本文是加速數據分析系列文章的一部分。
如果您想將您的機器學習( ML )項目的速度和可擴展性提升到新的水平,GPU 加速的數據分析可以幫助您以突破性的性能快速提供見解。從更快的計算到高效的模型訓練,GPU 為日常 ML 任務帶來了許多好處。
本帖子提供了以下方面的技術最佳實踐:
- 加速基本的 ML 技術,如分類、聚類和回歸
- 使用預處理時間序列數據,有效地訓練 ML 模型,并使用RAPIDS,一套開源庫,完全在 GPU 上執行數據科學和分析管道。
- 了解算法性能以及用于每個 ML 任務的評估指標
使用 GPU 加速數據科學管道
GPU – 加速的數據分析可以通過 RAPIDS cuDF ,一個 GPU DataFrame 庫和 RAPIDS cuML ,一種 GPU – 加速的 ML 庫來實現。
cuDF 是一個 Python GPU 數據框庫,基于 Apache Arrow 柱狀內存格式構建,用于加載、連接、聚合、過濾和操作數據。它的 API 與 pandas 類似,一個建立在 Python 之上的開源軟件庫,專門用于數據操作和分析。這使得它成為數據分析工作流的有用工具,包括為 ML 準備數據框的數據預處理和探索任務。要了解有關如何使用 cuDF 加速數據分析管道的更多信息,請參閱 加速數據分析系列。
一旦您的數據經過預處理,cuDF 與 cuML 就可以無縫集成,cuML 利用 GPU 加速提供了一套大型 ML 算法,可以幫助大規模執行復雜的 ML 任務,比基于 CPU 的框架scikit-learn快得多。
cuML 提供了一個簡單的 API ,它與 scikit-learn API 非常相似,因此很容易集成到現有的 ML 項目中。通過 cuDF 和 cuML ,從事 ML 項目的數據科學家和數據分析師可以通過數據管道上的 GPU 加速功能,輕松地與最流行的開源數據科學工具進行交互。這最大限度地減少了推進 ML 工作流的采用時間。
注:此資源與 cuML 和 cuDF 一起介紹 ML ,演示用于學習目的的常見算法。它并不是功能工程或模型構建的最終指南。每個 ML 場景都是唯一的,可能需要自定義技術。在構建 ML 模型時,請始終考慮您的問題細節。
了解 Meteonet 數據集
在深入分析之前,了解Meteonet 數據集,非常適合用于時間序列分析。這個數據集是一個全面的天氣數據集,對氣象學研究人員和數據科學家都有很大的幫助。
Meteonet 數據集的概述以及每一列的含義如下:
number_sta:每個氣象站的唯一標識符。lat和lon:氣象站的緯度和經度,代表其地理位置。height_sta:氣象站海拔高度,單位為米。date:數據記錄的日期和時間,對時間序列分析至關重要。dd:風向,以度為單位,表示風向。ff:風速,單位為米/秒。precip:降水量,單位為毫米。hu:濕度,以百分比表示,表示空氣中水蒸氣的濃度。td:露點溫度,單位為攝氏度,表示空氣何時被濕氣飽和。t:空氣溫度,單位為攝氏度。psl:海平面的大氣壓力,單位為百帕(百帕斯卡)。
使用 RAPIDS 進行機器學習
本教程介紹了 cuDF 和 cuML 的三種基本 ML 算法的加速:回歸、分類和聚類。
安裝
在分析 Meteonet 數據集之前,請安裝并設置 RAPIDS cuDF 和 cuML。請參考 RAPIDS 安裝指南,獲取根據您的系統要求的說明。
分類
Classification(分類)是一種 ML 算法,用于基于一組特征預測分類值。在這種情況下,目標是利用溫度、濕度和其他因素預測天氣條件(如晴天、多云或下雨)和風向。
使用隨機森林這種強大且通用的 ML 方法,我們可以執行回歸和分類任務。本節使用 cuML 隨機森林分類器對特定時間和地點的天氣條件和風向進行分類,并用準確性來評估模型的性能。
在本教程中,將 3 年的西北站數據合并為一個名為 NW_data.csv 的數據幀。要查看完整的合并數據步驟,請訪問 cuML 中的機器學習介紹 筆記本,位于 GitHub 上。
import cudf, cuml
from cuml.ensemble import RandomForestClassifier as cuRF
# Load data
df = cudf.read_csv('./NW_data.csv').dropna()
要準備數據進行分類,請執行預處理任務,例如將日期列轉換為日期時間格式和提取小時。
# Convert date column to datetime and extract hour
df['date'] = cudf.to_datetime(df['date'])
df['hour'] = df['date'].dt.hour
# Drop the original 'date' column
df = df.drop(['date'], axis=1)
創建兩個新的分類列:wind_direction和weather_condition。
對于wind_direction,離散化dd列(假設風向以度為單位)分為四類:北( 0-90 度)、東( 90-180 度)、南( 180-270 度)和西( 270-360 度)。
# Discretize wind direction
df['wind_direction'] = cudf.cut(df['dd'], bins=[-0.1, 90, 180, 270, 360], labels=['N', 'E', 'S', 'W'])
對于weather_condition,將沉淀柱(即降水量)離散為三類:sunny(無雨),cloudy(小雨),以及rainy(更多降雨)。
# Discretize weather condition based on precipitation amount
df['weather_condition'] = cudf.cut(df['precip'], bins=[-0.1, 0.1, 1, float('inf')], labels=['sunny', 'cloudy', 'rainy'])
然后將這些分類列轉換為數字標簽RandomForestClassifier可以使用.cat.codes.
# Convert 'wind_direction' and 'weather_condition' columns to category
df['wind_direction'] = df['wind_direction'].astype('category').cat.codes
df['weather_condition'] = df['weather_condition'].astype('category').cat.codes
模特培訓
現在預處理已經完成,下一步是定義一個函數來預測風向和天氣條件:
def train_and_evaluate(target):
# Split into features and target
X = df.drop(target, axis=1)
y = df[target]
# Split the dataset into training set and test set
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# Define the model
model = cuRF()
# Train the model
model.fit(X_train, y_train)
# Make predictions
predictions = model.predict(X_test)
# Evaluate the model
accuracy = accuracy_score(y_test, predictions)
print(f"Accuracy for predicting {target} is {accuracy}")
return model
現在函數已經準備好了,下一步是使用以下調用來訓練模型,并提及目標變量:
# Train and evaluate models
weather_condition_model = train_and_evaluate('weather_condition')
wind_direction_model = train_and_evaluate('wind_direction')
本教程使用 cuML 隨機森林分類器對西北數據集中的天氣條件和風向進行分類。預處理步驟包括轉換日期列、離散風向和天氣條件,以及將分類列轉換為數字標簽。使用準確性作為評估指標對模型進行訓練和評估。
回歸
回歸是一種機器學習算法,用于基于一組特征來預測連續值。例如,您可以使用回歸來根據房子的特征,如臥室的數量、面積和位置,來預測房子的價格。
線性回歸是一種流行的算法,用于預測定量響應。在本教程中,我們將使用 cuML 的線性回歸實現來預測不同時間和地點的溫度、濕度和降水量。R ^ 2 分數可用于評估回歸模型的性能,更多信息請參閱線性回歸。
首先導入此節所需的庫:
from cuml import make_regression, train_test_split
from cuml.linear_model import LinearRegression as cuLinearRegression
from cuml.metrics.regression import r2_score
from cuml.preprocessing.LabelEncoder import LabelEncoder
接下來,通過將 NW _ data . csv 文件讀取到數據幀中并刪除任何缺少值的行來加載 NW 數據集:
# Load data
df = cudf.read_csv('/NW_data.csv').dropna()
想要了解如何下載 NW _ data . csv 的詳細步驟,請訪問 GitHub 上的 Introduction to Machine Learning Using cuML 筆記本。
對于許多 ML 算法,分類輸入數據必須轉換為數字形式。對于這個例子,number_sta,表示“車站編號”,使用 LabelEncoder 進行轉換, LabelEncode 為每個類別分配唯一的數值。
接下來,必須對數字特征進行規范化,以防止模型因可變尺度而產生偏差。
然后將“日期”列轉換為“小時”功能,因為天氣模式通常與一天中的時間相關。最后,刪除“日期”列,因為使用的模型無法直接處理此列。
# Convert categorical variables to numeric variables
le = LabelEncoder()
df['number_sta'] = le.fit_transform(df['number_sta'])
# Normalize numeric features
numeric_columns = ['lat', 'lon', 'height_sta', 'dd', 'ff', 'hu', 'td', 't', 'psl']
for col in numeric_columns:
if df[col].dtype != 'object':
df[col] = (df[col] - df[col].mean()) / df[col].std()
else:
print(f"Skipping normalization for non-numeric column: {col}")
# Convert date column to datetime and extract hour
df['date'] = cudf.to_datetime(df['date'])
df['hour'] = df['date'].dt.hour
# Drop the original 'date' column
df = df.drop(['date'], axis=1)
模特培訓和表現
預處理完成后,下一步是定義一個函數,該函數訓練兩個模型來預測溫度和濕度?氣象站。
要評估回歸模型的性能,請使用決定系數 R ^ 2 。較高的 R ^ 2 表示模型能夠更好地預測數據。
def train_and_evaluate(target):
# Split into features and target
X = df.drop(target, axis=1)
y = df[target]
# Split the dataset into training set and test set
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# Define the model
model = cuLinearRegression()
# Train the model
model.fit(X_train, y_train)
# Make predictions
predictions = model.predict(X_test)
# Evaluate the model
r2 = r2_score(y_test, predictions)
print(f"R^2 score for predicting {target} is {r2}")
return model
現在已經編寫了函數,下一步是使用以下調用來訓練模型,指定目標變量:
# Train and evaluate models
temperature_model = train_and_evaluate('t')
humidity_model = train_and_evaluate('hu')
本示例演示了如何使用 cuML 線性回歸來使用西北數據集預測溫度、濕度和降水量。為了評估回歸模型的性能,我們使用了 R ^ 2 分數。值得注意的是,通過探索特征選擇、正則化和高級模型等技術,可以進一步提高模型性能。
聚類
聚類是一種無監督的機器學習( ML )技術,用于根據相似實例的特征對其進行分組。它有助于識別數據中的模式和結構。本節探討了使用 K-Means (一種流行的基于質心的聚類算法)基于溫度和降水對天氣條件進行聚類。
首先,對數據集進行預處理。關注兩個具體特征:溫度 (t) 和降水 (pp) 。為了簡單起見,將刪除任何缺少值的行。
import cudf
from cuml import KMeans
# Load data
df = cudf.read_csv("/NW_data.csv").dropna()
# Select the features for clustering
features = ['t', 'pp']
df_kmeans = df[features]
接下來,將 K-Means 聚類應用于數據。目標是將數據劃分為指定數量的集群,每個集群由其中數據點的平均值表示。
# Initialize the KMeans model
kmeans = KMeans(n_clusters=5, random_state=42)
# Fit the model
kmeans.fit(df_kmeans)
擬合模型后,檢索聚類標簽,指示每個數據點所屬的聚類。
# Get the cluster labels
kmeans_labels = kmeans.labels_
# Add the cluster labels as new columns to the dataframe
df['KMeans_Labels_Temperature'] = cudf.Series(kmeans_labels)
df['KMeans_Labels_Precipitation'] = cudf.Series(kmeans_labels)
模特培訓和表現
為了評估聚類模型的質量,請檢查慣性,慣性表示每個數據點與其最近質心之間距離的平方和。慣性值越低,表示簇越緊密、越明顯。
# Print the inertia values
print("Temperature Inertia:")
print(kmeans.inertia_)
print("Precipitation Inertia:")
print(kmeans.inertia_)
確定 K-Means 中聚類的最佳數量是至關重要的。Elbow 方法可以通過繪制不同簇編號的慣性值,幫助找到理想的編號。“彎頭”點表示最小化慣性和避免過多集群之間的最佳平衡。要進一步探索 Elbow 方法,請訪問 GitHub 上的 Introduction to Machine Learning Using cuML 筆記本。
UMAP 在 cuML 中提供,是一種強大的降維算法,用于可視化高維數據和揭示潛在模式。雖然 UMAP 本身不是一種專用的聚類算法,但其將數據投影到低維空間的能力往往揭示了聚類結構。它被廣泛用于聚類探索和分析,為數據提供了有價值的見解。它在 cuML 中的高效實現實現了用于集群任務的高級數據分析和模式識別。
部署 cuML 模
一旦您訓練了 cuML 模型,就可以將其部署到 NVIDIA Triton,這是一款開源、可擴展、可生產的推理服務器,可用于將 cuML 模型部署到云、本地和邊緣設備等各種平臺。
在生產環境中有效地部署經過培訓的 cuML 模型對于充分挖掘其潛力至關重要。對于使用 cuML 訓練的模型,有兩種主要方法:
- Triton 的 FIL 后端
- Triton Python 后端
NVIDIA 的 FIL 后端 Triton
Triton 的 FIL 后端使 Triton ‘用戶能夠利用 cuML 的森林推理庫( FIL )來加速樹模型的推理,包括決策林和梯度增強林。這個 Triton 后端提供了一種高度優化的方法來部署林模型,而不管使用什么框架來訓練它們。
它提供了對 XGBoost 和 LightGBM 模型的原生支持,以及對使用 Treelite 序列化格式的 cuML 和 Scikit Learn 樹模型的支持。雖然 FIL GPU 模式提供了最先進的 GPU – 加速性能,但它也為原型部署或部署提供了優化的 CPU 模式,在這些部署中,極小的批處理延遲比整體吞吐量更重要。
要開始,請參考使用 XGBoost 和 Triton-FIL 的欺詐檢測入門教程。要深入了解如何在 Triton 上部署樹模型,請參閱FIL Backend 常見問題筆記本。
Triton Python 后端
部署模型的另一種靈活方法使用 Triton Python 后端。這個后端使您能夠直接調用 RAPIDS Python 庫。它非常靈活,因此您可以編寫自定義的 Python 腳本來處理預處理和后處理。
要使用 Python Python 后端部署 cuML 模型,您需要:
- 寫一個Python 腳本,Triton 服務器可以調用它來進行推理。該腳本應處理任何必要的預處理和后處理。
- 配置 Triton 推理服務器以使用此 Python 腳本為您的模型提供服務。
在所有情況下, Triton 推理服務器都為所有模型提供了統一的接口, Triton 推理服務器為所有模型(無論其框架如何)提供了統一接口,使其更容易集成到現有的服務和基礎設施中。它還實現了傳入請求的動態批處理,減少了計算資源,從而降低了部署成本。
基準 RAPIDS
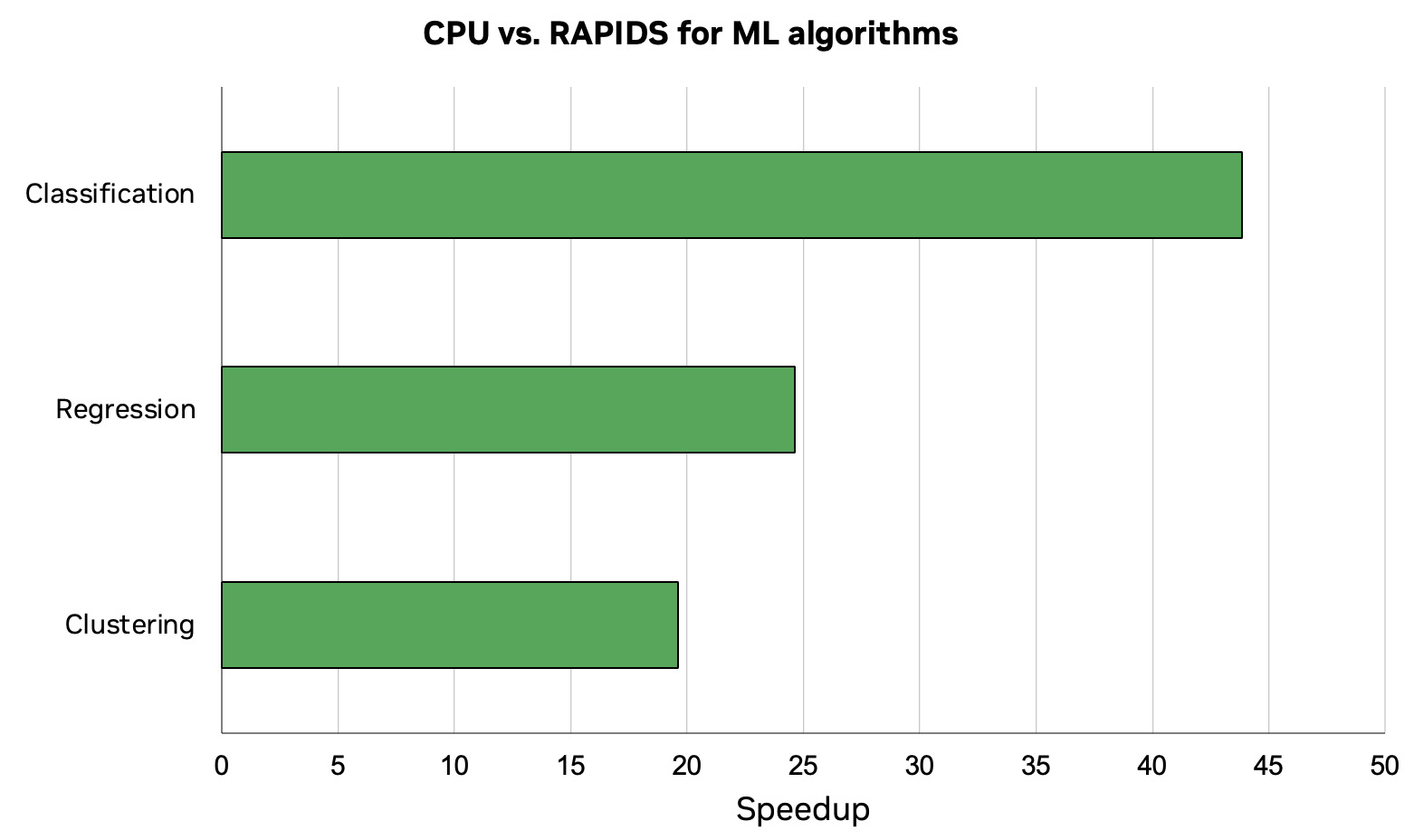
這篇文章摘自 使用 cuML 進行機器學習介紹 的 GitHub 筆記本。該工作流程使數據加載、預處理和 ML 訓練的組合工作流程的速度提高了 44 倍。這些結果是在 NVIDIA RTX 8000 GPU 上使用 RAPIDS 23.04 和英特爾酷睿 i7-7800X CPU 進行測試得出的。
結論
GPU – 使用 cuDF 和 cuML 加速機器學習可以大大加快您的數據科學管道。通過使用 cuDF 和 cuML 科學學習兼容 API 進行更快的數據預處理,很容易開始利用 GPU 的強大功能進行機器學習。
要深入了解本文中討論的概念,請訪問 GitHub 上的 Introduction to Machine Learning Using cuML 筆記本。了解更多關于 GPU 加速的數據科學工作流程 的信息。
?