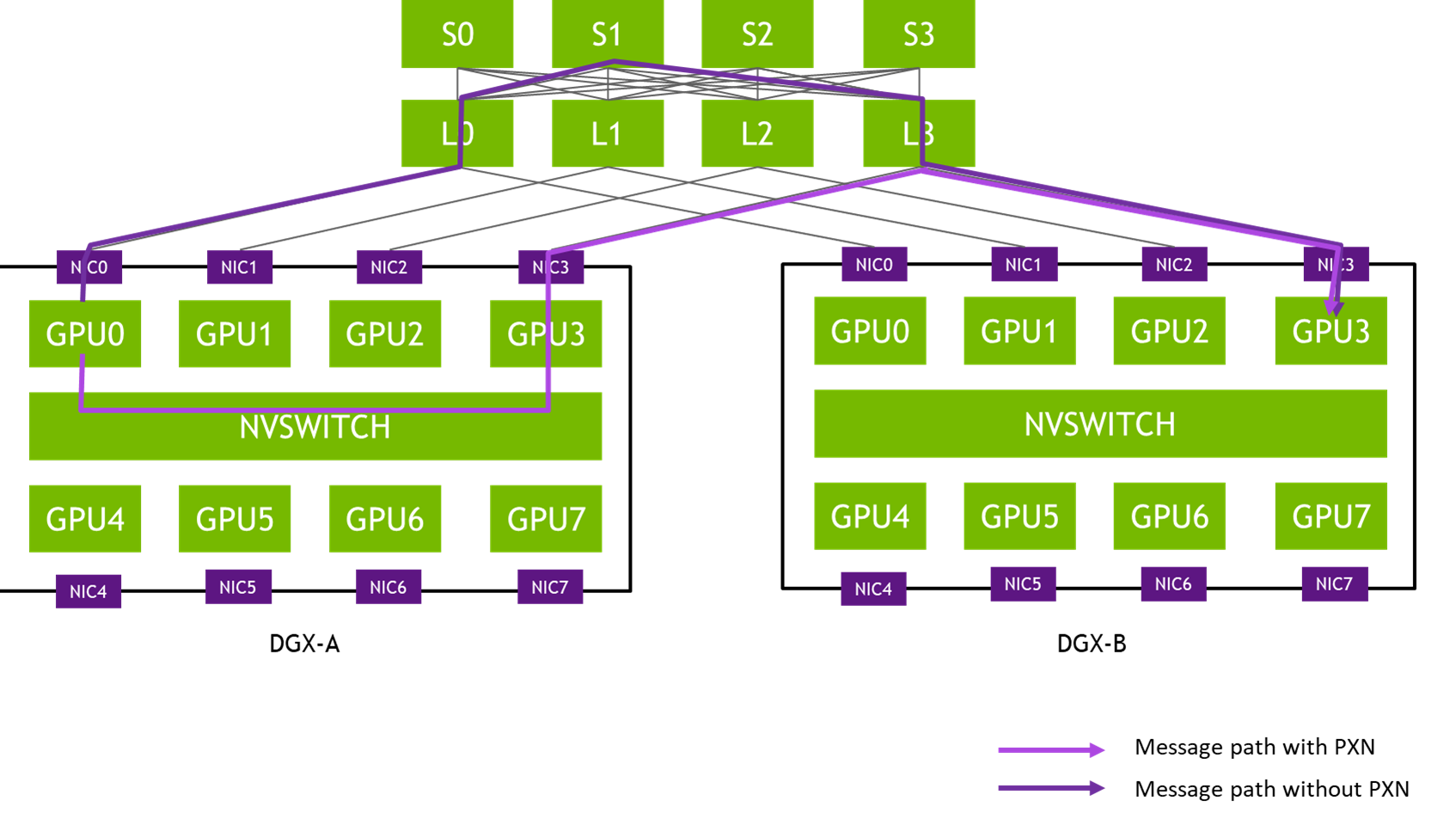
High-performance computing and deep learning workloads are extremely sensitive to latency. Packet loss forces retransmission or stalls in the communication pipeline, which directly increases latency and disrupts the synchronization between GPUs. This can degrade the performance of collective operations such as all-reduce or broadcast, where every GPU’s participation is required before progressing.
The focus of this post is NVIDIA Ethernet-based East-West AI fabric solution, Spectrum-X. I discuss resiliency in AI fabrics and consequences of link flaps, link failures in the perspective of AI workloads, and the NVIDIA Collective Communication Library (NCCL).
Packet-drop sensitivity
NCCL is designed for high-speed and low-latency environments, often through lossless RDMA-capable networks such as Infiniband, NVLink, or Spectrum-X for Ethernet. Its performance can be significantly impacted by network events:
- Delay and jitter: NCCL’s collective operations rely on tight synchronization between GPUs. High delay or jitter can disrupt this timing and reduce overall efficiency and AI workload performance.
- Packet loss and timeouts: NCCL typically assumes a reliable (lossless) transport layer and does not implement heavy error recovery mechanisms. Packet loss or timeouts can lead to communication errors, degraded performance, or interruptions in NCCL operations.
For optimal performance, NCCL should be run over networks with minimal delay, jitter, and packet loss.
Spectrum-X has a highly efficient congestion control mechanism (SPCX-CC), so the most typical source of packet loss is subsequently phy-related (for example link-failure and link-flap) events.
Link failures and link flaps are typically caused by external factors beyond the control of data-plane and control-plane functionalities. They are often due to environmental conditions. In a recent publication, Google has reported a daily link failure rate of 0.004%, due to reasons like optics firmware issues to component level problems. This translates to 40 failures per day on a 1M link cluster (meaning the AI fabric would experience some kind of interruption almost twice an hour, on average), or one failure every day for a cluster with 25K links. This issue needs to be handled by the AI fabric in a way that link interruptions would not affect AI workloads or effect in a minimal and deterministic manner.
Thanks to Spectrum-X congestion control, you can avoid packet drops caused by queueing and congestion in a lossless fabric. However, you can’t avoid packet drops due to an interface going down or even worse, flapping. The impacts of such drops on AI workloads and NCCL collectives can be severe.
NCCL relies on custom communication protocols that assume near-perfect, reliable data transmission. Unlike protocols that use robust error correction or retransmission strategies (for example, TCP), the NCCL design expects minimal packet loss to maintain high performance. Even small numbers of lost packets can trigger delays as the system must wait for error recovery, reducing overall throughput and time to train your LLM.
NCCL also often employs streaming aggregation and pipelined communication to maximize bandwidth utilization. Packet loss interrupts this smooth data flow. When a packet is lost, the entire pipeline can be stalled until recovery mechanisms kick in, reducing the benefits of pipelining and resulting in a significant drop in effective throughput.
NCCL is typically deployed over high-performance datacenter fabrics (for example, NVLink, InfiniBand, and Ethernet based Spectrum-X) that have low packet loss rates.
To achieve this, its communication routines are streamlined, with minimal error checking and recovery overhead.
This works great when packet loss is nearly zero, but if a packet is dropped, there aren’t many built-in redundancies to quickly correct it. When used over networks with higher packet loss (like traditional Ethernet networks) or in an environment where packet loss is unavoidable due to link-flaps, the system may encounter unexpected retransmissions, which were not anticipated in the NCCL design, leading to disproportionate performance degradation.
In summary, the NCCL sensitivity to packet loss comes from its reliance on tightly coupled, low-latency communication protocols and optimized data streaming strategies. Even minor packet losses can disrupt synchronization, force retransmissions, and cause significant performance drops, making reliable, high-quality network conditions essential for achieving NCCL high performance.
More resiliency for AI datacenter fabrics
In the case of an unavoidable packet loss event, such as link failure or link flap, you must make sure that the time it takes for the network to converge is minimized and that the network is capable of converging in a consistent and deterministic manner, regardless of its scale and size. This is extremely important for the NCCL and AI workload point of view, as it affects the training time and how NCCL behaves based on each failure event.
According to the design of modern AI data center fabrics, to provide resiliency and convergence, Spectrum-X relies on powerful and scalable BGP and its capabilities. Events such as link failures create topology changes and cause the entire fabric to recalculate best paths and rebalancing equal-cost multi-path routing (ECMP) groups. However, the way BGP operates on the back-end can create situations that would hinder fast convergence goals of demanding AI fabrics.
As the GPU cluster size gets bigger with more GPUs, BGP Routing Information Base (RIB) and routing tables also grow. The way BGP was originally designed enforces BGP to recalculate the best path for each prefix and such information needs to be propagated across the fabric. Larger cluster size results in slower BGP convergence time and longer NCCL interruptions. As a result, AI workloads need longer time to finish and are not completed in a deterministic timeframe.
That is why mechanisms such as BGP Prefix Independent Convergence (PIC) are needed and can be used to provide the best convergence time for your AI fabric. BGP PIC was developed to pre-compute backup paths and enable faster recovery without waiting for each prefix to converge separately. The benefits of BGP PIC rely on the presence of more than one path to the destination in the form of either ECMP or precalculated backup paths.
Introduction to BGP PIC
Default BGP convergence is prefix-dependent, BGP inherently processes and updates each route on a per-prefix basis.
Here’s a deeper dive into why that is the case:
- Per-prefix route processing
- Independent decision-making
- Timers and propagation delays
- Scalability challenges
In essence, default BGP convergence is prefix-dependent because the protocol is designed to handle routing decisions, updates, and withdrawals on an individual prefix level. This design, while flexible and granular, leads to slower convergence when large numbers of prefixes are affected by network events.
Per-prefix route processing
BGP treats each network prefix as an independent route. When a change occurs—such as a link failure or policy update—BGP must individually evaluate and update the best path for each affected prefix.
If a failure impacts many prefixes, each one goes through its own convergence process.
Independent decision-making
BGP’s best-path selection algorithm runs separately for every prefix. Attributes such as local preference, AS path, and MED are evaluated on a per-prefix basis. There is no collective decision process that applies to groups of prefixes, which contributes to the prefix-dependent nature of convergence.
Timers and propagation delays
Mechanisms such as the Minimum Route Advertisement Interval (MRAI) timer are applied per prefix.
When routes are withdrawn or updated, each prefix may be subject to its own timer delays, further contributing to the overall convergence time as the number of prefixes increase.
Scalability challenges
Such behavior of BGP affects fabrics in all sizes, small and large. It creates undeterministic convergence in the fabric regardless of fabric size. Even in some smaller-scale AI fabrics (which correspond to IP prefixes in the BGP table), the need for individually processing each route can lead to significant delays. Such fabric issues are correlated with NCCL collectives and AI workloads. This causes LLM jobs to not finish in deterministic fashion, impacting AI performance at the workload level. This is why BGP PIC was developed to pre-compute backup paths and enable faster recovery without waiting for each prefix to converge separately.
Conclusion
BGP PIC introduces a novel solution to the resiliency problem in large-scale AI fabrics. It minimizes the convergence time of an extremely large-scale GPU cluster, down to a small-scale fabric, making prefix count independent from the convergence time. This makes NVIDIA Spectrum-X such a unique solution in the market.
BGP PIC and Spectrum-X make NCCL jobs and AI workloads much more resilient to link failures and flaps and deterministic in terms of time to train an LLM.
For more information, see the following resources: