集中最相關的部分,以提高向量搜索的延遲和吞吐量。本文討論了 RAFT IVF-Flat 算法的工作原理,以及如何設置索引構建和搜索的參數。最后,我們提供了基準測試,以強調 GPU 在 IVF – Flat 搜索中的卓越性能。您可以使用我們的基準測試工具。
RAFT 是一個用于向量搜索等功能的 開源庫。它提供了易于使用的 C++ 和 Python API,因此您可以將 GPU 加速的向量搜索集成到您的應用中。我們期待聽到您的反饋!請在 GitHub 存儲庫 中向我們發送問題并報告。您也可以在 @rapidsai 上聯系我們。
?





