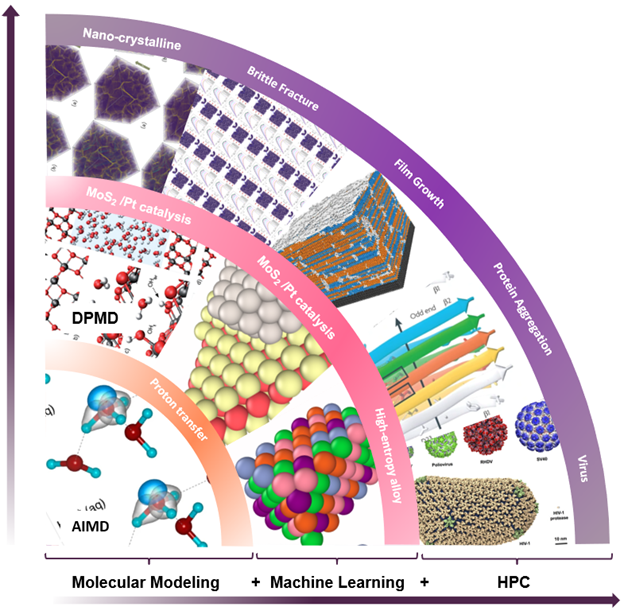
幾十年來,分子模擬界在模擬勢能面和原子間作用力時面臨著精度與效率的兩難選擇。深勢,人工神經網絡力場,通過結合經典分子動力學( MD )模擬的速度和密度泛函理論( DFT )計算的準確性來解決這個問題。 1 這是通過使用 GPU – 優化包 DeePMD-kit 實現的,這是一個用于多體勢能表示和 MD 模擬的深度學習包。 2
這篇文章提供了一個端到端的演示,演示如何為二維材料石墨烯訓練神經網絡潛力,并使用它在開源平臺大型原子/分子大規模并行模擬器( LAMMPS )中驅動 MD 模擬。 3 培訓數據可從維也納從頭算模擬軟件包( VASP )獲得 4 ,或量子濃縮咖啡( QE )。 5
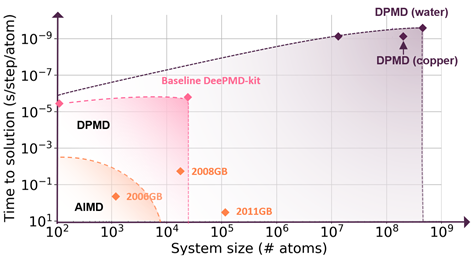
分子建模、機器學習和高性能計算( HPC )的無縫集成通過分子動力學和從頭算準確性—這完全是通過基于容器的工作流來實現的。利用人工智能技術擬合 DFT 產生的原子間作用力,可以通過線性標度將可訪問的時間和尺寸標度提高幾個數量級。
深度潛能本質上是機器學習和物理原理的結合,它開啟了一種新的計算范式,如圖 1 所示。
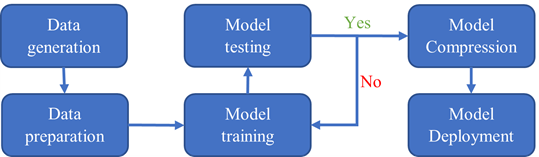
整個工作流如圖 2 所示。數據生成步驟由 VASP 和 QE 完成。數據準備、模型訓練、測試和壓縮步驟使用 DeePMD 工具包完成。模型部署在 LAMMPS 中。
為什么是集裝箱?
容器是一個可移植的軟件單元,它將應用程序及其所有依賴項組合到一個與底層主機操作系統無關的包中。
本文中的工作流程涉及 AIMD 、 DP 培訓和 LAMMPS MD 模擬。使用正確的編譯器設置、 MPI 、 GPU 庫和優化標志從源代碼安裝每個軟件包是非常重要和耗時的。
容器通過為每個步驟提供一個高度優化的 GPU 支持的計算環境來解決這個問題,并且消除了安裝和測試軟件的時間。
NGC 目錄是 GPU 優化的 HPC 和 AI 軟件的集線器,它攜帶了整個 HPC 和 AI 容器?,可以很容易地部署在任何 GPU 系統上。 NGC 目錄中的 HPC 和 AI 容器經常更新,并進行可靠性和性能測試,這對于加快解決時間是必要的。
還將掃描這些容器的常見漏洞和暴露( CVE ),確保它們沒有任何開放端口和惡意軟件。此外, HPC 容器支持 Docker 和 Singularity 運行時,并且可以部署在云中或本地運行的多[ZFBB]和多節點系統上。
訓練數據生成
模擬的第一步是數據生成。我們將向您展示如何使用 VASP 和 Quantum ESPRESSO 來運行 AIMD 模擬并為 DeePMD 生成訓練數據集。可以使用以下命令從 GitHub 存儲庫下載所有輸入文件:
git clone https://github.com/deepmodeling/SC21_DP_Tutorial.gitVASP
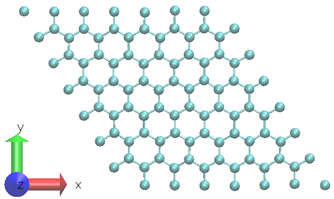
如圖 3 所示,使用具有 98 個原子的二維石墨烯系統。 6 為了生成訓練數據集,在 300K 下進行 0 . 5ps NVT AIMD 模擬。選擇的時間步長為 0 . 5fs 。 DP 模型是使用固定溫度下 0 . 5ps MD 軌跡的 1000 個時間步長創建的。
由于仿真時間較短,訓練數據集包含連續的系統快照,這些快照高度相關。通常,訓練數據集應從與各種系統條件和配置不相關的快照中采樣。對于這個例子,我們使用了一個簡化的訓練數據方案。對于生產 DP 培訓,建議使用 DP-GEN 利用并行學習方案,以有效探索更多的條件組合。 7
用投影增強波贗勢描述了價電子與凍結核之間的相互作用。廣義梯度近似交換? Perdew 的相關泛函?伯克?恩澤霍夫。在所有系統中,只有 Γ-point 用于 k-space 采樣。
量子濃縮咖啡
AIMD 模擬也可以使用 Quantum ESPRESSO ( NGC 目錄中的 container 提供)進行。 Quantum ESPRESSO 是一套基于密度泛函理論、平面波和贗勢的開放源代碼,用于 Nan oscale 的電子結構計算和材料建模。 QE 計算中使用了相同的石墨烯結構。以下命令可用于啟動 AIMD 模擬:
$ singularity exec --nv docker://nvcr.io/hpc/quantum_espresso:qe-6.8 cp.x < c.md98.cp.in培訓數據準備
一旦從 AIMD 仿真中獲得訓練數據,我們希望使用 dpdata 因此,它可以作為深層神經網絡的輸入。 dpdata 包是 AIMD 、 Classic MD 和 DeePMD 工具包之間的格式轉換工具包。
您可以使用方便的工具 dpdata 將數據直接從 first principles 軟件包的輸出轉換為 DeePMD 工具包格式。對于深勢訓練,必須提供物理系統的以下信息:原子類型、盒邊界、坐標、力、病毒和系統能量。
快照或系統框架在一個時間步中包含所有原子的所有這些數據點,可以以兩種格式存儲,即 raw 和 npy 。
第一種格式 raw 是純文本,所有信息都在一個文件中,文件的每一行表示一個快照。不同的系統信息存儲在名為 box.raw, coord.raw, force.raw, energy.raw 和 virial.raw 的不同文件中。我們建議您在準備培訓文件時遵循這些命名約定。
force.raw 的一個示例:
$ cat force.raw
-0.724 2.039 -0.951 0.841 -0.464 0.363 6.737 1.554 -5.587 -2.803 0.062 2.222
-1.968 -0.163 1.020 -0.225 -0.789 0.343這個 force.raw 包含三個框架,每個框架具有兩個原子的力,形成三條線和六列。每條線在一幀中提供兩個原子的所有三個力分量。前三個數字是第一個原子的三個力分量,而下三個數字是第二個原子的力分量。
坐標文件 coord.raw 的組織方式類似。在 box.raw 中,應在每行上提供盒向量的九個分量。在 virial.raw 中,維里張量的九個分量應按 XX XY XZ YX YY YZ ZX ZY ZZ 的順序提供在每一行上。所有原始文件的行數應相同。我們假設原子類型不會在所有幀中改變。它由 type.raw 提供,它有一行原子類型,一行一行地寫。
原子類型應該是整數。例如,一個系統的 type.raw 有兩個原子,分別為零和一:
$ cat type.raw
0 1將數據格式轉換為 raw 不是一項要求,但此過程應能說明可作為培訓用 DeePMD 工具包輸入的數據類型。
將第一原理結果轉換為訓練數據的最簡單方法是將其保存為 NumPy 二進制數據。
對于 VASP 輸出,我們準備了一個 outcartodata.py 腳本來處理 VASP OUTCAR 文件。通過運行以下命令:
$ cd SC21_DP_Tutorial/AIMD/VASP/
$ singularity exec --nv docker://nvcr.io/hpc/deepmd-kit:v2.0.3 python outcartodata.py
$ mv deepmd_data ../../DP/量化寬松產出:
$ cd SC21_DP_Tutorial/AIMD/QE/
$ singularity exec --nv docker://nvcr.io/hpc/deepmd-kit:v2.0.3 python logtodata.py
$ mv deepmd_data ../../DP/生成名為 deepmd_data 的文件夾并將其移動到培訓目錄。它生成五組 0/set.000, 1/set.000, 2/set.000, 3/set.000, 4/set.000 ,每組包含 200 幀。不需要處理每個 set .*目錄中的二進制數據文件。包含 set.* 文件夾和 type.raw 文件的路徑稱為系統。如果要訓練非周期系統,應在系統目錄下放置一個空 nopbc 文件。 box.raw 不是必需的,因為它是非周期系統。
我們將使用五套中的三套進行培訓,一套用于驗證,另一套用于測試。
深勢模型訓練
深勢模型的輸入是包含前面提到的系統信息的描述符向量。神經網絡包含幾個隱藏層,由線性和非線性變換組成。在這篇文章中,使用了一個三層神經網絡,每層有 25 個、 50 個和 100 個神經元。神經網絡學習的目標值或標簽是原子能。訓練過程通過最小化損失函數來優化權重和偏差向量。
訓練由命令啟動,其中 input.json 包含訓練參數:
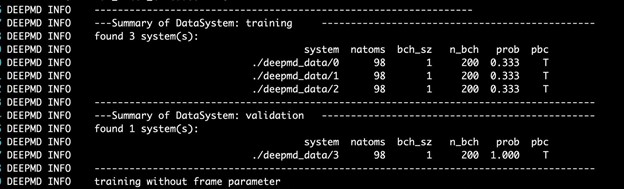
$ singularity exec --nv docker://nvcr.io/hpc/deepmd-kit:v2.0.3 dp train input.jsonDeePMD 工具包打印培訓和驗證數據集的詳細信息。數據集由輸入腳本的 training 部分中定義的 training_data 和 validation_data 確定。訓練數據集由三個數據系統組成,而驗證數據集由一個數據系統組成。原子數、批次大小、系統中的批次數以及使用系統的概率均如圖 4 所示。最后一列顯示系統是否假設周期邊界條件。
在培訓期間,每 disp_freq 培訓步驟都會使用用于培訓模型的批次和驗證數據中的 numb_btch 批次測試模型的錯誤。在文件 disp_file 中相應地打印訓練錯誤和驗證錯誤(默認為 lcurve.out )。可在輸入腳本中通過訓練和驗證數據集相應部分中的鍵 batch_size 設置批量大小。
輸出的一個示例:
# step rmse_val rmse_trn rmse_e_val rmse_e_trn rmse_f_val rmse_f_trn lr 0 3.33e+01 3.41e+01 1.03e+01 1.03e+01 8.39e-01 8.72e-01 1.0e-03 100 2.57e+01 2.56e+01 1.87e+00 1.88e+00 8.03e-01 8.02e-01 1.0e-03 200 2.45e+01 2.56e+01 2.26e-01 2.21e-01 7.73e-01 8.10e-01 1.0e-03 300 1.62e+01 1.66e+01 5.01e-02 4.46e-02 5.11e-01 5.26e-01 1.0e-03 400 1.36e+01 1.32e+01 1.07e-02 2.07e-03 4.29e-01 4.19e-01 1.0e-03 500 1.07e+01 1.05e+01 2.45e-03 4.11e-03 3.38e-01 3.31e-01 1.0e-03
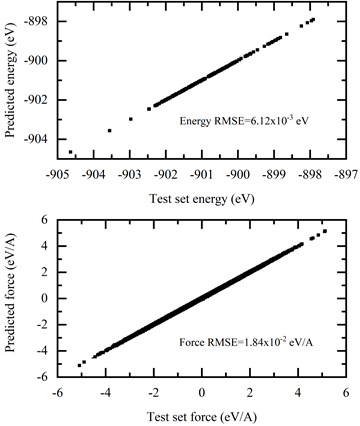
如圖 5 所示,訓練誤差隨著訓練步驟單調減少。訓練后的模型在測試數據集上進行了測試,并與 AIMD 仿真結果進行了比較。測試命令是:
$ singularity exec --nv docker://nvcr.io/hpc/deepmd-kit:v2.0.3 dp test -m frozen_model.pb -s deepmd_data/4/ -n 200 -d detail.out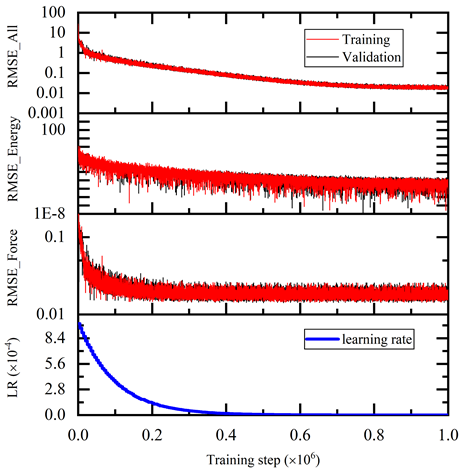
結果如圖 6 所示。
模型導出和壓縮
模型訓練完成后,生成一個凍結模型,用于 MD 仿真中的推理。從檢查點保存神經網絡的過程稱為“凍結”模型:
$ singularity exec --nv docker://nvcr.io/hpc/deepmd-kit:v2.0.3 dp freeze -o graphene.pb生成凍結模型后,可以在不犧牲精度的情況下對模型進行壓縮;在 MD 中大大加快推理性能的同時,根據仿真和訓練設置,模型壓縮可以將性能提高 10 倍,在 GPU 上運行時將內存消耗減少 20 倍。
可以使用以下命令壓縮凍結模型, -i 表示凍結模型, -o 表示壓縮模型的輸出名稱:
$ singularity exec --nv docker://nvcr.io/hpc/deepmd-kit:v2.0.3 dp compress -i graphene.pb -o graphene-compress.pbLAMMPS 中的模型部署
在 LAMMPS 中實現了一種新的配對方式,以便在前面的步驟中部署經過訓練的神經網絡。對于熟悉 LAMMPS 工作流程的用戶,只需進行最小的更改即可切換到深度潛力。例如,具有 Tersoff 電位的傳統 LAMMPS 輸入具有以下電位設置:
pair_style tersoff
pair_coeff * * BNC.tersoff C若要使用深電位,請將以前的線路替換為:
pair_style deepmd graphene-compress.pb
pair_coeff * *輸入文件中的 pair_style 命令使用 DeePMD 模型來描述石墨烯系統中的原子相互作用。
graphene-compress.pb文件表示用于推斷的凍結和壓縮模型。- MD 模擬中的石墨烯系統包含 1560 個原子。
- 周期性邊界條件應用于橫向
x和y方向,自由邊界應用于z方向。 - 時間步長設置為 1 fs 。
- 將系統置于溫度為 300 K 的 NVT 系綜下進行松弛,這與 AIMD 設置一致。
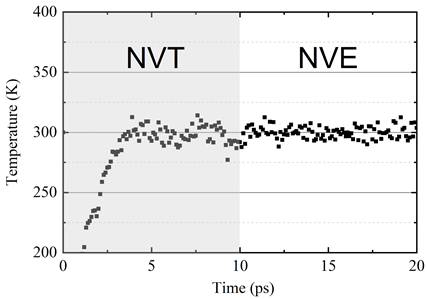
NVT 松弛后的系統配置如圖 7 所示。可以觀察到,深勢可以描述原子結構,在橫平面方向上有小的波紋。在 10ps NVT 松弛后,將系統置于 NVE 系綜下以檢查系統穩定性。

系統溫度如圖 8 所示。
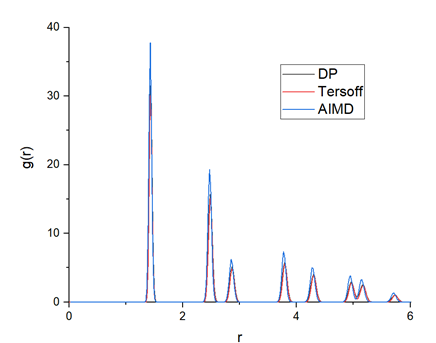
為了驗證經過訓練的 DP 模型的準確性,從 AIMD 、 DP 和 Tersoff 計算出的徑向分布函數( RDF )如圖 9 所示。 DP 模型生成的 RDF 與 AIMD 模型非常接近,這表明 DP 模型可以很好地描述石墨烯的晶體結構。
結論
這篇文章展示了在給定條件下石墨烯的一個簡單案例研究。 DeePMD-kit 軟件包簡化了從 AIMD 到經典 MD 的工作流程,具有很大的潛力,提供了以下關鍵優勢:
- 在 TensorFlow 框架中實現高度自動化和高效的工作流。
- 使用流行的 DFT 和 MD 包(如 VASP 、 QE 和 LAMMPS )的 API 。
- 廣泛應用于有機分子、金屬、半導體、絕緣體等。
- 具有 MPI 和[ZFBB]支持的高效 HPC 代碼。
- 模塊化,便于其他深度學習潛在模型采用。
此外,使用 NGC 目錄中的 GPU – 優化容器簡化并加速了整個工作流程,省去了安裝和配置軟件的步驟。要為其他應用程序培訓綜合模型,請從 NGC 目錄下載 DeepMD Kit Container 。
致謝
我們感謝與坦普爾大學的張春義博士、韓丹博士、山東大學的王新宇博士以及 DeepModeling 社區的張林峰博士、張玉芝博士、曾金哲博士、張鐸博士和袁鳳波博士進行的有益討論。
工具書類
[1] 賈偉,王浩,陳明,陸德,林力,車 R , E W 和張力 2020 年推動了分子動力學的極限從頭算機器學習精確到 1 億個原子 IEEE 出版社 5 1-14
[2] Wang H , Zhang L , Han J 和 E W 2018 DeePMD 工具包:多體勢能表征和分子動力學計算機物理通信的深度學習包 228 178-84
[3] Plimpton S 1995 短程分子動力學快速并行算法計算物理雜志 117 1-19
[4] Kresse G 和 Hafner J 1993 液態金屬的從頭算分子動力學物理評論 B 47 558-61
[5] 吉安諾齊 P 、巴羅尼 S 、博尼尼 N 、卡蘭德拉 M 、卡爾 R 、卡瓦佐尼 C 、塞雷索爾 D 、基亞羅蒂 G L 、科科科西科尼 M 、達博 I 、達爾科索 A 、德吉隆科利 S 、法布里斯 S 、弗拉迪斯 G 、格鮑爾 R 、格斯特曼 U 、古古古西 C 、科卡利 A 、拉澤里 M 、馬丁薩莫斯 L 、馬扎里 N 、毛里 F 、馬扎雷羅 R 、保利尼 S 、帕斯夸雷羅 A 、保拉托 L 、斯巴克亞 C 、斯堪多洛 S 、, Sclauzero G 、 Seitsonen A P 、 Smogunov A 、 Umari P 和 Wentzcovitch R M 2009 量子濃縮咖啡:材料量子模擬的模塊化開源軟件項目物理學雜志:凝聚態 21 395502
[6] Humphrey W , Dalke A 和 Schulten K 1996 VMD :分子圖形可視化分子動力學雜志 14 33-8
[7] 張玉芝、王海迪、陳偉杰、曾金哲、張林峰、王漢和魏 Nan E , DP-GEN :基于可靠深度學習的勢能模型生成的并行學習平臺,計算機物理通信, 2020 , 107206 。