本記事は ABEJA、NVIDIA で共同執筆しています。ABEJA にて公開しているブログについてはこちらを參照してください。
本記事の取り組みは、経済産業省と NEDO が実施する、國內の生成 AI の開発力強化を目的としたプロジェクト「GENIAC (Generative AI Accelerator Challenge)」での ABEJA の成果の 1 つとなります。今回は、プロジェクトの中で実施した大規模言語モデル (LLM) の蒸留 (Knowledge Distillation) に関する技術的な取り組みをご紹介します。蒸留の成果については、ABEJA が公開している記事で既に紹介しています。
本記事では、特に NeMo Framework における蒸留の仕組みと大規模なモデルを効率的に蒸留する際の技術的課題および ABEJA ではどのように実裝したのかについてご紹介します。
蒸留とは
蒸留 (Distillation)とは、大規模な教師モデル (Teacher) の知識を、小規模な生徒モデル (Student) に転移する技術です。一般的には、學習済みの高性能モデルの知識を小さいモデルに引き継ぐことで高い精度を保ちつつ軽量化が可能になるというメリットがあります。
蒸留を行うことで、通常通りの SFT (Supervised Fine-Tuning) を行うよりも、高い精度を達成できるとの報告が多くされており、我々も蒸留を実施することにしました。蒸留は教師モデルの知識を生徒モデルに転移する仕組みであるため、學習前の生徒モデルが教師モデルと近いほど學習が容易になります。そのため、教師モデルの枝刈り (Pruning) をして小型化をしたものに対して蒸留を行うケースが多いです。一方で、枝刈りを利用すると蒸留後の小型モデルに対して差分マージなどを適用することができなくなってしまう可能性があると考えたため、今回は別途學習済みの小型モデルをベースとして蒸留を行い、その上で ChatVector を適用する方針としました。
蒸留では、教師モデルと生徒モデルの出力の差分を loss にします。一般的な手法としては、出力の soft target を loss 関數として使う方法や、中間層の出力を合わせる方法 (Intermediate Layer Matching) などがあります。今回は教師モデルと生徒モデルのベースモデルが異なるものであるため、中間層を合わせる方法は採用せず、最終レイヤーの soft target を loss として利用することとしました。

NeMo と Megatron-Core
NVIDIA NeMo Framework は、NVIDIA が提供する大規模言語モデル (LLM) をはじめとした生成 AI モデルの學習、推論、蒸留などを支援するライブラリであり、內部で Megatron-LM に含まれる Megatron-Core の技術を活用しています。
Megatron-Core は大規模モデルの分散學習のための豊富な手法を提供しており、具體的には以下のような並列學習手法をサポートしています。
- Data Parallelism
- Fully Sharded Data Parallelism (FSDP)
- Tensor Parallelism
- Pipeline Parallelism
- Sequence Parallelism
- Expert Parallelism
- Context Parallelism
これらの仕組みをうまく組み合わせることで、複數の計算ノード、GPU を使用して効率的に大規模モデルを學習することが可能です。例えば Tensor Parallelism では、テンソルを特定の次元に沿って分割し、各 GPU は分割されたテンソルのみ処理することで計算量/メモリ使用量を抑えることができます。

Pipeline Parallelism では、レイヤーを複數のステージに分けて、それぞれを並列に処理します。例えば GPU が 4 枚あり、24 層のネットワークを、6 レイヤーずつ 4 つのステージに分割したとします。1 個目のデータが入力されたら最初のデバイスで 6 レイヤー分の forward 計算を行い、次のデバイスにデータを送信します。次のタイミングでは、先ほど処理した 1 個目のデータを 2 個目のデバイスで続きの 6 レイヤー分の forward 計算を行い、それと同時に 2 個目のデータを新たに最初のデバイスに投入し forward 計算を行います。このようにデバイスごとにステージを割り當てて並列処理を行います。

NeMo は、Megatron-Core をベースに、大規模モデルの學習/推論/蒸留などを支援するライブラリです。自然言語だけではなく、畫像/動畫、音聲など様々なモデルをサポートしています。また、モデルのフルスクラッチの學習だけではなく継続事前學習や SFT、Parameter-Efficient Fine-Tuning (PEFT) などの Finetuning 手法もサポートしています。さらに、開発や実験を効率的に行うため、PyTorch Lightning や Hydra、WandB を統合しています。NeMo はそれを取り巻く様々なフレームワーク ライブラリがあり、NeMo-Aligner や NeMo-RL のような様々な Finetuning の手法が実裝されたライブラリや NeMo-Run という実験の設定/実行/管理を簡素化/構造化するツールなどとの連攜が可能です。
NeMo における蒸留の実裝
GENIAC で開発を進めていた 2025 年 2 月時點では、NeMo による蒸留の実裝はリポジトリの example 內の megatron_gpt_distillation.py にありました。ただし、當時は蒸留プロセスが Pipeline Parallelism に対応しておらず、大規模なモデルへの対応ができませんでした。そこで、ABEJA では獨自で蒸留を実裝することにしました。ちなみに、もう少し細かい事情ですが、ABEJA での蒸留実裝がスタートしたタイミングで、NeMo でも Pipeline Parallelism の実裝がスタートしておりプル リクエストがありました。しかし、そのコードを確認した所、次節で述べるメモリ問題があったため、我々は獨自での実裝を進めることとしました。ここでは、まずは當時の megatron_gpt_distillation.py について紹介します。
NeMo では、蒸留を行うために NVIDIA が提供する nvidia-modelopt (以下 modelopt) というライブラリを內部で使います。このライブラリは蒸留の他にモデルの量子化、枝刈り、投機的デコーディングなど様々な手法を利用することができます。NeMo で蒸留を行うために、GPTModel を継承した蒸留用のクラスを作成し、これを用います。通常、modelopt を用いて蒸留する場合、生徒モデルを先に用意しておき、以下のように教師モデルと生徒モデルを內部に持った蒸留用のモデルに変換できます。
model = mtd.convert(student_model, *mode*=[("kd_loss", kd_config)]) |
なお、kd_config にはロスの情報や、どのレイヤーの結果を蒸留の計算に利用するかなどを指示します。NeMo モデルの場合は、以下のように output_layer 同士を LogitsKLLoss で比較するように設定しています。なお、_teacher_provider は教師モデルを返す関數です。
logit_pair = ("output_layer", "output_layer")loss = LogitsKLLoss(*tensor_parallel*=tp_enabled)kd_config = { "teacher_model": (_teacher_provider, [self.cfg, copy.deepcopy(self.trainer)], {}), "criterion": {logit_pair: loss}, "loss_balancer": None,} |
megatron_gpt_distillation.py では、モデルの forward は get_forward_output_and_loss_func を継承して実裝しています。その中で、get_batch でデータを取得、output_tensor = model(**forward_args) でモデルの forward を行い、內部で定義された loss_func で先程のロスを計算します。ここまでは modelopt の蒸留の機能をそのまま統合するだけなので、比較的素直な実裝になっています。
Pipeline Parallelism に対応する際の課題
Megatron-Core の Pipeline Parallelism による並列化の難しさ
NeMo による蒸留は、2 月時點では Pipeline Parallelism には対応していませんでした。Pipeline Parallelism が難しい理由として、NeMo がバックエンドに利用している Megatron-Core の forward と backward の Pipeline Parallelism をする際のプロセスが原因の 1 つと考えます。Megatron-Core の Pipeline Parallelism の処理は megatron/core/pipeline_parallel/schedules.py にあり、先程の図に示したような global batch 全體を Pipeline Parallelism にするという流れになっています。例えば forward では、以下のようにして、前のステージからのデータを受け取り、該當ステージでの forward を行い、その後、現在のステージの出力を次のステージに送信します。
input_tensor = recv_forward(recv_tensor_shapes, config, parallel_state.is_pipeline_first_stage())output_tensor, num_tokens = forward_step(forward_step_func, data_iterator, model, ...)send_forward(output_tensor, send_tensor_shapes, config, parallel_state.is_pipeline_last_stage()) |
前のステージから受け取った中間データを recv_forward で input_tensor に格納し、上記 forward_step の中で以下のようにモデルの set_input_tensor を通し、モデルへ入力します。
set_input_tensor = get_attr_wrapped_model(model, "set_input_tensor")set_input_tensor(input_tensor) |
ところが、Pipeline Parallelism を適用する際にステージ間で転送されるデータの形式が、先程のソース コードにあったように recv_tensor_shapes という各レイヤーが出力するテンソルの出力の shape (B x S x H) に固定されています。送受信データの形が上記コードのように input_tensor という一種類のテンソルになってしまっているため、ここには教師モデルと生徒モデルの両方の出力を格納できません。そのため、megatron_gpt_distillation.py をそのまま Pipeline Parallelism 適用しようとしても、生徒モデルのデータしか送受信してくれず、蒸留を並列化できませんでした。
2025 年 4 月末時點の NeMo 2.0 での実裝と課題
その後、2025 年 2 月より NeMo は蒸留プロセスの Pipeline Parallelism に対応しました。これまでの megatron_gpt_distillation.py はそのまま維持され、NeMo LLM Collection 內に別途蒸留が実裝されています。NeMo LLM Collection は、NeMo 2.0 で再設計された學習/運用を簡単かつ柔軟に行えるインターフェイスです。
蒸留の実裝では、上記 Pipeline Parallelism の送受信の仕様を引き継ぎ、教師モデルと生徒モデルを別々に並列化して実行する実裝になっています。具體的には nemo/lightning/megatron_parallel.py 內で、以下のように教師モデルと生徒モデルを交互に動かすようになっています。すると、teacher_step の中で教師モデルを一通り処理してから、続いて student_step の中で生徒モデルの処理を行うことになります。teacher_step、student_step では、先ほど図示した Pipeline Parallelism の一連の処理が行われるもので、図 4 のようにそれぞれの內部で global batch size の回數 forward/backward が行われます。図のケースでは global batch size を 4 としています。
with self.unwrapped_model.only_teacher_forward(): with self.unwrapped_model.swap_teacher_config(self.module): teacher_step()with self.unwrapped_model.only_student_forward(): microbatch_outputs = student_step() |

ここで、modelopt の実裝の中身を見ていきましょう。教師モデルを forward すると、以下のような hook の仕組みを利用して output_capture_fwd_hook 関數の中で所定の中間レイヤーの結果をキャッシュします (先程の図における O1 ? O4)。キャッシュした中間レイヤーの結果を loss を計算する際に pop し、対応する生徒モデルの結果と比較します。ところが、global batch 分の中間結果を teacher_layer._intermediate_output に全てキャッシュする必要があるため、global batch size が大きいと OOM になりやすくなります。
for student_layer, teacher_layer in self._layers_to_loss: (省略) teacher_layer.register_forward_hook(output_capture_fwd_hook)def output_capture_fwd_hook(module: nn.Module, input: Any, output: Any): # pylint: disable=redefined-builtin # noqa (省略) # Teacher if len(module._intermediate_output) > 0: warnings.warn( f"Teacher's Module `{type(module).__name__}` already has an intermediate output stored." " This is undesired behavior unless Pipeline Parallelism is in use." ) module._intermediate_output.append(output) (省略)def compute_kd_loss( self, student_loss: Optional[torch.Tensor] = None, loss_reduction_fn: Callable = None, skip_balancer: bool = False,) -> Union[torch.Tensor, dict[str, torch.Tensor]]: (省略) for (student_layer, teacher_layer), loss_fn in self._layers_to_loss.items(): out_s = student_layer._intermediate_output out_t = teacher_layer._intermediate_output.pop(0) # can store multiple in special cases student_layer._intermediate_output = None loss = loss_fn(out_s, out_t) # Student is pred, Teacher is target (省略) |
理想的には教師モデルの結果をキャッシュせずに、教師モデルと生徒モデルを microbach 単位で交互に動かしたいのですが、Megatron-Core ではステージ間でのデータの送受信の形がレイヤーの出力の shape に固定されており、教師と生徒の両方の出力を同時に送受信することが難しいです。そのため、NeMo の実裝では教師と生徒をそれぞれ global batch の単位で動かしていました。結果的に (global batch x seq_len x hidden_dim) のメモリが必要になっていました。
ABEJA での実裝方法
ABEJA ではこの解決のため、megatron/core/pipeline_parallel/schedules.py にある Megatron-Core の並列の実裝を作り直し、蒸留のプロセスに合わせて修正しました。具體的には図 5 の処理になるように並列処理のロジックを書き直しました。micro bach 毎に (1) 教師モデルの forward、(2) 生徒モデルの forward、(3) ロスの計算、(4) 生徒モデルの backward という順番で処理を行うようにし、先程の中間結果のキャッシュを不要にしてメモリを節約することとしました。これにより、(micro batch x seq_len x hidden_dim) までメモリ消費に抑えることに成功しました。
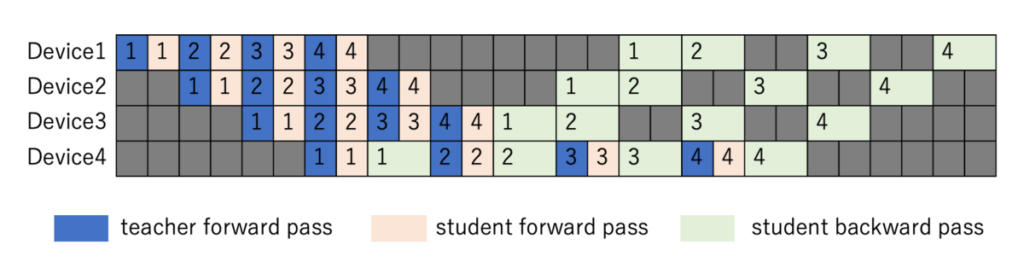
本実裝では、microbatch 毎に、教師モデルの forward を行い、その後すぐに生徒モデルの forward を行います。教師モデルは backward は不要なため、最後のステージでは生徒モデルのみ backward を行い、前のステージに結果を送ります。backward のフェーズでは生徒モデルのみ、後ろのステージからデータを受け取り、そのデータを用いて backward を行い、その結果を更に前のステージに送ります。例えば、forward の処理の一部は以下のようになります。送信と受信の順番がズレるとハングするため丁寧に作る必要がありますが、並列プログラミングはデバッグしづらいので中々大変ですね。なお、実際の処理の中では validation の処理は forward のみであったり、またステージ毎に処理を分けていたりと、非常に長くなってしまうので、ここでは簡易的なコードのみ示します。以下のように、ステージの中で microbatch 毎に教師モデルの処理と生徒モデルの処理をそれぞれ交互に行うこととしています。
# (1) 前のステージのデータを受け取りteacher_input_tensor = recv_forward(teacher_recv_tensor_shapes, teacher_config)input_tensor = recv_forward(recv_tensor_shapes, config)for i in range(num_microbatches): # (2) それぞれのモデルのforwardを行う teacher_output_tensor, _ = forward_step(teacher_forward_step_func, teacher_data_iterator, teacher_model, ...) output_tensor, num_tokens = forward_step(forward_step_func, data_iterator, model,. ..) # (3) 次のステージに結果を送りつつ、studentは後段処理の結果を待つ send_forward(teacher_output_tensor, teacher_send_tensor_shapes, teacher_config) output_tensor_grad = send_forward_recv_backward( output_tensor, send_tensor_shapes, config ) # (4) studentのbackwardを行う input_tensor_grad = backward_step( input_tensor, output_tensor, output_tensor_grad, model_type, config ) # (1-2) 前のステージのデータを受け取る teacher_input_tensor = recv_forward(teacher_recv_tensor_shapes, teacher_config) # (2-2) 前のステージにbackward結果を送りつつ、前のステージから次のデータを受け取る input_tensor = send_backward_recv_forward( input_tensor_grad, recv_tensor_shapes, config ) |
実験
実験では、NVIDIA V100 の GPU 2 基を搭載した計算環境で、Qwen2.5-1.5B-Instruct を教師モデル、Qwen2.5-0.5B-Instruct を生徒モデルとして、global batch size を変えながら、どこで OOM が出るかをチェックしました。なお、メモリに関連するパラメーターとしては、sequence length は1024、micro batch size は 1 で固定しました。ちなみに、詳細なメモリの使用量で見たかったのですが、內部で push/pop を繰り返しているからか、nvidia-smi でのメモリの使用量は変わらなかったので、ここでは OOM が出るかどうかのチェックに留めました。実験の結果、元のコードでは global batch size が 64 以上で OOM が出てしまったのに対し、ABEJA の実裝では global batch size が 1024 でも動作することを確認しました。global batch size を増やすことで、小さい場合よりも安定した學習が期待できます。本実裝を用いて、先のブログの実験結果を出すことができました。
| モデル | 8 | 16 | 32 | 48 | 64 | 128 | 256 | 512 | 1024 |
| NeMo (2025 年 4 月末時點) | ? | ? | ? | ? | ? | ? | ? | ? | ? |
| ABEJA | ? | ? | ? | ? | ? | ? | ? | ? | ? |
追記
本記事を書き終えて NeMo のソース コードを改めて見ていたら、なんと 2025 年 5 月 10 日に NeMo の蒸留の実裝のアップデート (PR#13065) が行われました。Megatron-Core の Pipeline Parallelism の実裝に、adjust_tensor_shapes_fn という仕組みを導入し、これまでは各ステージのネットワークの出力サイズに固定されていた送受信の shape を外部から変えられるようにしたようです。これにより、nemo/collections/llm/modelopt/distill/utils.py で教師モデルと生徒モデルの両方を送受信するように定義することで、教師と生徒を同時に処理できるようになったようです。
まとめ
本実験では、NeMo の 蒸留における Pipeline Parallelism の実裝において、ABEJAで取った実裝方法によって、メモリの使用量を抑えることができることを確認しました。
なお、本成果は、経済産業省と NEDO が実施する GENIAC でのモデル開発によって得られたものです。
関連情報
- ABEJA Tech Blog: 小型 LLM「ABEJA Qwen2.5-7B Model」學習のための蒸留のパイプライン並列化
- ABEJA Tech Blog: ABEJA Qwen2.5 32B-Japanese より更に軽量な ABEJA Qwen2.5 7B-Japanese v0.1 の公開
- ABEJA Tech Blog: 50B 以下で高性能な ABEJA Qwen2.5 32B-Japanese v0.1 の公開
- ABEJA Tech Blog: Reasoning 能力を付與した LLM ABEJA-QwQ32b-Reasoning-Japanese-v1.0 の公開
- GitHub: NeMo
- NVIDIA User Guide: NeMo Framework