SERVIDOR DE INFERêNCIA NVIDIA TRITON
O Servidor de Inferência NVIDIA Triton? é um software de servi?o de inferência de código aberto que ajuda a padronizar a implanta??o e a execu??o do modelo e oferece AI rápida e escalável na produ??o.
COME?ARO que é o NVIDIA Triton?
O Servidor de Inferência Triton simplifica a inferência da AI, permitindo que as equipes implantem, executem e dimensionem modelos de AI treinados a partir de qualquer framework em qualquer infraestrutura baseada em GPU ou CPU. Ele oferece aos pesquisadores de AI e cientistas de dados a liberdade de escolher o framework certo para seus projetos sem afetar a implanta??o da produ??o. Ele também ajuda os desenvolvedores a fornecer inferência de alto desempenho no cloud, no local, no edge e em dispositivos incorporados.
Compatibilidade com Vários Frameworks
El Servidor de Inferencia Triton es compatible con todos los principales frameworks como TensorFlow, NVIDIA? TensorRT?, PyTorch, MXNet, Python, ONNX, RAPIDS FIL (para XGBoost, scikit-learn, etc.), OpenVINO, C++ personalizado y más.
Inferência de Alto Desempenho
O Triton suporta todas as inferências baseadas em CPU NVIDIA, x86 e ARM?. Ele oferece recursos como lotes dinamicos, execu??o simultanea, configura??o de modelo ideal, conjunto de modelos e entradas de streaming para maximizar o rendimento e a utiliza??o.
Projetado para DevOps e MLOps
O Triton se integra ao Kubernetes para orquestra??o e dimensionamento, exporta métricas do Prometheus para monitoramento, oferece suporte a atualiza??es de modelos ao vivo e pode ser usado em todas as principais plataformas de AI e Kubernetes de cloud público. Também está integrado em muitas solu??es de software MLOPS.
Acelere Sua Jornada de AI com o NVIDIA LaunchPad
Experimente o Servidor de Inferência Triton e outros softwares de AI da NVIDIA por meio de laboratórios gratuitos selecionados em infraestrutura hospedada.
Integra??es de Ecossistemas com o NVIDIA Triton
A AI está impulsionando a inova??o em empresas de todos os tamanhos e escalas. Uma solu??o de software de código aberto, o Triton é a melhor escolha para inferência de IA e implanta??o de modelos. Triton é compatÃvel com Alibaba Cloud, Amazon Elastic Kubernetes Service (EKS), Amazon Elastic Container Service (ECS), Amazon SageMaker, Google Kubernetes Engine (GKE), Google Vertex AI, HPE Ezmeral, Microsoft Azure Kubernetes Service (AKS) e Azure Machine Learning. Descubra por que as empresas usam o Triton.
Recursos de Inferência de AI da NVIDIA

Simplifique a Implanta??o de AI em Escala
Simplifique a implanta??o de modelos de AI em escala na produ??o. Saiba como o Triton enfrenta os desafios de implanta??o de modelos de AI e revise as etapas para come?ar.
FA?A DOWNLOAD DA VIS?O GERAL
Assista a Sess?es On Demand
Confira as últimas sess?es on demand do Servidor de Inferência Triton no NVIDIA GTC.
ASSISTA AGORA
Implante Modelos de Deep Learning de AI
Receba as últimas notÃcias e atualiza??es e saiba mais sobre as principais vantagens no Blog Técnico da NVIDIA.
LEIA OS BLOGS
Leia a Documenta??o do Produto
Veja o que há de novo e saiba mais sobre os recursos mais recentes nas notas de vers?o do Triton.
LEIA NO GITHUBAI Rápida e Escalável em Todas as Aplica??es
O Servidor de Inferência NVIDIA Triton oferece alta taxa de transferência de inferência:
O Triton executa vários modelos da mesma ou de diferentes frameworks simultaneamente em uma única GPU ou CPU. Em um servidor multi-GPU, o Triton cria automaticamente uma instancia de cada modelo em cada GPU para aumentar a utiliza??o.
Ele também otimiza o servi?o para inferência em tempo real sob restri??es estritas de latência, suporta inferência em lote para maximizar a utiliza??o de GPU e CPU e inferência de streaming com suporte integrado para entrada de streaming de áudio e vÃdeo. O Triton oferece suporte ao conjunto de modelos para casos de uso que exigem vários modelos para realizar inferência de ponta a ponta, como AI conversacional.
Os modelos podem ser atualizados ao vivo na produ??o sem reiniciar o Triton ou a aplica??o. O Triton permite inferência multi-GPU e multi-nó em modelos muito grandes que n?o cabem em uma única memória de GPU.
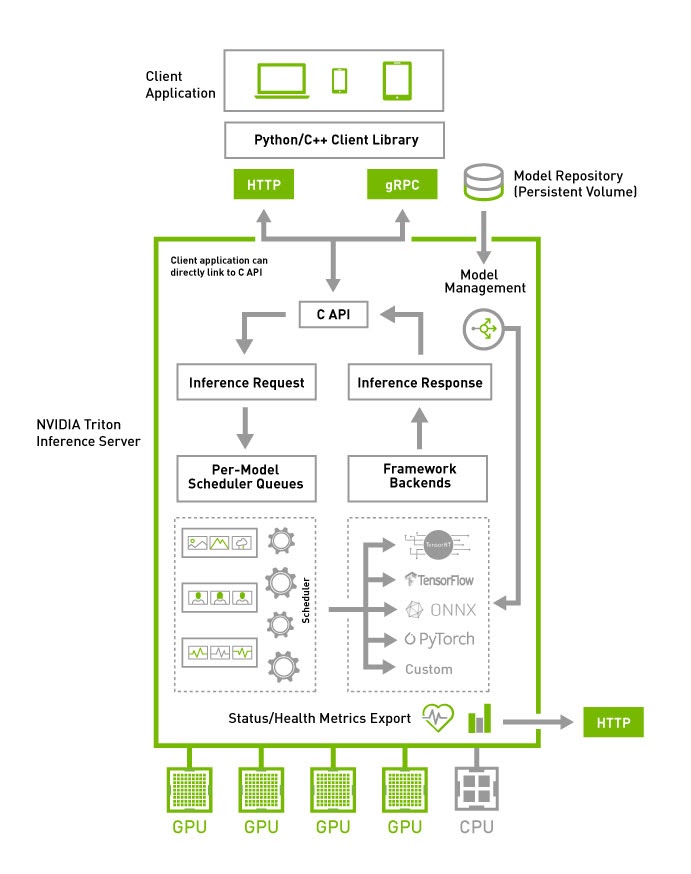

O Servidor de Inferência NVIDIA Triton oferece inferência altamente escalável:
Também disponÃvel como um contêiner do Docker, o Triton se integra ao Kubernetes para orquestra??o, métricas e dimensionamento automático. O Triton também se integra aos pipelines Kubeflow e Kubeflow para um workflow de AI de ponta a ponta e exporta métricas do Prometheus para monitorar a utiliza??o da GPU, latência, uso de memória e taxa de transferência de inferência. Ele suporta a interface HTTP/gRPC padr?o para conectar-se a outras aplica??es, como balanceadores de carga, e pode ser facilmente dimensionado para qualquer número de servidores para lidar com cargas de inferência crescentes para qualquer modelo.
O Triton pode servir dezenas ou centenas de modelos por meio de uma API de controle de modelos. Os modelos podem ser carregados e descarregados dentro e fora do servidor de inferência com base nas altera??es para caber na memória da GPU ou CPU. O suporte a um cluster heterogêneo com GPUs e CPUs ajuda a padronizar a inferência entre plataformas e dimensiona dinamicamente para qualquer CPU ou GPU para lidar com cargas de pico.
Principais CaracterÃsticas do Triton
Backend da Forest Inference Library (FIL) do Triton
O novo back-end da Forest Inference Library (FIL) fornece suporte para inferência de alto desempenho de modelos baseados em árvore com explicabilidade (valores Shapley) em CPUs e GPUs. Ele suporta modelos de XGBoost, LightGBM, scikit-learn RandomForest, RAPIDS cuML RandomForest e outros no formato Treelite.
Servi?o de Gerenciamento Triton
O Servi?o de Gerenciamento Triton (TMS) aborda o desafio de dimensionar com eficiência as instancias do Triton com um grande número de modelos. O TMS é um servi?o que ajuda quando há mais modelos do que podem caber em uma única GPU e quando muitas instancias do Triton s?o necessárias em servidores para lidar com solicita??es de inferência de diferentes aplica??es.
Em Breve
Analisador de Modelo Triton
O Analisador de Modelo Triton é uma ferramenta para avaliar automaticamente as configura??es de implanta??o do Triton, como tamanho do lote, precis?o e instancias de execu??o simultanea no processador de destino. Ele ajuda a selecionar a configura??o ideal para atender às restri??es de qualidade de servi?o (QoS) da aplica??o: latência, taxa de transferência e requisitos de memória. Reduz o tempo necessário para encontrar a configura??o ideal de semanas para horas.
Programa da NVIDIA para Startups
O NVIDIA Inception é um programa gratuito projetado para ajudar as startups a evoluir mais rapidamente por meio do acesso à tecnologia de ponta, como NVIDIA Triton, especialistas da NVIDIA, capitalistas de risco e suporte de co-marketing.
SAIBA MAIS
Você também pode fazer o download do Servidor de Inferência Triton no NGC. Se você estiver interessado em suporte empresarial, saiba mais sobre a NVIDIA AI Enterprise.