線性回歸是一種強大的統計工具,用于對因變量和一個或多個自變量(特征)之間的關系進行建模。回歸分析中一個重要且經常被遺忘的概念是交互作用項。簡而言之,交互術語使您能夠檢查目標和自變量之間的關系是否會根據另一個自變量的值而變化。
交互術語是回歸分析的一個關鍵組成部分,了解它們的工作原理可以幫助從業者更好地訓練模型和解釋數據。然而,盡管交互術語很重要,但它們可能很難理解。
這篇文章提供了線性回歸背景下交互作用術語的直觀解釋。
回歸模型中的交互項是什么?
首先,這是一個更簡單的案例;也就是說,一個沒有相互作用項的線性模型。這樣的模型假設每個特征或預測器對因變量(目標)的影響獨立于模型中的其他預測器。
以下等式描述了具有兩個特征的此類模型規范:
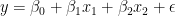
為了使解釋更容易理解,這里有一個例子。想象一下,你對房地產價格建模感興趣 (y) 使用兩個功能:它們的大小 (X1 個) 以及指示公寓是否位于市中心的布爾標志 (2 個) .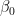

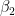

在收集數據并估計線性回歸模型后,可以獲得以下系數:

知道估計的系數和2 個是一個布爾功能,您可以根據的值寫出兩種可能的情況2 個.
市中心
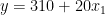
市中心外
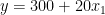
如何解讀這些?雖然這在房地產領域可能沒有多大意義,但你可以說,市中心一套 0 平方米的公寓的價格是 310 (截距的價值)。每增加一平方米的空間,價格就會上漲 20 。在另一種情況下,唯一的區別是截距小于 10 個單位。圖 1 顯示了兩條最佳擬合線。
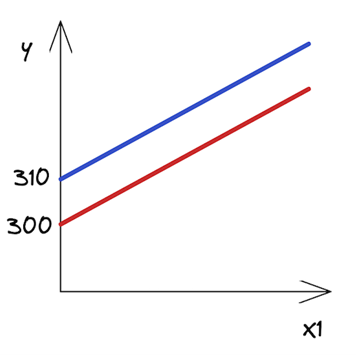
正如你所看到的,這些線是平行的,它們有相同的斜率 — 系數由X1 個,這在兩種情況下都是一樣的。
交互作用術語表示聯合效應
在這一點上,你可能會爭辯說,在市中心的公寓里多住一平方米比在郊區的公寓里多花一平方米要貴。換句話說,這兩個特征可能會對房地產價格產生共同影響。
所以,你認為不僅兩種情況下的截距應該不同,而且直線的斜率也應該不同。如何做到這一點?這正是互動術語發揮作用的時候。它們使模型的規范更加靈活,并使您能夠考慮到這些模式。
交互項實際上是你認為對目標有共同影響的兩個特征的乘積。以下等式表示模型的新規范:
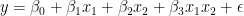
再次假設你已經估計了你的模型,并且你知道系數。為了簡單起見,我保留了與前面示例中相同的值。請記住,在現實生活中,它們可能會有所不同。
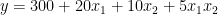
市中心
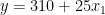
市中心外
在你寫出兩個場景之后2 個(市中心或市中心外),您可以立即看到坡度(系數X1 個) 兩條線中的一條不同。正如假設的那樣,現在市中心增加一平方米的空間比郊區更貴。
用交互項解釋系數
向模型中添加交互項會改變對所有系數的解釋。如果沒有交互項,則可以將系數解釋為預測器對因變量的獨特影響。
所以在這種情況下,你可以這么說
為了更好地理解每個系數代表什么,這里再看一看具有交互項的線性模型的原始規范。作為提醒,2 個是一個布爾特征,指示特定公寓是否位于市中心。
現在,您可以通過以下方式解釋每個系數:
: 市中心和城外公寓之間的坡度差異。
例如,假設你正在測試一個假設,即無論公寓是否在市中心,公寓的大小對價格的影響都是相等的。然后,您將使用交互項來估計線性回歸,并檢查
關于交互術語的一些附加注釋:
- 我提出了雙向交互術語;然而,高階相互作用(例如,三個特征的相互作用)也是可能的。
- 在這個例子中,我展示了一個數字特征(公寓的大小)與布爾特征(公寓在市中心嗎?)的交互。但是,您也可以為兩個數字特征創建交互項。例如,您可以創建一個公寓大小與房間數量的交互項。有關詳細信息,請參閱相關資源部分。
- 這種情況下,相互作用項可能具有統計學意義,但主要影響并不顯著。然后,你應該遵循分層原則,即如果你在模型中包括一個交互項,你也應該包括主要影響,即使它們的影響在統計上并不顯著。
Python 中的實際操作示例
在所有的理論介紹之后,下面是如何在 Python 中為線性回歸模型添加交互項。一如既往,首先導入所需的庫。
import numpy as npimport pandas as pdimport statsmodels.api as smimport statsmodels.formula.api as smf# plottingimport seaborn as snsimport matplotlib.pyplot as plt# settingsplt.style.use("seaborn-v0_8")sns.set_palette("colorblind")plt.rcParams["figure.figsize"] = (16, 8)%config InlineBackend.figure_format = 'retina' |
在本例中,您使用statsmodels圖書館對于數據集,使用mtcars數據集。我敢肯定,如果你曾經使用過 R ,你就會對這個數據集很熟悉。
首先,加載數據集:
mtcars = sm.datasets.get_rdataset("mtcars", "datasets", cache=True)print(mtcars.__doc__) |
執行代碼示例將打印數據集的全面描述。在這篇文章中,我只展示了相關部分 — 列的總體描述和定義:
====== ===============mtcars R Documentation====== =============== |
數據摘自 1974 年的美國雜志MotorTrend,由 32 輛汽車( 1973-74 車型)的油耗和汽車設計和性能的 10 個方面組成。
這是一個 DataFrame ,它對 11 個(數字)變量進行了 32 次觀測:
===== ==== ========================================[, 1] mpg Miles/(US) gallon[, 2] cyl Number of cylinders[, 3] disp Displacement (cu.in.)[, 4] hp Gross horsepower[, 5] drat Rear axle ratio[, 6] wt Weight (1000 lbs)[, 7] qsec 1/4 mile time[, 8] vs Engine (0 = V-shaped, 1 = straight)[, 9] am Transmission (0 = automatic, 1 = manual)[,10] gear Number of forward gears[,11] carb Number of carburetors===== ==== ======================================== |
然后,從加載的對象中提取實際數據集:
df = mtcars.datadf.head() |
| ? | 英里/加侖 | 氣缸 | 顯示 | 馬力 | 德拉特 | 重量 | 質量安全委員會 | 對 | 是 | 排擋 | 碳水化合物 |
| 馬自達 RX4 | 21 | 6 | 160 | 110 | 3 . 90 | 2 . 620 | 16 . 46 | 0 | 1 | 4 | 4 |
| 馬自達 RX4 Wag | 21 | 6 | 160 | 110 | 3 . 90 | 2 . 875 | 17 . 02 | 0 | 1 | 4 | 4 |
| 達特桑 710 | 22 . 8 | 4 | 108 | 93 | 3 . 85 | 2 . 320 | 18 . 61 | 1 | 1 | 4 | 1 |
| 大黃蜂 4 號驅動器 | 21 . 4 | 6 | 258 | 110 | 3 . 08 | 3 . 215 | 19 . 44 | 1 | 0 | 3 | 1 |
| 大黃蜂運動型 | 18 . 7 | 8 | 360 | 175 | 3 . 15 | 3 . 440 | 17 . 02 | 0 | 0 | 3 | 2 |
對于這個例子,假設你想調查每加侖英里數之間的關系 (mpg) 和兩個特征:重量 (wt,連續)和變速器類型 (am,布爾值)。
首先,繪制數據以獲得一些初步見解:
sns.lmplot(x="wt", y="mpg", hue="am", data=df, fit_reg=False)plt.ylabel("Miles per Gallon")plt.xlabel("Vehicle Weight"); |
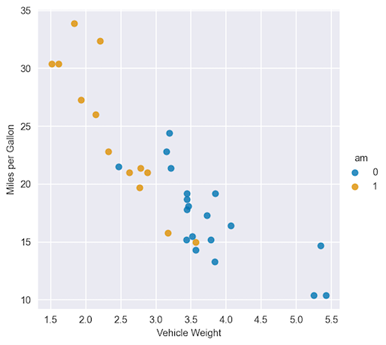
通過觀察圖 2 ,您可以看到 am 變量的兩個類別的回歸線將大不相同。為了進行比較,從一個沒有交互項的模型開始。
model_1 = smf.ols(formula="mpg ~ wt + am", data=df).fit()model_1.summary() |
下表顯示了在沒有交互項的情況下擬合線性回歸的結果。
OLS Regression Results
==============================================================================
Dep. Variable: mpg R-squared: 0.753
Model: OLS Adj. R-squared: 0.736
Method: Least Squares F-statistic: 44.17
Date: Sat, 22 Apr 2023 Prob (F-statistic): 1.58e-09
Time: 23:15:11 Log-Likelihood: -80.015
No. Observations: 32 AIC: 166.0
Df Residuals: 29 BIC: 170.4
Df Model: 2
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
Intercept 37.3216 3.055 12.218 0.000 31.074 43.569
wt -5.3528 0.788 -6.791 0.000 -6.965 -3.741
am -0.0236 1.546 -0.015 0.988 -3.185 3.138
==============================================================================
Omnibus: 3.009 Durbin-Watson: 1.252
Prob(Omnibus): 0.222 Jarque-Bera (JB): 2.413
Skew: 0.670 Prob(JB): 0.299
Kurtosis: 2.881 Cond. No. 21.7
==============================================================================
從匯總表中可以看出, am 特征的系數在統計上并不顯著。使用您已經學習的系數的解釋,您可以為 am 特征的兩類繪制最佳擬合線。
X = np.linspace(1, 6, num=20)sns.lmplot(x="wt", y="mpg", hue="am", data=df, fit_reg=False)plt.title("Best fit lines for from the model without interactions")plt.ylabel("Miles per Gallon")plt.xlabel("Vehicle Weight")plt.plot(X, 37.3216 - 5.3528 * X, "blue")plt.plot(X, (37.3216 - 0.0236) - 5.3528 * X, "orange"); |
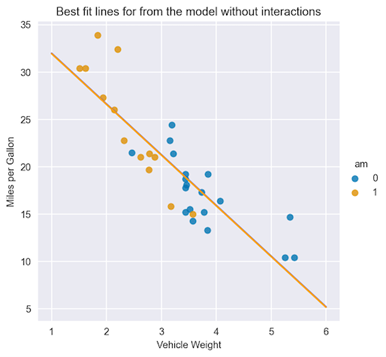
圖 3 顯示了線條幾乎重疊,因為 am 特征的系數基本為零。
接下來是第二個模型,這一次是兩個功能之間的交互項。以下是如何在statsmodels公式
model_2 = smf.ols(formula="mpg ~ wt + am + wt:am", data=df).fit()model_2.summary() |
以下匯總表顯示了用交互項擬合線性回歸的結果。
OLS Regression Results
==============================================================================
Dep. Variable: mpg R-squared: 0.833
Model: OLS Adj. R-squared: 0.815
Method: Least Squares F-statistic: 46.57
Date: Mon, 24 Apr 2023 Prob (F-statistic): 5.21e-11
Time: 21:45:40 Log-Likelihood: -73.738
No. Observations: 32 AIC: 155.5
Df Residuals: 28 BIC: 161.3
Df Model: 3
Covariance Type: nonrobust
===============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
Intercept 31.4161 3.020 10.402 0.000 25.230 37.602
wt -3.7859 0.786 -4.819 0.000 -5.395 -2.177
am 14.8784 4.264 3.489 0.002 6.144 23.613
wt:am -5.2984 1.445 -3.667 0.001 -8.258 -2.339
==============================================================================
Omnibus: 3.839 Durbin-Watson: 1.793
Prob(Omnibus): 0.147 Jarque-Bera (JB): 3.088
Skew: 0.761 Prob(JB): 0.213
Kurtosis: 2.963 Cond. No. 40.1
==============================================================================
以下是您可以從具有交互項的匯總表中快速得出的兩個結論:
- 所有的系數,包括相互作用項,都具有統計學意義。
- 通過檢查 R2 (及其調整后的變體,因為模型中有不同數量的功能),您可以聲明具有交互項的模型會產生更好的擬合。
與前面的情況類似,繪制最佳擬合線:
X = np.linspace(1, 6, num=20)sns.lmplot(x="wt", y="mpg", hue="am", data=df, fit_reg=False)plt.title("Best fit lines for from the model with interactions")plt.ylabel("Miles per Gallon")plt.xlabel("Vehicle Weight")plt.plot(X, 31.4161 - 3.7859 * X, "blue")plt.plot(X, (31.4161 + 14.8784) + (-3.7859 - 5.2984) * X, "orange"); |
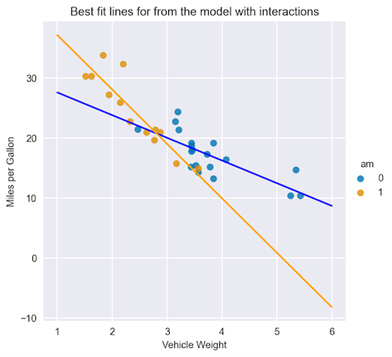
在圖 4 中,您可以立即看到配備自動變速器和手動變速器的汽車在截距和坡度方面的擬合線差異。
這里有一個好處:您還可以使用添加交互術語scikit-learn的PolynomialFeaturestransformer 不僅提供了添加任意階的交互項的可能性,而且還創建了多項式特征(例如,可用特征的平方值)。有關詳細信息,請參閱sklearn.preprocessing.PolynomialFeatures.
結束語
在處理線性回歸中的交互項時,需要記住以下幾點:
- 交互術語使您能夠檢查目標和功能之間的關系是否會根據另一個功能的值而變化。
- 添加交互項作為原始特征的乘積。通過將這些新變量添加到回歸模型中,可以測量它們與目標之間相互作用的效果。仔細解釋相互作用項的系數對于理解關系的方向和強度至關重要。
- 通過使用交互項,可以使線性模型的規范更加靈活(不同線的斜率不同),從而更好地擬合數據并具有更好的預測性能。
你可以在我的/erykmlGitHub 查看代碼。一如既往,任何建設性的反饋都是非常受歡迎的。
相關資源
- Interpreting Interactions OLS
- Interactions between continuous variables
- Chapter 13: Plotting Regression Interactions
- Exploring Linear Regression Coefficients and Interactions
?