As AI workloads scale, fast and reliable GPU communication becomes vital, not just for training, but increasingly for inference at scale. The NVIDIA Collective Communications Library (NCCL) delivers high-performance, topology-aware collective operations: AllReduce, Broadcast, Reduce, AllGather, and ReduceScatter optimized for NVIDIA GPUs and a variety of interconnects including PCIe, NVLink, Ethernet (RoCE), and InfiniBand (IB).
With its single-kernel implementation of communication and computation, NCCL ensures low-latency synchronization, making it ideal for both distributed training and real-time inference scenarios. Developers can scale across nodes without tuning for specific hardware configurations, thanks to the NCCL dynamic topology detection and streamlined C-based API.
This post introduces the latest NCCL 2.27 release, showcasing features that enhance inference latency, training resilience, and developer observability. To learn more and get started, check out the NVIDIA/nccl GitHub repo.
Unlocking new performance levels
NCCL 2.27 delivers critical updates that enhance collective communication across GPUs, addressing latency, bandwidth efficiency, and scaling challenges. These improvements support both training and inference, aligning with the evolving needs of modern AI infrastructure—where ultra-low latency is essential for real-time inference pipelines, and robust fault tolerance is required to keep large-scale deployments running reliably.
Key release highlights include low-latency kernels with symmetric memory, direct NIC support, and NVLink and InfiniBand SHARP support.
Low-latency kernels with symmetric memory
This release introduces symmetric memory support, allowing buffers with identical virtual addresses across GPUs to benefit from optimized collective operations. These kernels significantly reduce latency for all message sizes, resulting in up to 7.6x reduction in latency for small message sizes as shown in Figure 1.
AllReduce latency improvement from version 2.26 to 2.27 using NVIDIA GB200 with 32 ranksReductions are computed using FP32 accumulators (or FP16 for FP8 on NVLink Switch (NVLS) Systems), improving both accuracy and determinism in operations like AllReduce, AllGather, and ReduceScatter.
Symmetric Memory is supported for NVLink communication within a single NVLink domain—up to NVL72 (72 GPUs) in NVIDIA GB200 and GB300 systems or NVL8 (8 GPUs) in NVIDIA DGX and HGX systems. Even on NVL8 domains, developers can see up to 2.5x higher performance for small to medium message sizes. For testing guidance, check out the NCCL-Test repository.
Direct NIC support
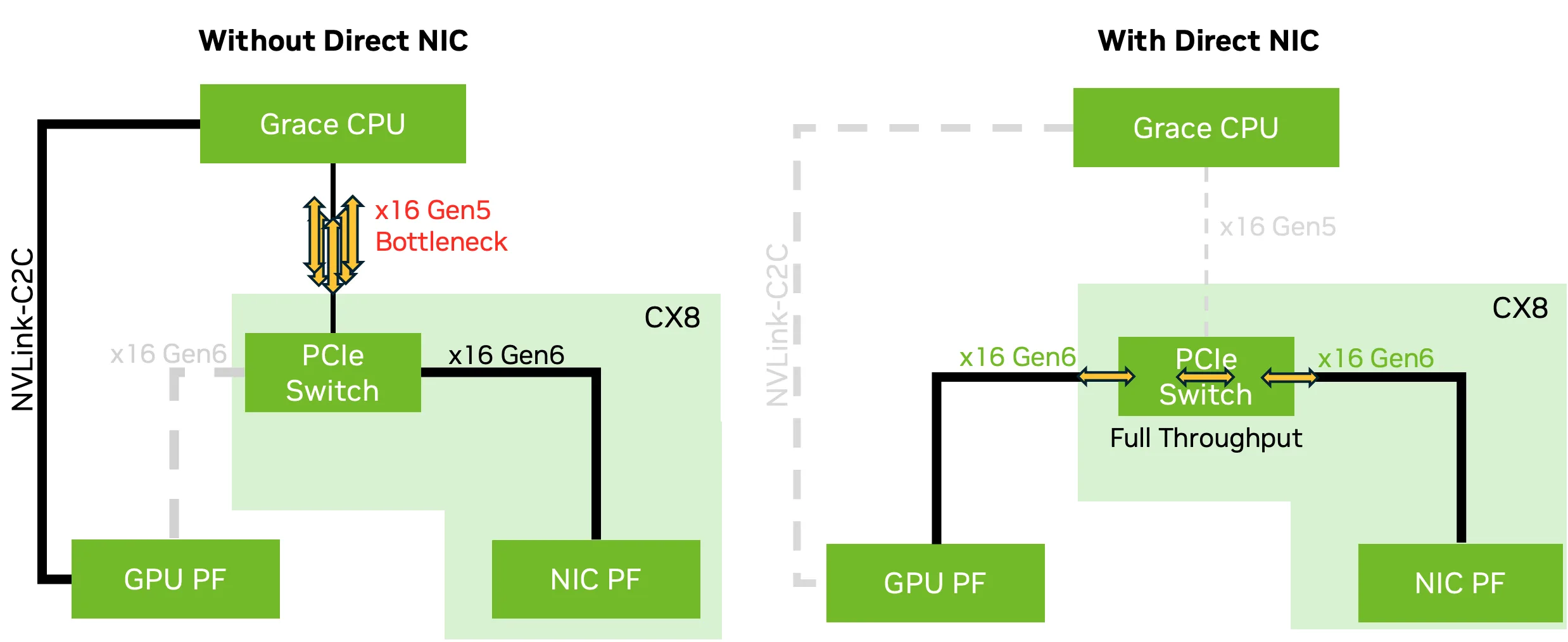
NCCL 2.27 introduces support for Direct NIC configurations to unlock full network bandwidth for GPU scale-out communication. On select NVIDIA Grace Blackwell platforms, components such as CX8 NICs and NVIDIA Blackwell GPUs support PCIe Gen6 x16, which can deliver up to 800 Gb/s of network bandwidth. However, Grace CPUs currently only support PCIe Gen5, which limits throughput to 400 Gb/s.
To address this, the CX8 NIC exposes two virtual PCIe trees: on one tree, as shown in Figure 2, the NVIDIA CX8 NIC data direct function (PF) directly connects to the GPU PF through PCIe Gen6 x16 links, bypassing the CPU and avoiding bandwidth bottlenecks. On the other tree, the regular NIC PF connects to the CPU root port.
This configuration ensures that GPUDirect RDMA and related technologies can achieve full 800 Gb/s bandwidth without saturating the CPU to GPU bandwidth, which is particularly important when multiple GPUs share a single CPU. Direct NIC is key to enabling full-speed networking for high-throughput inference and training workloads.
NVLink and InfiniBand SHARP support
NCCL 2.27 adds support for SHARP (Scalable Hierarchical Aggregation and Reduction Protocol) for both NVLink and IB fabrics. SHARP enables in-network reduction operations that offload compute-intensive tasks. This new version brings SHARP support to AllGather (AG) and ReduceScatter (RS) collectives, from the GPU to the network when using NVLink Sharp plus IB Sharp.
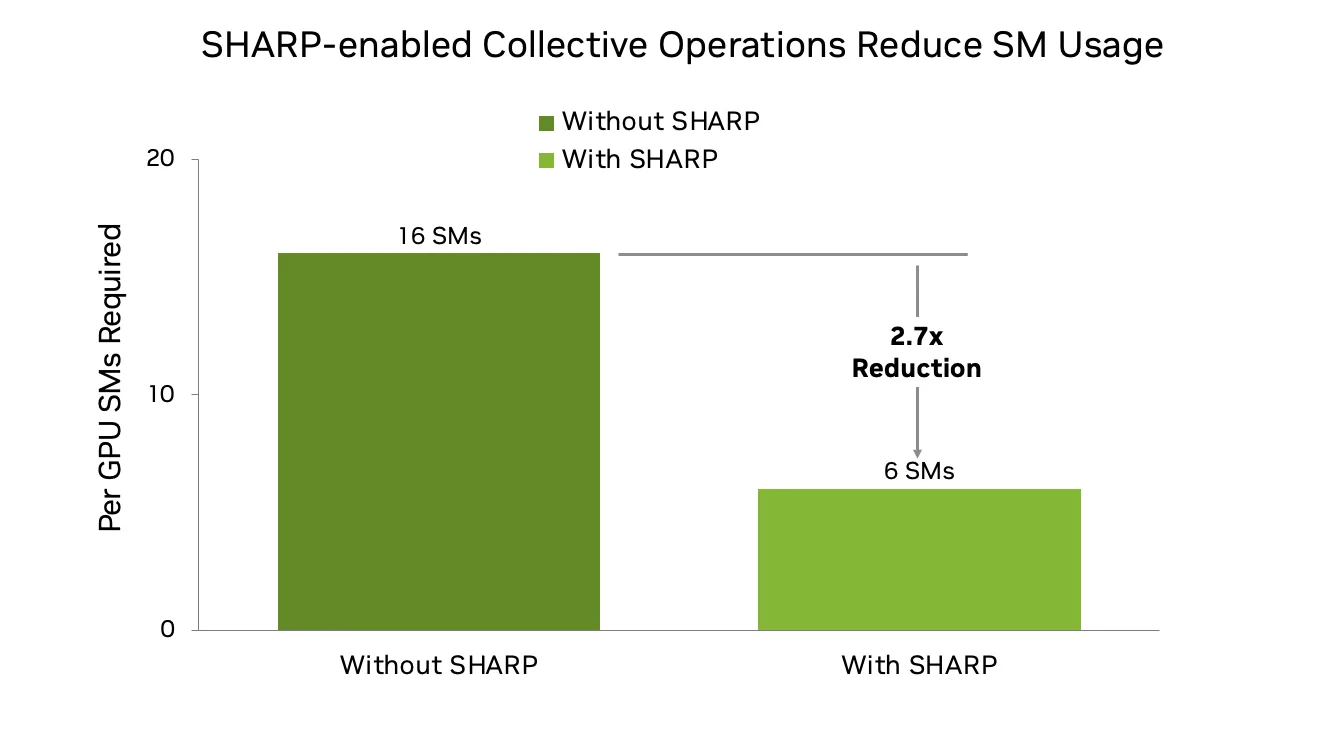
This is particularly beneficial for large-scale LLM training, where AG and RS are now preferred over AllReduce for better overlap between compute and communication. Traditional ring-based implementations can consume 16 or more SMs, but with NVLink and IB SHARP, this demand is reduced to 6 SMs or fewer, freeing up resources for model computation and boosting overall training efficiency. The result is improved scalability and performance at the 1,000 GPU level and beyond.
Enhancing resilience in large-scale training with NCCL Shrink
NCCL 2.27 introduces Communicator Shrink, a feature designed to make distributed training more robust, flexible, and efficient. Training jobs running across hundreds or thousands of GPUs are susceptible to device failures. Communicator Shrink enables dynamic exclusion of failed or unnecessary GPUs during training. This feature supports two operational modes:
- Default mode: Used for planned reconfiguration, allowing modification of the device topology while ensuring all operations are completed.
- Error mode: Automatically aborts ongoing operations to recover from unexpected device failures.
NCCL Shrink empowers developers to:
- Maintain uninterrupted training by dynamically rebuilding communicators.
- Reuse resources where possible through configurable resource sharing.
- Handle device failures gracefully with minimal disruption.
Example usage of NCCL Shrink for planned reconfiguration and error recovery scenarios:
// Planned reconfiguration: exclude a rank during normal operationNCCLCHECK(ncclGroupStart());for (int i = 0; i < nGpus; i++) { if (i != excludedRank) { NCCLCHECK(ncclCommShrink( comm[i], &excludeRank, 1, &newcomm[i], NULL, NCCL_SHRINK_DEFAULT)); }}NCCLCHECK(ncclGroupEnd());// Error recovery: exclude a rank after a device failureNCCLCHECK(ncclGroupStart());for (int i = 0; i < nGpus; i++) { if (i != excludedRank) { NCCLCHECK(ncclCommShrink( comm[i], &excludeRank, 1, &newcomm[i], NULL, NCCL_SHRINK_ABORT)); }}NCCLCHECK(ncclGroupEnd()); |
More features for developers
Additional features in this release for developers include symmetric memory APIs and enhanced profiling.
Symmetric memory APIs
Symmetric memory is a foundational capability in NCCL 2.27 that enables high-performance, low-latency collective operations. When memory buffers are allocated at identical virtual addresses across all ranks, NCCL can execute optimized kernels that reduce synchronization overhead and improve bandwidth efficiency.
To support this, NCCL introduces a window API for collective registration of symmetric memory:
ncclCommWindowRegister(ncclComm_t comm, void* buff, size_t size, ncclWindow_t* win, int winFlags);ncclCommWindowDeregister(ncclComm_t comm, ncclWindow_t win); |
ncclCommWindowRegisterregisters user-allocated memory with the NCCL communicator. Memory must be allocated using the CUDA Virtual Memory Management (VMM) API.winFlagsmust includeNCCL_WIN_COLL_SYMMETRICto enable symmetric kernel optimizations.- All ranks must provide buffers with matching offsets to ensure symmetric addressing.
- Deregistration (
ncclCommWindowDeregister) is a local operation and should only occur after all relevant collectives have completed.
ncclCommWindowRegister is collective and blocking, which means that when multiple GPUs are managed by a single thread, they must be enclosed within ncclGroupStart and ncclGroupEnd.
If symmetric memory is not desired, users can disable the feature entirely by setting NCCL_WIN_ENABLE=0.
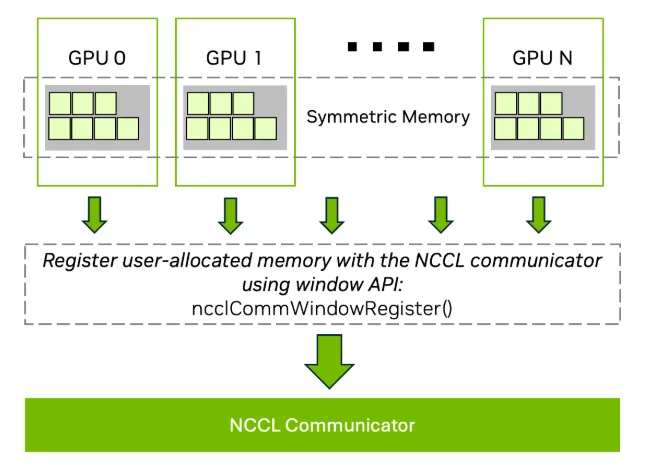
Figure 4 shows how symmetric memory is registered across multiple GPUs using the NCCL window API. By aligning virtual addresses, NCCL enables optimized low-latency kernels that improve performance for collective operations.
Enhanced profiling
NCCL 2.27 introduces a suite of enhancements to its profiling infrastructure, providing developers and tools with more accurate and efficient instrumentation for diagnosing communication performance.
Harmonization of proxy events
Previously, NCCL exposed both ncclProfileProxyOp and ncclProfileProxyStep events to track the progress of the network proxy thread. While these events provided different levels of granularity, they also duplicated many instrumentation points. In version 2.27, NCCL simplifies and streamlines this model by removing redundant ProxyOp states and introducing a unified ncclProfilerProxyOpInProgress_v4 state. This reduces profiler overhead without sacrificing detail, and enhances clarity when tracking communication progress.
Additionally, a new ProxyStep event state: ncclProfilerProxyStepPeerWait_v4, has been introduced to reflect the time a sender rank waits for a receiver to post a clear-to-send signal, integrating previous functionality while minimizing duplication.
GPU kernel event accuracy
To improve timing accuracy, NCCL now supports native GPU timestamp propagation. Instead of relying on host-side event timing through GPU work counters, an approach vulnerable to latency artifacts (delayed or collapsed kernels, for example), the GPU now records and exports start and stop timestamps using its internal global timer. This enables profiler tools to obtain precise kernel runtime durations directly from the GPU, though developers converting timestamps to CPU time will need to apply calibration or interpolation.
Network plugin event updates
The NCCL profiler interface now supports recordEventState for network-defined events. This new mechanism allows the profiler to update the state of ongoing operations, which is useful for injecting real-time network feedback into performance timelines such as retransmission signals or congestion cues.
Additional enhancements
- Profiler initialization: NCCL now reports communicator metadata including name, ID, node count, rank count, and debug level during profiler initialization.
- Channel reporting: The number of channels reported reflects actual usage instead of theoretical limits. This includes point-to-point (P2P) operations.
- Communicator tagging:
ncclConfig_thas been extended to include communicator names, improving correlation between profiled operations and specific communicators.
These updates collectively raise the fidelity of the NCCL profiler plugin interface, equipping developers with deeper insight into network dynamics, GPU timing, and operational structure, all essential for diagnosing and tuning large-scale AI workloads.
More information on the NCCL Profiler Plugin can be found on the NVIDIA/nccl GitHub repo.
Forward-looking support
Forward-looking support includes:
- Cross-data center communication: Early support allows for collective operations across geographically distributed data centers.
- Multi-NIC plugin visibility: Enables simultaneous utilization of multiple network configurations.
Get started with NCCL 2.27
Explore the new capabilities in NCCL 2.27 and elevate your distributed inference and training workflows with lower latency, greater fault tolerance, and deeper observability.
For detailed documentation and source code, and getting the support you need, visit the NVIDIA/nccl GitHub repo. To learn more about configuring NCCL for your architecture, see the NCCL documentation.