NVIDIA cuDNN
The NVIDIA CUDA? Deep Neural Network library (cuDNN) is a GPU-accelerated library of primitives for deep neural networks. cuDNN provides highly tuned implementations for standard routines such as forward and backward convolution, attention, matmul, pooling, and normalization.
Key Features
Accelerated Learning
cuDNN provides kernels, targeting Tensor Cores, to deliver best available performance on compute-bound operations. It offers heuristics for choosing the right kernel for a given problem size.
Expressive Op Graph API
The user defines computations as a graph of operations on tensors. The cuDNN library has both a direct C API and an open-source C++ frontend for convenience. Most users choose the frontend as their entry point to cuDNN.
Fusion Support
cuDNN supports fusion of compute-bound and memory-bound operations. Common generic fusion patterns are typically implemented by runtime kernel generation. Specialized fusion patterns are optimized with pre-written kernels.
Deep Neural Networks
Deep learning neural networks span computer vision, conversational AI, and recommendation systems, and have led to breakthroughs like autonomous vehicles and intelligent voice assistants. NVIDIA's GPU-accelerated deep learning frameworks speed up training time for these technologies, reducing multi-day sessions to just a few hours. cuDNN supplies foundational libraries needed for high-performance, low-latency inference for deep neural networks in the cloud, on embedded devices, and in self-driving cars.
Features
- Accelerated compute-bound operations like convolution and matmul
- Optimized memory-bound operations like pooling, softmax, normalization, activation, pointwise, and tensor transformation
- Fusions of compute-bound and memory-bound operations
- Runtime fusion engine to generate kernels at runtime for common fusion patterns
- Optimizations for important specialized patterns like fused attention
- Heuristics to choose the right implementation for a given problem size
cuDNN Graph API and Fusion
The cuDNN Graph API is designed to express common computation patterns in deep learning. A cuDNN graph represents operations as nodes and tensors as edges, similar to a dataflow graph in a typical deep learning framework. Access to the cuDNN Graph API is conveniently available through the C++ Frontend API (recommended) as well as the lower-level C Backend API (for special cases where C++ isn’t appropriate).
- Flexible fusions of memory-limited operations into the input and output of matmul and convolution
- Specialized fusions for patterns like attention and convolution with normalization
- Support for both forward and backward propagation
- Heuristics for predicting the best implementation for a given problem size
- Open source C++ Frontend API
- Serialization and deserialization support
Below are examples of operation graphs described by the cuDNN Graph API.

ConvolutionFwd followed by a DAG with two operations
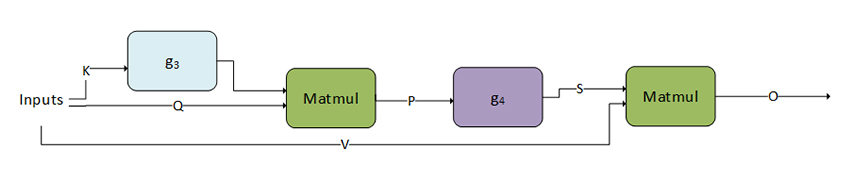
Mha-fprop cuDNN Operation Graph
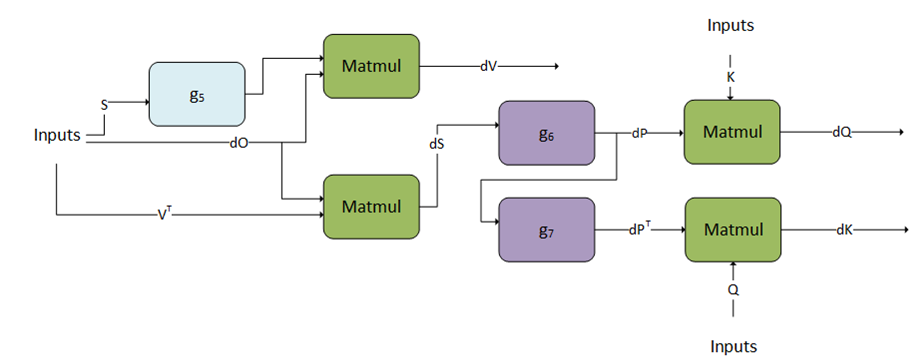
Mha-bprop cuDNN Operation Graph
cuDNN Accelerated Frameworks
cuDNN accelerates widely used deep learning frameworks, including Caffe2, Chainer, Keras, MATLAB, MxNet, PaddlePaddle, PyTorch, and TensorFlow.
Related Libraries and Software
NVIDIA NeMo?
NeMo is an end-to-end cloud-native framework for developers to build, customize, and deploy generative AI models with billions of parameters.
Learn MoreNVIDIA TensorRT?
TensorRT is a software development kit for high-performance deep learning inference.
Learn MoreNVIDIA Optimized Frameworks
Deep learning frameworks offer building blocks for designing, training, and validating deep neural networks through a high-level programming interface.
NVIDIA Collective Communication Library
NCCL is a communication library for high-bandwidth, low-latency, GPU-accelerated networking
Learn More