The launch of the NVIDIA Blackwell platform ushered in a new era of improvements in generative AI technology. At its forefront is the newly launched GeForce RTX 50 series GPUs for PCs and workstations that boast fifth-generation Tensor Cores with 4-bit floating point compute (FP4)—a must-have for accelerating advanced generative AI models like FLUX from Black Forest Labs.
As the latest image generation models strive for speed, accuracy, higher resolutions, and complex prompt adherence, they’re getting increasingly larger and more complex. To deploy these large and complex models on local inference in PCs and workstations, it’s advantageous to go beyond 16-bit and 8-bit compute.
This is where Blackwell, in combination with the NVIDIA TensorRT software ecosystem of tools for inference shines, providing easy-to-use libraries that support FP4 quantization and deployment for inference, where performance and quality are great.
Getting there wasn’t easy. In order to leverage the 4-bit hardware innovation in Blackwell, this post deep dives into how we successfully quantized the FLUX model to FP4 weights using sophisticated PTQ and QAT techniques from the NVIDIA TensorRT Model Optimizer. We’ll also walk through how the quantized model was exported to ONNX and how the TensorRT Inference library handled the quantized operators so that an end-to-end inference journey could be exemplified into TensorRT DemoDiffusion. Lastly, we talk about how to try this feature locally on an RTX 50-series GPU using the popular GenAI Distro, ComfyUI.
Quantizing the model
In FLUX-1.Dev, the transformer backbone is our primary optimization target because it accounts for 98% of total inference latency on an NVIDIA GeForce RTX 5090 when running 28 inference steps. Reducing the transformer’s computational cost, therefore, promises substantial performance gains.
We quantized all transformer layers—except the final output and embedding layers using TensorRT-ModelOPT. Although FP4 post-training quantization initially led to minor image quality degradation (particularly in small text and figures) and slight metric drops (such as Image Reward and CLIP-IQA), we addressed these issues by fine-tuning the FP4-quantized model with a distillation-based QAT approach and synthetic data from FLUX-1.Dev. This fine-tuning step successfully restored image clarity and improved evaluation metrics.
Our distillation process used a BF16-precision model as the teacher and an FP4-quantized model as the student. This setup enabled the lower-precision student model to learn effectively from the higher-precision teacher, resulting in improved accuracy and visual quality.
Moreover, we applied SVDQuant—a state-of-the-art PTQ method—on top of FP4 quantization, which yielded a quality boost comparable to QAT, further closing the gap between the quantized and full-precision models.
Both QAT and SVDQuant deliver quantized models with accuracy essentially matching BF16, and both approaches are supported in ModelOPT v0.27. The choice between them depends on user requirements:
- QAT: Provides a straightforward deployment path with no additional runtime overhead, but it requires additional computational resources during training.
- SVDQuant: Eliminates the need for additional fine-tuning (training-free), but it increases deployment complexity and introduces some runtime overhead, slightly impacting inference performance.
Users can choose between QAT for maximum runtime efficiency at the expense of extra upfront training effort, or SVDQuant for quicker, training-free deployment at the cost of additional runtime processing. Quality comparison between them is captured in Figure 2.

| Model | Image Reward | CLIP-IQA | CLIP |
|---|---|---|---|
| BF16 | 1.118 | 0.926 | 30.150 |
| FP4 PTQ | 1.096 | 0.923 | 29.860 |
| FP4 QAT | 1.119 | 0.928 | 29.920 |
| FP4 SVDQ | 1.108 | 0.927 | 30.068 |
Exporting to ONNX
ONNX 1.18.0 (opset 23) is required for exporting FP4 models. This enables precise definition of input/output tensors of quantization nodes and offline-quantized weight tensors, ensuring smooth deployment. ModelOpt’s export process relies on a combination of standard ONNX DQ nodes and TensorRT custom operators to enable FP4 quantization while maintaining numerical stability through double quantization.
For static weight quantization, the BF16 model is initially exported with a custom ONNX operator (TRT_FP4QDQ), which encapsulates BF16 weights and block size attributes. A post-processing step replaces these custom nodes with a structured two-step dequantization (DQ) pattern.
The first DQ node extracts the BF16 blockwise scaling factors by dequantizing precomputed FP8 blockwise scale tensors. The second DQ node reconstructs BF16 dequantized weights from the compressed FP4 quantized weights and the BF16 blockwise scaling factors from the first DQ node. This double-quantization scheme ensures numerical stability, even with the limited dynamic range of FP8 (E4M3).
For dynamic input quantization, a TensorRT custom operator (TRT_FP4DynamicQuantize) captures BF16 inputs at runtime and computes both the FP4-quantized inputs and their FP8 blockwise scaling factors. These tensors, along with an FP32 scaling factor for the FP8 blockwise scales, pass through a similar two-step DQ pattern. The first DQ node reconstructs BF16 blockwise scaling factors, and the second DQ node dequantizes the inputs back to BF16. This method enables efficient fusion in TensorRT deployment of the quantized ONNX model while preserving precision, particularly for blockwise quantized models.
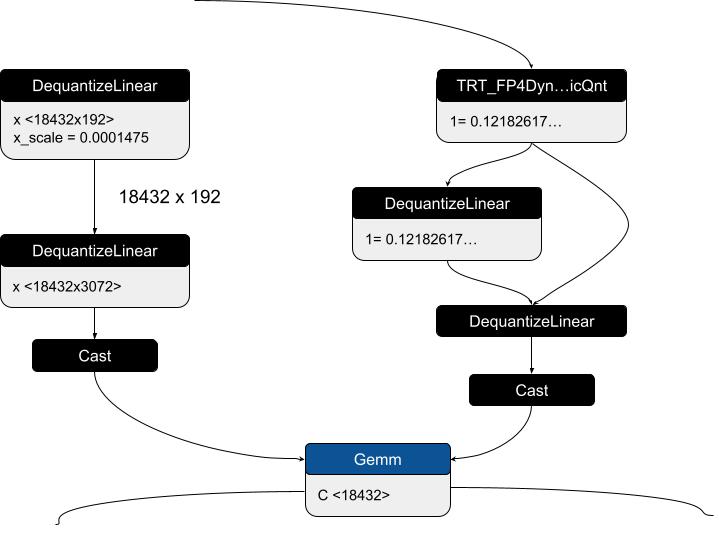
Figure 2. Weight quantization and dynamic input quantization sub-graphs
To validate the ONNX export and ensure numerical accuracy, we implemented an ONNX local function that simulates the behavior of TRT_FP4DynamicQuantize, enabling verification with ONNXRuntime. Initial testing used a BF16 global scale factor (GSF) for simplicity, but later, the local function was extended to support an FP32 GSF for improved stability and accuracy.
Additionally, since the quantized ONNX model contains real quantized weights instead of BF16 weights, it facilitates easier distribution and deployment across different platforms. The quantized torch checkpoint can also be loaded back for re-exporting to ONNX. The final ONNX model is then converted into a TensorRT engine for inference on the targeted GPU type.
This approach ensures efficient FP4 quantization while maintaining accuracy, optimizing memory usage, and simplifying model distribution for large-scale deployments. Review a sample FP4 ONNX Transformer model from Black Forest Labs.
Accelerated performance using FP4 from TRT 10.8
NVIDIA Blackwell GPU introduces hardware support for a new data type, FP4. With FP4, Blackwell can maximize performance while maintaining usable task accuracies. FP4 also provides superior inference accuracy over INT4.
Some benefits of FP4 include:
- 16x math throughput compared to FP32; 4x compared to FP8 at theoretical TOPs of RTX5090.
- Lower DRAM and L2 footprint.
- Lower DRAM to L2 to SM bandwidth consumption.
- Lower storage and transport requirements.
Using a GEMM operation as an example, the FP4 quantization is represented by a group of primitive ops as shown below. X/Y/W are the input tensor/output tensor/weight tensor of GEMM, and S is the scaling factor used by quantization ops.

In the FLUX pipeline, the transformer is accelerated by FP4 inference. All the fully connected (FC) layers, except for those at the beginning and end of the transformer, are running in FP4. In comparison to FP8, the FC layers can achieve up to 3.1x the performance of FP8. The multi-head attention (MHA) parts in the transformer are running in FP8.
In the FLUX transformer, there are also layers that are not quantized to a lower precision for better image quality, for example, the normalization layers. With the fine-grained hybrid precision solution in the transformer backbone, the final delivered performance on Geforce GPUs is shown below:
| Model | 5090 fp16* | 5090 fp8 | 5090 fp4 | 4090 fp8* |
| FLUX.1-dev (w/ 30 diffusion steps) | 10930.96ms | 6680.93ms | 3852.75ms | 10620.37ms |
| FLUX.1-schnell(w/ 4 diffusion steps) | 4427.43ms | 912.53ms | 590.56ms | 3385.43ms |
demoDiffusion samples for FLUX.1-Dev and Schnell
Black Forest Labs FLUX is a suite of image generation models. TensorRT demoDiffusion showcases how the suite of models can be accelerated. The pipeline runs its components sequentially using the TensorRT engines built for each model.
The input text prompt is first processed by the CLIP and T5 text encoders. The text embeddings generated by the text encoders are then used by the denoiser along with a pure noise vector in the latent space. The denoiser, a diffusion transformer, iteratively denoises the noise vector based on ?information from the text embeddings. The VAE decoder then processes the denoised vector in the latent space into an image in the pixel space.
Consider the sizes of the four models used by the FLUX pipeline. The Clip text encoder, the T5 text encoder, the diffusion transformer, and the VAE models are 246 MB, 9.52 GB, 23.8 GB, and 168 MB, respectively, totaling 33.734 GB for an FP16 model.
Due to the large size of the models, we cannot directly run the pipeline on RTX GPUs with VRAM lower than 24 GB. This is addressed using the low-vram mode, which loads the models on demand and unloads them after performing inference. Since the models run sequentially, we can bring the GPU memory usage down significantly. The following table shows the GPU memory savings using the low-vram mode for different precisions.
| Precision | Default mode | With low-vram |
|---|---|---|
| FP16 | 39.3 GB | 23.9 GB |
| BF16 | 35.7 GB | 23.9 GB |
| FP8 | 24.6 GB | 14.9 GB |
| FP4 | 21.67 GB | 11.1 GB |
In addition to accelerating the standard dev pipeline with FP4, demoDiffusion also offers ways to control the image generation process by providing structural cues in the form of edge or depth maps using the FLUX ControlNet pipelines, namely depth and canny. Users can preserve image composition by providing edge (canny) or depth maps and the text prompt to guide the image generation process. The ControlNet pipeline differs from the standard dev pipeline in the architecture of the Diffusion Transformer, which takes an additional input in the form of the Control image to perform denoising with both text and image information. FP8 calibration datasets for depth and canny control nets are on GitHub.


Try TensorRT 10.8 demoDiffusion to run FLUX.1-Dev and FLUX.1-Schnell models with peak FP4 performance.
ComfyUI integration
The popular image-generation tool, ComfyUI, now provides support for running on Blackwell GPUs. Additionally, to streamline the adoption of low-precision inference, dedicated NVIDIA NIM inference microservices offer an easy-to-use solution for integrating with ComfyUI through custom nodes.
By using the custom NVIDIA NIM nodes, users can use the high-quality FLUX pipeline for image generation while benefiting from optimized TensorRT engines designed to run efficiently on consumer desktops.

A dedicated blueprint shows how to set up a ComfyUI workflow for text-to-image generation using the FLUX NIM. To simplify the process, a NIM installer is provided, facilitating the setup of the WSL2 environment and NIM deployment. The final product enables users to generate high-quality images using FLUX engines in FP4. Additionally, users have greater control over the final output with depth and canny map guidance for enhanced image precision.
Get started
In this post, we saw how a state-of-the-art model underwent multiple steps of optimizations through our software toolchain of quantizer, compiler, and runtime to leverage our latest 4-bit hardware innovation. This brings the power of generative AI beyond the cloud right to your desktop or workstation. If you are an owner of a brand new 50 series RTX GPU, try out the entire pipeline using TensorRT demoDiffusion.