Robots must perceive and interpret their 3D environments to act safely and effectively. This is especially critical for tasks such as autonomous navigation, object manipulation, and teleoperation in unstructured or unfamiliar spaces. Advances in robotic perception increasingly focus on integrating 3D scene understanding, generalizable object tracking, and persistent spatial memory—using robust perception modules in unified, real-time workflows.
This edition of NVIDIA Robotics Research and Development Digest (R2D2) explores several perception models and systems from NVIDIA Research that support a unified 3D perception stack for robotics. They enable reliable depth estimation, camera and object pose tracking, and 3D reconstruction in diverse real-world settings:
- FoundationStereo (Best Paper Nomination at CVPR 2025): A foundation model for stereo depth estimation that generalizes across diverse environments, including indoor, outdoor, synthetic, and real-world scenes, with zero-shot performance.
- PyCuVSLAM: Python Wrapper for cuVSLAM, enabling Python users to implement NVIDIA’s CUDA-accelerated SLAM library for real-time camera pose estimation and environment mapping.
- BundleSDF: A neural system for 6-DoF object pose tracking and dense 3D reconstruction from RGB-D video.
- FoundationPose: A generalizable 6D object pose estimator and tracker for novel objects with minimal prior information.
- nvblox Pytorch Wrapper: Pytorch wrapper for the nvblox library, a CUDA-accelerated library for 3D reconstruction from depth cameras for PyTorch.
3D spatial representations: the backbone of robot perception
At the core of these projects lies an emphasis on 3D spatial representations—capturing the structure of the environment or objects in a form the robot can use. FoundationStereo tackles the fundamental task of depth estimation from stereo images. It introduces a foundation model for stereo depth designed for strong zero-shot generalization.

FoundationStereo has been trained on over 1 million synthetic stereo pairs. It can infer accurate disparity (and thus 3D structure) across diverse environments—including indoor, outdoor, synthetic, and real-world scenes (such in Figure 1)—without scene-specific tuning. The output consists of dense depth maps or point clouds that represent the 3D structure of the scene.
On the environment mapping side, libraries like nvblox and cuVSLAM build spatial representations over time. NVIDIA’s nvblox is a GPU-accelerated 3D reconstruction library that rebuilds voxel grids and outputs Euclidean signed distance field (ESDF) heatmaps for navigation. This enables vision-only 3D obstacle avoidance for mobile robots, providing a cost-effective alternative to expensive 3D lidar sensors.?
While nvblox excels at geometric mapping, it has lacked semantic understanding of the environment. With nvblox_torch, we introduce a PyTorch Wrapper that can lift a 2D VLM foundation model’s semantic embedding to 3D.
Similarly, cuVSLAM offers GPU-accelerated visual-inertial SLAM for robotics through Isaac ROS. cuVSLAM, previously limited to ROS users, is now accessible through a new Python API called PyCuVSLAM. It simplifies integration for data engineers and deep learning researchers.
Depth and mapping modules create a geometric scaffold—whether point clouds, signed distance fields, or feature grids—upon which higher-level perception and planning are built. Without reliable 3D representations, a robot cannot accurately sense, remember, or reason about its world.
Real-time SLAM and camera-pose estimation for scene understanding
A key aspect tying these projects together is real-time scene understanding through SLAM (Simultaneous Localization and Mapping). cuVSLAM is a highly efficient, CUDA-accelerated SLAM system for stereo visual-inertial SLAM that runs on a robot’s onboard GPU.

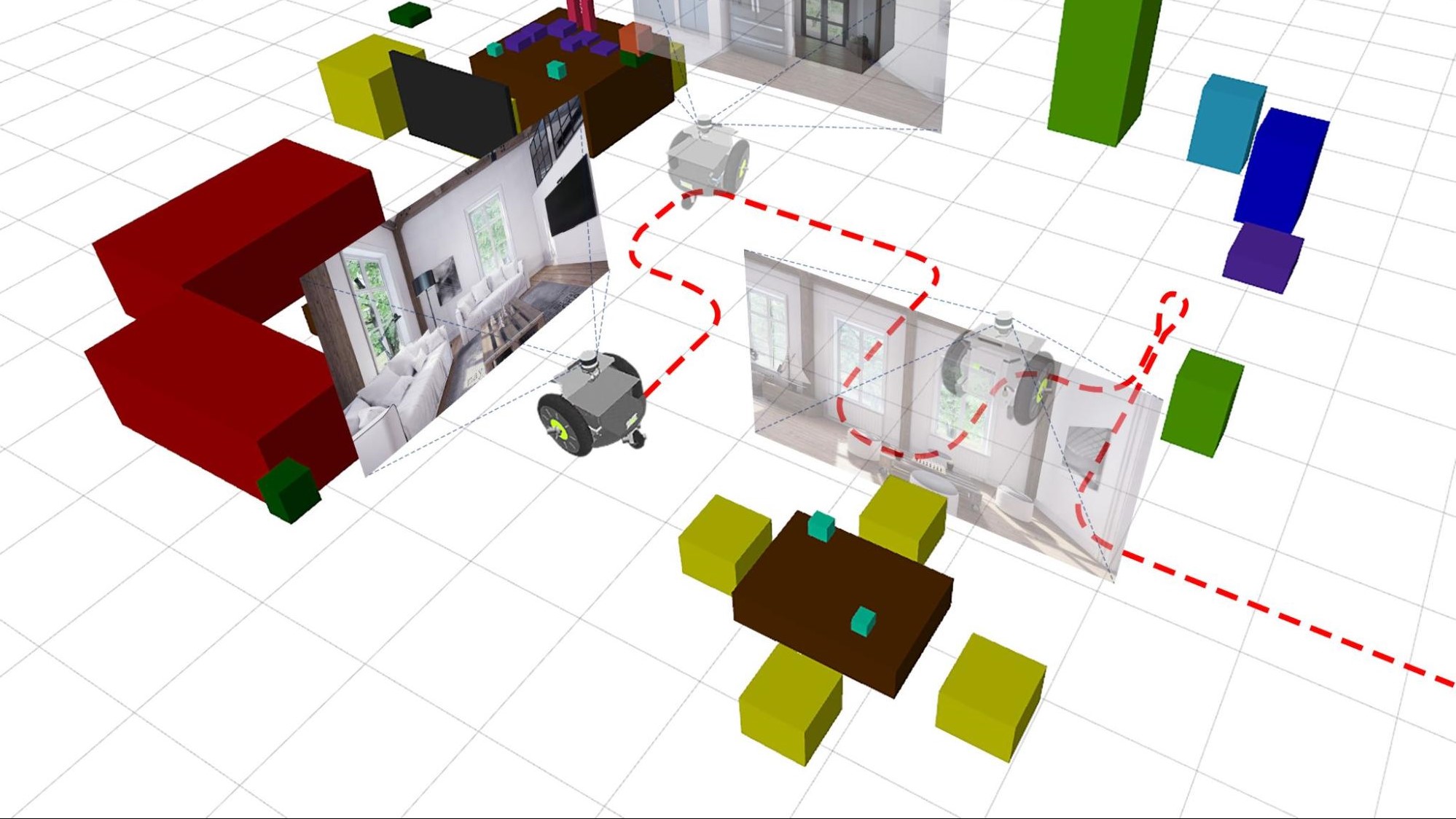
Leveraging robust and efficient Visual SLAM systems remains a daunting task for developers who prefer the simplicity and versatility of Python. With PyCuVSLAM, developers can easily prototype and utilize cuVSLAM for applications such as generating robot training datasets from internet-scale videos. The API can estimate the pose and trajectory of an ego camera from first-person view videos, enhancing end-to-end decision-making models. Additionally, integrating cuVSLAM into training pipelines like MobilityGen can create more robust models by learning real-world SLAM system errors. Example capabilities are shown in Figure 2.
Real-time 3D mapping

Nvblox_torch is an easy-to-use python interface to the nvblox CUDA-accelerated reconstruction library that allows developers to easily prototype 3D mapping systems for manipulation and navigation applications.
Spatial memory is a core capability for robots to complete longer-horizon tasks. Robots are frequently required to reason about the geometric and semantic content of a scene, where the scene often has a spatial extent larger than can be captured in a single camera image. A 3D map aggregates geometric and semantic information across multiple views into a unified representation of the scene. Leveraging these properties of 3D maps can provide spatial memory and support spatial reasoning in the context of robot learning.
Nvblox_torch is a CUDA-accelerated Pytorch toolbox for robotic mapping with RGB-D cameras. The system allows users to combine observations of the environment into 3D representations of the scene on an NVIDIA GPU. This 3D representation can then be queried for quantities like obstacle-distance, surface meshes, and occupancy probability (see Figure 3). nvblox_torch uses zero-copy input/output interfaces from PyTorch tensors to provide blazingly fast performance.
Furthermore, nvblox_torch adds a new capability: deep feature fusion. This feature allows users to fuse image features from vision foundation models into the 3D reconstruction. The resulting reconstruction then represents both the geometric and the semantic content of the scene. Foundation model features in 3D are emerging as a popular representation for semantics-based navigation and language-guided manipulation. This representation is now available within the nvblox_torch library.
6-DoF object pose tracking and 3D reconstruction of novel objects
Equally important is the object-centric half of perception: understanding what objects are in the scene, where they are, and how they move. Two projects, FoundationPose and BundleSDF, address the challenge of 6-DoF object pose estimation and tracking, even for objects the robot has never seen before.
FoundationPose represents a learning-based approach: It’s a unified foundation model for 6D object pose estimation and tracking that works in both model-based and model-free scenarios. This means the same system can handle known objects (if a CAD model is available) or completely novel objects (using just a few reference images) without retraining, as shown in Video 1, where a manipulator grabs an object. FoundationPose achieves this by leveraging a neural implicit representation to synthesize novel views of the object, effectively bridging the gap between having a full 3D model and having only sparse observations.
Trained on large-scale synthetic data (with the help of techniques like an LLM-based data generation pipeline), it generalizes robustly; in fact, it can be applied to a new object at test time instantly, as long as minimal information (model or images) is provided. This foundation model approach yields state-of-the-art accuracy on pose benchmarks, outperforming specialized methods while maintaining zero-shot capability on novel objects.

BundleSDF takes an online, optimization-driven approach to the problem, offering a near real-time (≈10 Hz) method for simultaneous 6-DoF pose tracking and neural 3D reconstruction from an RGB-D video. It assumes only segmentation in the first frame; no prior CAD model or category knowledge is needed afterward.
Key to BundleSDF is a concurrently learned Neural Object Field, a neural implicit SDF that captures the object’s geometry and appearance as it is observed. As the object moves, BundleSDF continuously optimizes a pose graph using past frames, refining the pose trajectory and shape estimate over time. This integration of pose estimation with shape learning effectively addresses challenges like large pose changes, occlusions, low-texture surfaces, and specular reflections. By the end of an interaction, the robot has a consistent 3D model and tracked pose sequence that it obtained on the fly.
The framework overview is shown in Figure 5 (below). First, features are matched between consecutive images to obtain a coarse pose estimate (Sec. 3.1). Some posed frames are stored in a memory pool for later refinement (Sec. 3.2). A pose graph is dynamically created from a subset of the pool (Sec. 3.3), and online optimization refines all poses in the graph along with the current pose. Updated poses are stored back in the pool. Finally, all posed frames in the pool learn a Neural Object Field (in a separate thread) that models geometry and visual texture (Sec. 3.4), while adjusting previously estimated poses.

Both FoundationPose and BundleSDF highlight the importance of object-level 3D understanding in robotics. A robot that can pick up or manipulate arbitrary objects must be able to perceive an object’s 3D position and orientation (pose) and often its shape. These projects show two complementary routes: pre-trained foundation models that generalize to new objects by learning broad priors, and on-line neural SLAM for objects that build a custom model as it goes. In practice, these capabilities might even work together—e.g., a foundation model could provide an initial guess that is refined by on-line reconstruction. The unifying theme is that robots are moving toward real-time 6D perception of novel objects, rather than being limited to recognizing a fixed set of known items.
Foundation models: generalization and unification across tasks
More robotics perception systems leverage foundation models—large neural networks that generalize across tasks with minimal tuning. This is evident in FoundationStereo and FoundationPose, which offer strong baselines for stereo depth estimation and 6D object pose tracking, respectively.
FoundationStereo incorporates a side-tuned monocular depth prior from DepthAnythingV2 into a stereo model framework, enhancing robustness and domain generalization without retraining. It is trained on over 1 million synthetic stereo pairs across various environments, achieving state-of-the-art, zero-shot performance on benchmarks like Middlebury, KITTI, and ETH3D datasets. The model improves both the cost volume encoder and decoder, enhancing long-range disparity estimation.
In Figure 6 (below), the Side-Tuning Adapter (STA) utilizes rich monocular priors from a frozen DepthAnythingV2, along with detailed high-frequency features from a multi-level CNN for extracting unary features. Attentive Hybrid Cost Filtering (AHCF) combines Axial-Planar Convolution (APC) filtering with a Disparity Transformer (DT) module, effectively aggregating features across spatial and disparity dimensions in the 4D hybrid cost volume. An initial disparity is predicted from this filtered cost volume and refined using GRU blocks. Each refinement stage uses the updated disparity to look up features from the filtered hybrid cost volume and the correlation volume, guiding the next refinement step and resulting in the final output disparity.

FoundationPose is a unified model for single-frame 6D pose estimation and multi-frame pose tracking of novel objects. It supports model-based and image-based inference by learning a neural implicit representation of object geometry. It generalizes to unseen objects using a CAD model or a few RGB references. Trained on a massive synthetic dataset generated with large language models, it includes diverse task prompts and scene variants.
FoundationPose utilizes contrastive training and a transformer-based encoder, significantly outperforming task-specific baselines like CosyPose and StablePose across benchmarks such as YCB-Video, T-LESS and LM-OCC. Figure 7 illustrates how FoundationPose works. To reduce manual efforts for large-scale training, we created a synthetic data generation pipeline using emerging techniques and resources, including a 3D model database, LLMs, and diffusion models (Sec. 3.1). To connect model-free and model-based setups, we use an object-centric neural field (Sec. 3.2) for novel view RGB-D rendering and render-and-compare. For pose estimation, we initialize global poses uniformly around the object, refined by the refinement network (Sec. 3.3). Finally, we send the refined poses to the pose selection module to predict their scores, selecting the pose with the best score as output (Sec. 3.4).

Together, these models represent a step toward unified and reusable perception backbones in robotics. By embedding general-purpose priors about depth and object geometry into real-time systems, they enable reliable performance in zero-shot scenarios, where robots must operate in environments or with objects not seen during training. As robotics moves toward more adaptable and open-world deployment, foundation models offer the flexibility and scalability needed to support a broad range of tasks within a common perception framework.
Toward an integrated 3D perception stack
Together, these projects point toward a unified 3D perception stack where depth estimation, SLAM, object tracking, and reconstruction operate as tightly integrated components. FoundationStereo delivers robust depth; cuVSLAM tracks camera pose for real-time localization and mapping; and BundleSDF and FoundationPose handle object-level understanding, including 6-DoF tracking and shape estimation, even for unseen objects.
By building on foundation models and neural 3D representations, these systems enable generalizable, real-time perception that supports navigation, manipulation, and interaction in complex environments. The future of robotics lies in such integrated stacks, where perception modules share representations and context that allow robots to perceive, remember, and act with spatial and semantic awareness.
Summary
This edition of R2D2 explored how recent advances in stereo depth estimation, SLAM, object pose tracking, and 3D reconstruction are converging into a unified 3D perception stack for robotics. These tools, many of which are powered by foundation models, enable robots to understand and interact with their environment in real time, even when faced with novel objects or unfamiliar scenes.
Check out the following resources to learn more:
- FoundationStereo (CVPR 2025 – Best Paper Nomination) – Website, paper, code, and dataset.
- FoundationPose (CVPR 2024 Highlight) – Website, paper, code, NGC, Isaac ROS FoundationPose
- BundleSDF (CVPR 2023) – Website, paper, code
- PyCuVSLAM – Paper, code
- nvblox_torch – Website, paper, code
Coming soon:
- FoundationStereo commercial version.
Explore all the NVIDIA research papers showcased at CVPR 2025 and see the research in action.
This post is part of our NVIDIA Robotics Research and Development Digest (R2D2) to give developers deeper insight into the latest breakthroughs from NVIDIA Research across physical AI and robotics applications.
Stay up to date by subscribing to the newsletter and following NVIDIA Robotics on YouTube, Discord, and developer forums. To start your robotics journey, enroll in free NVIDIA Robotics Fundamentals courses.
Acknowledgments
For their contributions to the research mentioned in this post, thanks to Joseph Aribido, Stan Birchfield, Valts Blukis, Alex Evans, Dieter Fox, Orazio Gallo, Jan Kautz, Alexander Millane, Thomas Müller, Jonathan Tremblay, Matthew Trepte, Stephen Tyree, Bowen Wen, and Wei Yang.