
The world of big data analytics is constantly seeking ways to accelerate processing and reduce infrastructure costs. Apache Spark has become a leading platform for scale-out analytics, handling massive datasets for ETL, machine learning, and deep learning workloads. While traditionally CPU-based, the advent of GPU acceleration offers a compelling promise: significant speedups for data processing tasks.
However, migrating Spark workloads from CPUs to GPUs isn’t a straightforward endeavor.?GPU acceleration, while powerful for certain operations, doesn’t necessarily improve performance in every scenario. Factors like small datasets, large amounts of data movement, and using user-defined functions (UDFs) can sometimes negatively impact GPU performance. Conversely, workloads involving high-cardinality data, such as joins, aggregates, sort, window operations, and transcoding tasks (like encoding/compressing Apache Parquet or Apache ORC or parsing CSV) are typically positive indicators for GPU acceleration.
This presents a crucial problem for organizations looking to leverage GPUs: How do you know if your specific Spark workload would truly benefit from GPU acceleration before investing time and resources in migration??The specific environment that a Spark workload is running in on CPU vs. GPU can vary greatly. In addition, the network setup, disk bandwidth, and even the GPU type can play a factor in performance on GPU, and these variables can be hard to capture from Spark logs.??
The Qualification Tool
The proposed solution to this problem is the Spark RAPIDS Qualification Tool. This tool is designed to analyze your existing CPU-based Spark applications and predict which ones are good candidates for migration to a GPU cluster. It aims to project the performance of the Spark application on GPUs with a machine learning estimation model trained on industry benchmarks and historical results from many real-world examples. The tool is available as a command-line interface via a pip package and can be used in various environments, including cloud service providers (CSPs) like AWS EMR, Google Dataproc, Databricks (AWS/Azure), as well as on-premise environments.?There are quick-start notebooks available specifically for the AWS EMR and Databricks environments.
The tool works by taking the Spark event logs generated from your CPU-based Spark applications as its primary input. These event logs contain valuable information about the application, its executors, and the expressions used, along with relevant operating metrics. The tool supports event logs from both Spark 2.x and Spark 3.x jobs.

As output, the qualification tool provides several key pieces of information to aid in the migration process:
- A qualified workload list indicating which applications are candidates for GPU migration.
- Recommended Spark configurations for GPU, which are calculated based on cluster information (like memory and cores) and data from the Spark event logs that could impact the performance of Spark applications on GPU.
- For CSP environments — a recommended GPU cluster shape, including instance type and count, along with GPU information.
The output provides a starting point, but it’s important to note that the tool does not guarantee that the recommended applications will be accelerated the most. The tool is a predictive estimate and we will explain more the methodology in the next section.?The tool reports its findings by examining the amount of time spent on tasks of SQL Dataframe operations.
You can run the tool from the command line using a CLI command: spark_rapids qualification --eventlogs <file-path> --platform <platform>.
How Qualification Works
So how does the tool work internally to provide these predictions and recommendations? The core of the qualification tool lies in its ability to analyze the input event logs and extract various metrics, which are then used as features. The tool parses the raw event log and generates intermediate CSV files containing raw features for each SQL execution ID (sqlID). These features are derived from information within the event logs, such as disk bytes spilled, maximum heap memory used, estimated scan bandwidth, details about individual operators in the query plan, and data size.
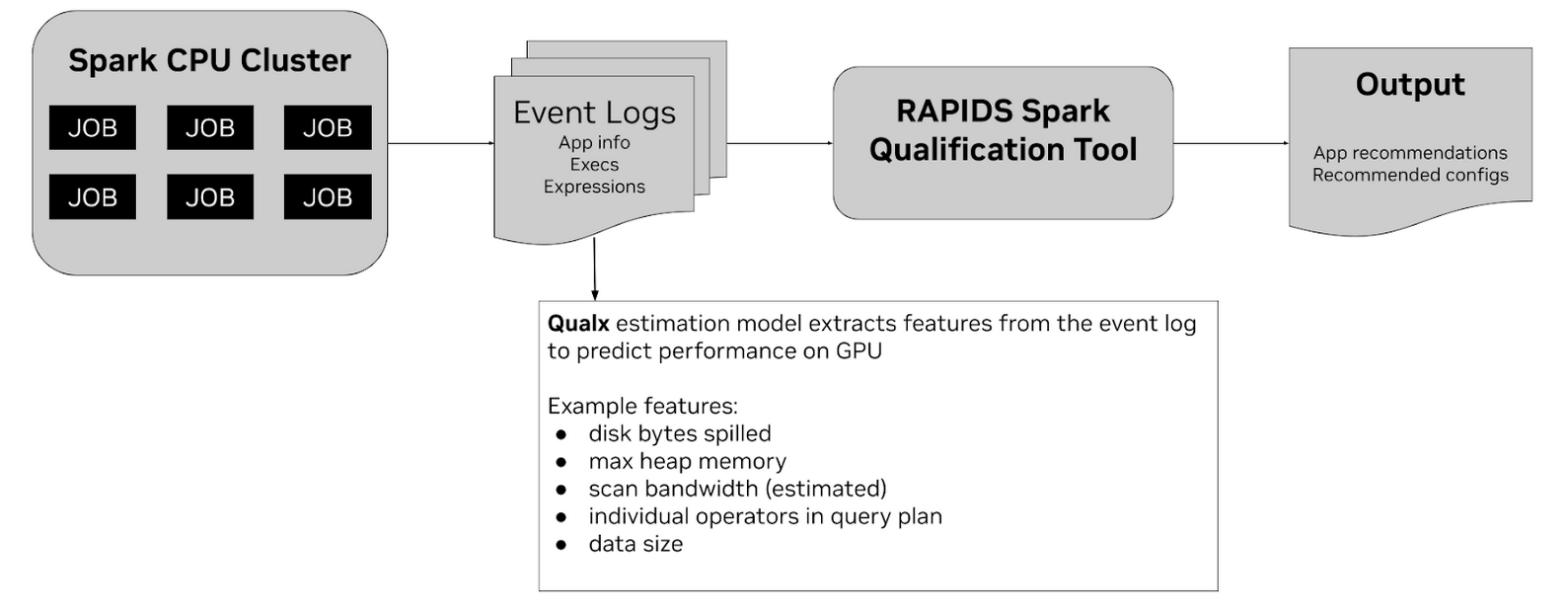
These extracted features serve as input for a Machine Learning estimation model.? This model has been trained on historical data from matching CPU and GPU runs of various Spark applications. By leveraging this training data, the model learns to predict the speedup an application might achieve when run on a GPU.? The tool uses data from these historical benchmarks to estimate speed-up at the individual operator level. This estimation is then combined with other relevant heuristics to determine the overall qualification of a workload for GPU migration.?The tool ships with pre-trained estimation models tailored for various environments, primarily trained on NDS benchmark workloads.
Building A Custom Qualification Model
While the pre-trained models work well for many scenarios, you might encounter situations where the out-of-the-box predictions aren’t accurate for your specific needs. This is particularly true if your workloads don’t resemble the NDS benchmarks the models were primarily trained on, if your Spark environment (hardware, network, etc.) is significantly different from the pre-trained environments, or if you have already benchmarked numerous workloads on both CPU and GPU in your environment and observe discrepancies with the predictions.
In these cases, the Spark RAPIDS Qualification Tool offers the capability to build a custom qualification estimation model. This allows you to train an estimation model specifically on your own data and environment, potentially leading to more accurate predictions.

Run CPU and GPU Workloads and Collect Event Logs
To train a model that accurately predicts GPU performance in your environment, you need training data that includes both CPU and GPU runs for the same workloads. The process involves running the target Spark applications on both CPU and GPU clusters and collecting the resulting Spark event logs. It’s crucial to collect CPU and GPU event log pairs for each workload. CPU event logs are used to derive the features for the model, while GPU event logs are used to compute the actual speedup achieved, which serves as the label for training.
Preprocess the Event Logs
Before training, the collected event logs need to be processed to extract the features required by the model. The preprocessing step uses the Profiler tool to parse the raw event logs and generate CSV files containing “raw features” per sqlID. This process can take some time depending on the volume and size of the event logs. To optimize subsequent runs, the $QUALX_CACHE_DIR environment variable can be set to cache these intermediate Profiler CSV files. The preprocessing step can be executed using the CLI command qualx preprocess --dataset datasets.
Train the XGBoost Model
Once the features are extracted through preprocessing, you can train your custom XGBoost model. The training process can be initiated using the spark_rapids train CLI command. You need to provide the path to the directory containing your dataset JSON files, the path where you want to save the trained model, and an output folder for the generated CSV files. For example, you might run spark_rapids train --dataset datasets --model custom_onprem.json --output_folder train_output. The training process utilizes machine learning and leverages Optuna for hyper-parameter optimization. You can also configure the number of trials for hyperparameter search. The model is trained at the SQL execution ID level (sqlID). As a rule of thumb, around 100 sqlIDs are recommended for an “initial” model, and around 1000 sqlIDs for a “good” model.
Evaluate Feature Importance and Model Performance
After training, it’s beneficial to evaluate the importance of the features used by the model. While the estimation model has built-in feature importance metrics (gain, cover, frequency), there is also available Shapley (SHAP) values, which provide a game-theoretic allocation of importance and are additive, summing to the final prediction. Typical important features include durations, compute, and network I/O.
You also can evaluate the performance of your trained model by comparing the predicted speedups against the actual observed speedups from your training data. An ideal prediction would fall on the identity line (predicted speedup equals actual speedup). You can choose an evaluation metric suitable for your use case, such as Mean Absolute Percentage Error (MAPE), precision, or recall.

Use the Custom Model for Prediction
Once you’re satisfied with the performance of your custom-trained model, you can use it with the qualification tool for predicting speedups on new, unseen Spark applications. When running the spark_rapids prediction command, simply supply the path to your trained model file (e.g., custom_onprem.json) using the --custom_model_file argument. The tool will then use your custom model instead of the default pre-trained model to analyze the event logs and provide speedup predictions and recommendations. The output will include per-application, and per-sql speedup predictions, feature values used for prediction, and feature importance values.
Building a custom qualification model empowers you to tailor the prediction process to your specific environment and workloads, increasing the accuracy of the recommendations and ultimately helping you more effectively leverage GPUs for your Spark applications.
Getting started with Apache Spark on GPUs
Enterprises can take advantage of the RAPIDS Accelerator for Apache Spark to seamlessly migrate Apache Spark workloads to NVIDIA GPUs. RAPIDS Accelerator for Apache Spark leverages GPUs to accelerate processing by combining the power of the RAPIDS cuDF library and the scale of the Spark distributed computing framework. Run existing Apache Spark applications on GPUs with no code changes by launching Spark with the RAPIDS Accelerator for the Apache Spark plugin JAR file.
The qualification tool is also part of Project Aether which is a collection of tools and processes that automatically qualify, test, configure and optimize Spark workloads for GPU acceleration at scale. Organizations who are interested in using Project Aether to assist with their Spark migrations can apply to be considered for this free service.
For additional information about the qualification tool, please check out the Spark RAPIDS user guide For a more detailed technical view of this topic, you can watch the GTC 2025 on-demand session focused on Spark RAPIDS tools.











