
While speech AI is used to build digital assistants and voice agents, its impact extends far beyond these applications. Core technologies like text-to-speech (TTS) and automatic speech recognition (ASR) are driving innovation across industries. They’re enabling real-time translation, powering interactive digital humans, and even helping restore speech for individuals who’ve lost their voices. As these capabilities mature, they’re fundamentally reshaping how people communicate, learn, and connect.
NVIDIA Riva is a suite of multilingual microservices for building real-time speech AI pipelines. Riva delivers top-notch accuracy in TTS, ASR, and neural machine translation (NMT), and works across on-prem, cloud, edge, and embedded devices.
TTS, also called speech synthesis, converts text into high-quality, natural-sounding speech. It has been a challenging task in the field of speech AI for decades. This post introduces three state-of-the-art Riva TTS models—the latest TTS models from NVIDIA—that make significant contributions to this task:
- Magpie TTS Multilingual can significantly enhance voice naturalness and pronunciation accuracy.
- Magpie TTS Zeroshot enables voice cloning from just a few seconds voice samples.
- Magpie TTS Flow is ideal for studio dubbing and podcast narration.
| Model | Architecture | Use cases | Supported languages | Technical details |
| Magpie TTS Multilingual | Streaming Encoder-Decoder Transformer | –Voice AI agents –Digital humans –Multilingual interactive voice response (IVR) –Audiobooks | English, Spanish, French, German | –Latency with NVIDIA Dynamo-Triton: <200 ms –Optimized for text adherence using preference alignment framework and classifier-free guidance (CFG) |
| Magpie TTS Zeroshot | Streaming Encoder-Decoder Transformer | –Live telephony –Gaming nonplayer characters (NPCs) | English | –Latency with NVIDIA Dynamo-Triton: <200 ms –Optimized for text adherence using preference alignment framework and classifier-free guidance (CFG) –5-second voice sample used for voice cloning |
| Magpie TTS Flow | Offline flow matching decoder | –Studio dubbing –Podcast narration | English | –Model text-speech alignment and speech characterization –3-second voice sample used for voice cloning |
Streaming encoder-decoder transformer
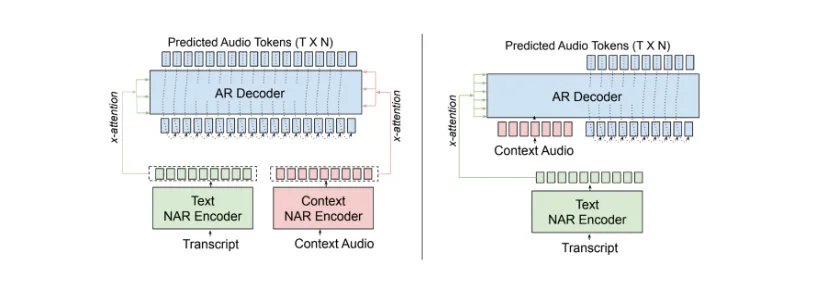
The Magpie TTS Multilingual and Magpie TTS Zeroshot models build on an encoder-decoder transformer architecture to target streaming applications. The encoder is a non-autoregressive (NAR) transformer, and the decoder is an autoregressive (AR) transformer that cross-attends to the encoder. The input to the model includes tokenized text and a context audio: acoustic codes from a target speaker’s reference audio. The output of the model is the generated acoustic tokens of the target speaker. The two models are built on different variants of the encoder-decoder architecture:
- Magpie TTS Multilingual: Uses a multi-encoder setup. A dedicated context encoder processes context audio tokens. The context and text encoder outputs are fed into different layers of the AR decoder. This allows for clear separation of modalities.
- Magpie TTS Zeroshot: Employs a decoder context setup, utilizing the decoder’s self-attention mechanism for speaker conditioning. It feeds context audio tokens into the AR decoder, which then processes both the context and target audio tokens. This approach uses a shared representation for both conditioning and prediction.
Both models use a novel preference alignment framework and classifier-free guidance (CFG) to address persistent issues. These issues include where the AI generates, interprets, or outputs false or misleading audio, or produces unwanted vocalizations, especially when the input text contains repeated tokens.
- Preference alignment: The framework generates multiple outputs for challenging text and context audio prompts, then evaluates key metrics using ASR and speaker verification (SV) models within a reward system to create a preference dataset. It applies Direct Preference Optimization (DPO) to guide the TTS model to produce more desirable outputs.
- CFG: During inference, the model generates two speech outputs for each synthesis: one conditioned on the input text and context audio, and one without these conditions. The final output is a combination that moves away from the unconditioned result, improving adherence to the input and overall audio quality.
Compared to other open source models, these NVIDIA models deliver the lowest character error rate (CER) and word error rate (WER), despite being trained on much less data. In human evaluations, they also achieve the highest scores for naturalness (MOS) and speaker similarity (SMOS).
You can find the voice names and emotions the models currently support in the pretrained TTS models documentation. Due to rigorous human evaluation standards, a broader range of emotions is currently supported for female voices than male voices. This is because emotions are only released when at least 50% of evaluators consistently identify them in audio samples. As a result, some emotions have met this threshold for female voices sooner, reflecting differences in evaluation outcomes rather than technical limitations.
You can synthesize the voices of target speakers who have consented to such use, using a five-second audio sample with Magpie TTS Zeroshot. You can also create your own pipeline using the components shown in Figure 2.

The input for this pipeline has two parts: a user prompt, and a target speaker’s audio prompt. An LLM hosted by NVIDIA LLM NIM generates random text for TTS tasks based on a user prompt. The Magpie TTS Zeroshot model takes the text and audio prompt as input, then generates the corresponding audio of the input text with the target speaker’s voice.
Magpie TTS Flow
The Magpie TTS Flow model introduces an alignment-aware pretraining framework that integrates discrete speech units (HuBERT) into an NAR training framework (E2 TTS) to learn text-speech alignment. E2 TTS employs a flow-matching decoder to jointly model text-speech alignment and acoustic characteristics, achieving natural prosodic output. A key limitation of E2 TTS is its dependence on large transcribed datasets, which are often scarce for low-resource languages.
To address this data constraint, Magpie TTS Flow integrates alignment learning directly into the pretraining process using untranscribed speech data, without the need for separate alignment mechanisms. By embedding alignment learning into pretraining, it facilitates alignment-free voice conversion and allows for faster convergence during fine-tuning even with limited transcribed data.
As shown in Figure 3, before pretraining, the waveform of the audio is converted into discrete units by HuBERT. During pretraining, discrete speech unit sequences are concatenated with masked speech, allowing the model to learn unit-speech alignment. In the fine-tuning stage, text sequences from transcribed data and masked target reference speech are concatenated, then passed as input to the model to generate the audio of the target speaker.

The HuBERT model takes a speech waveform from untranscribed data as input, then generates a 50 Hz discrete unit sequence, which is a sequence of indices ranging from 0 to K-1, where K is the number of clusters in the k-means quantizer. Then the repeated indices for continuous speech segments are removed to eliminate the duration information, which gives it the flexibility to perform voice cloning with varied alignment for target speakers.
During pretraining, the deduplicated units can be used to guide the inpainting of the masked speech and help the model learn to extract speaker-specific and acoustic characteristics. The discrete units u are padded with filler tokens F to match the length of the mel-spectrogram x. The padded sequence uPAD is concatenated with masked speech xmask, as input to the model to predict the masked region. The flow matching decoder is trained to inpaint the masked regions using the surrounding context based on the modified CFM loss. The decoder has a hidden size of 1024, 16 attention heads, and a total of 24 transformer layers, resulting in 450 million parameters.
For fine-tuning, the unit sequences are replaced with text embeddings from transcribed data. Text sequences (padded with filler tokens) and masked target reference speech are concatenated, input to the model to generate the audio of the target speaker.
Magpie TTS Flow can achieve high pronunciation accuracy (lower WER) and higher speaker similarity (SECS-O) with significantly fewer pretraining and fine-tuning iterations compared to other models. Furthermore, it can also learn text-speech alignment effectively for multiple languages by adding language ID as an input to the decoder, making it a robust multilingual TTS system. While the paper linked above demonstrates strong performance using less than 1K hours of paired data to highlight the efficiency of the unit-based pretraining method, the released Riva model was trained on a significantly larger paired dataset (about 70K hours) to further improve zero-shot performance.
You can synthesize the voices of target speakers who have consented to such use, using a five-second audio sample with Magpie TTS Flow (Figure 4). The input to this pipeline has three parts: user prompt, target speaker’s audio prompt, and audio prompt transcript. An LLM hosted by NVIDIA LLM NIM generates random text for TTS tasks based on user prompt. Magpie TTS Flow takes the inputs, then generates the corresponding audio of the input text with the target speaker’s voice.

Safety collaborations
As part of the NVIDIA Trustworthy AI initiative, the safe and responsible advancement of speech AI is prioritized. To address the risks of synthetic speech, NVIDIA collaborates with leading deepfake and voice detection companies, such as Pindrop, providing early access to models like Riva Magpie TTS Zeroshot.
Pindrop technology is trusted in a wide range of industries, from banking and financial services, to large-scale contact centers, retail, utilities, and insurance, delivering real-time voice authentication and deepfake detection to protect against fraud and impersonation in critical interactions. Our collaborations in deepfake detection set an important standard for secure synthetic speech deployment and address critical risks in areas such as call centers and media integrity, ensuring responsible AI advancement.
Get started with NVIDIA Riva Magpie TTS models
NVIDIA Riva Magpie TTS models are setting new standards for real-time, natural, and speaker-adaptive speech synthesis. Featuring multilingual capabilities, zero-shot voice characterization, and advanced preference alignment, Riva Magpie TTS models produce expressive, accurate, and highly natural audio that adapts to both the speaker and the content.
With flexible architecture and strong performance, demonstrated by low word error rates across multiple languages, Riva Magpie TTS provides ideal models for healthcare, accessibility, and any application requiring lifelike, real-time voice interaction.
To get started with Riva Magpie TTS models:
- Try NVIDIA NIM microservices
- Follow the Riva Quick Start Guide – Speech Synthesis to download a Docker container from NVIDIA NGC
- Request access to the Magpie TTS Zeroshot and Magpie TTS Flow, both zero-shot models
- Learn how you can operationalize these capabilities securely and at scale across your organization with NVIDIA AI Enterprise










